hive项目之微博ETL项目总结分析
微博ETL项目分析
一、数据格式
文件格式
Txt
Csv’
Xls
Doc
数据结构格式
Html格式,既是一个文件格式,也是一个数据结构格式
Json格式:kv对
Xml格式:一个根标签,和一堆子标签
二、输入和输出
输入:
房地产评论主题下的对应的用户基本信息文件集和评论内容文件集,两者之间是通过用户id关联的。
通过一定的java程序设计做数据解析、结构化、各自合并成一个文件即可方便load到hive中。
输出:(两张表,一个用户表,一个评论内容表)
将两个类别下各自对应的文件集,进行解析、结构化。
通过load语法,将数据分别导入到两张表当中。
三、主要思路与考点
主要思路
通过javase+maven解决数据解析、结构化到一个文本文件的目标。
通过hive load语法将数据加载入数据仓库管理。
注意数据仓库的研发思路和开发步骤拆解,做到功能实现、目录清晰易懂。
主要考点
数据仓库的目录结构和开发规范
JavaSe程序设计基础
面向对象程序设计‘
Maven项目构建和开发
Xml数据解析
正则表达式
四、Hive项目之微博数据ETL项目
该项目标准流程
1、 项目概述
2、 需求分析
3、 开发步骤
4、 代码实现与风险控制
5、 Bug修复、调优、上线
流程落地
1、 项目概述
基于给定的微博用户和博文数据,经过javase解析、结构化、数据仓库ETL处理得到两张可以通过用户id进行关联的表。
2、 需求分析
可行性分析:一定是可行的。
前置条件
输入:单个微博数据目录,其中包含微博用户数据和博文数据两部分。
处理:JavaSe解析数据形成两个类型的结构化文件,然后通过ETL操作,加载到Hive表当中。
输出:通过SQL查询,给定任意的用户ID,得到其对应的个人信息和博文信息。
3、 开发步骤
1、 数据文件读取问题
2、 数据解析-用户数据解析,形成结构化数据。即java的对象形式。
3、 数据解析-博文数据解析,形成结构化数据,同上。
4、 将结构化数据落地到txt文件当中。
5、 将开发环境的结构化数据生成项目,部署到入口机上。
6、 将在入口机上生成的txt文件,进行hive仓库化操作。
1) 四大金刚结构。
2) 通过脚本化的方式解决方式,而不是直接使用hive cli模式。
7、代码实现与风险控制
1、数据文件读取问题
Java io
8、Bug修复、调优、上线
4、 代码实现与风险控制
5、 Bug修复、调优、上线
文件乱码剖析
乱码原因:编码和解码不是一个值,或者说不兼容。
如何解决:将编码和解码进行同一兼容。
抽象的层次说明
抽象方法
抽象类别
抽象项目
抽象系统
抽象方法的般步骤
成员方法的判断依据:如果该方法需要方法外部,类内部的某些依赖,则用成员方法,若无外部依赖,自己可独立使用,应该使用静态方法。
4.测试调优即可。
StringBuilder和StringBuffer的区别和联系
联系:可以做字符串拼接
区别:StringBuilder是线程不安全的,所以IO效率更高
StringBuffer是线程安全的。IO效率低
何为线程安全
方法可重入性:如果一个方法,不管什么时候、多少个线程去调用,都是安全的,不影响最终结果,则称为方法是可重入的。
关于正则表达式 javase这则处理核心类
Pattern:建立正则匹配模式引擎
Matcher:用于正则引擎匹配完数据源之后的匹配器 匹配模式
Matches:全量匹配
lookingAt:从头往后匹配
find:任意位置匹配均可以
五、将代码部署到生产环境:
四大金刚:udf、deal、create、config
找到代码maven install 打包
然后打开 xshell
Cd hive
Cd test
创建一个目录:
Mkdir weibo_data_etl
Cd weibo_data_etl
然后创建四个目录:
config
create
deal
udf
进入到udf中:cd udf
rz -bye WeiboDataStruct-jar-with-dependencies.jar
然后回到 deal目录:
Cd …/deal/
然后
rz -bye 房地产.zip
解压:
Unzip 房地产.zip
(改名字的命令:mv a b
如:mv 123 房地产:将123改名为房地产)
最后执行java -jar …/udf/WeiboDataStruct-jar-with-dependencies.jar fangdichan
查看文件中的内容命令:more 1580368313.txt
rm -rf fangdichan 删除这个
拷贝文件到本地目录sz 2322382161.txt
若执行使用java -cp的形式:java -cp …/udf/WeiboDataStruct-jar-with-dependencies.jar com.tl.job009.controller.SystemController fangdichan
在deal中,执行java -jar生成txt文件
在deal目录下 :touch prepare_4_weibo_data.sh
然后在deal目录下进入到 prepare_4_weibo_data.sh
vi prerare_4_weibo_data.sh
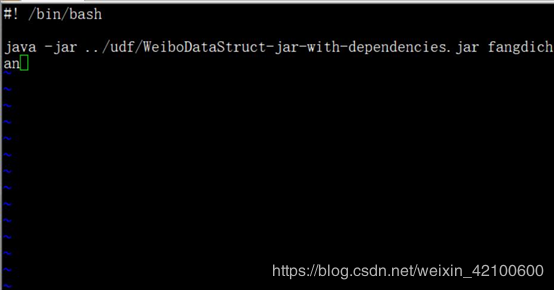
然后 sh prepare_4_weibo_data.sh
在create中创建数据表
cd …/create/:在create中创建表weibo_user_info.sh和weibo_content_info.sh。
touch weibo_user_info.sh。
编辑weibo_user_info.sh
Vi weibo_user_info.sh:
因为将外部数据导入表中的,所有一定是外表
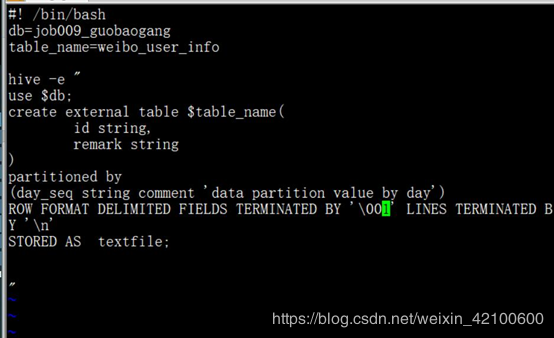
然后生成表:sh weibo_user_info.sh。
编辑weibo_content_info.sh
Vi weibo_content_info.sh
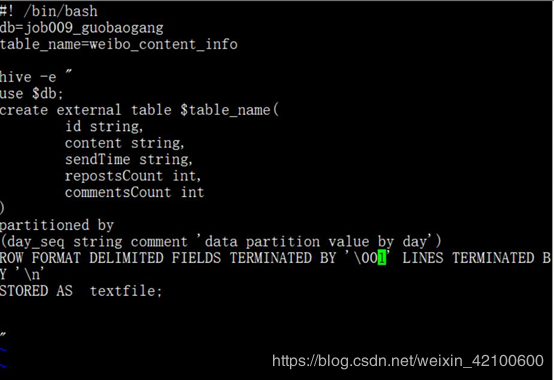
然后生成表:sh weibo_content_info.sh。
在deal中,将txt文件数据导入表中
在deal中创建:load_data_to_weibo_user_info.sh
touch load_data_to_weibo_user_info.sh
编辑:vi load_data_to_weibo_user_info.sh
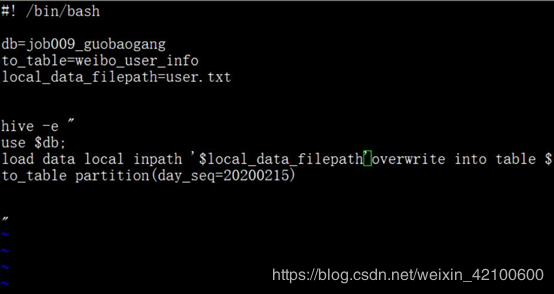
执行:
sh oad_data_to_weibo_user_info.sh。
在deal中创建:load_data_to_weibo_content_info.sh
touch load_data_to_weibo_content_info.sh
或者: cp load_data_to_weibo_user_info.sh load_data_to_weibo_content_info.sh
编辑:vi load_data_to_weibo_content_info.sh
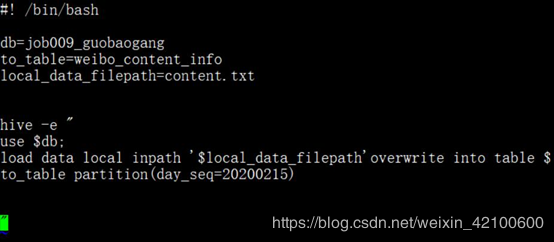
完成!!!
六、优化一下步骤
在create中创建一个入口
touch b_main.sh
vi b_main.sh
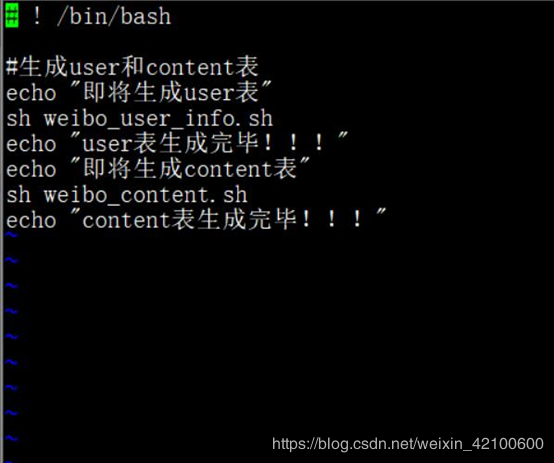
在deal中创建一个入口
touch a_main.sh
vi a_main.sh
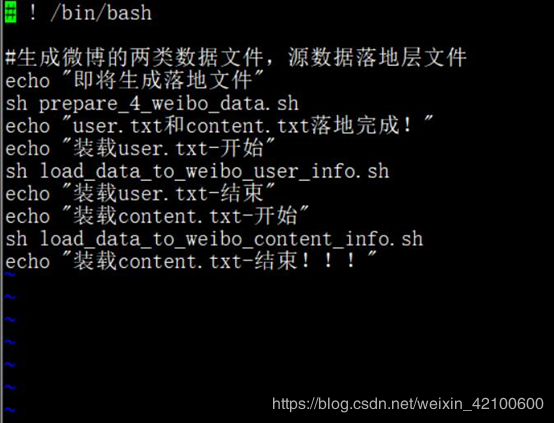
以后执行的时候,直接执行这两个入口就可以了。
先执行:sh b_main.sh
再执行: sh a_main.sh
七、注意事项:
1、乱码问题
建表后需要在hive中改变一下字符编码为GBK的形式,(因为传入的数据的格式为GBK格式的)
在hive中修改表的编码格式:alter table weibo_content_info set serdeproperties(‘serialization.encoding’=‘GBK’)
和
alter table weibo_user_info set serdeproperties(‘serialization.encoding’=‘GBK’)
然后改一下xshell属性—>终端—>编码为:utf-8;
然后导入数据
2、Dom4j解析xml对一些特殊符号的处理:

作者:小飞侠_JMH