Java超详细分析讲解哈希表
哈希表概念
哈希函数的构造
平均数取中法
折叠法
保留余数法
哈希冲突问题以及解决方法
开放地址法
再哈希函数法
公共溢出区法
链式地址法
哈希表的填充因子
代码实现
哈希函数
添加数据
删除数据
判断哈希表是否为空
遍历哈希表
获得哈希表已存键值对个数
哈希表概念散列表,又称为哈希表(Hash table),采用散列技术将记录存储在一块连续的存储空间中。
在散列表中,我们通过某个函数f,使得存储位置 = f(关键字),这样我们可以不需要比较关键字就可获得需要的记录的存储位置。
散列技术的记录之间不存在什么逻辑关系,它只与关键字有关联。因此,散列主要是面向查找的存储结构。
哈希函数的构造构造原则:
计算简单
散列函数的计算时间不应该超过其他查找技术与关键字比较的时间。
散列地址分布均匀
解决冲突最好的办法就是尽量让散列地址均匀地分布在存储空间中。
保证存储空间的有效利用,并减少为处理冲突而耗费的时间。
构造方法:
平均数取中法假设关键字是1234,那么它的平方就是1522756.在抽取中间的3位就是227,用作散列地址。再比如关键字4321,那么它的平方就是18671041,抽中间三位数就是671或710。平方去中法比较适合不知道关键字的分布,而位数又不是很多的情况。
折叠法折叠法是将关键字从左到右分割成位数相等的几部分(注意最后一部分位数不够时可以短一些),然后将这几部分叠加求和,并按散列表表长,取几位作为散列表地址。
比如我们的关键字是9 8 7 6 5 4 3 2 1 0,散列表表长为3位,我们将它分为四组,987|654|321|0,然后将他们叠加求和987+654+321+0=1962,再求后3位得到散列地址为962。
有时可能这还不能够保证分布均匀,不妨从一端向另一端来回折叠后对齐相加。比如我们将987和321反转,再与654和0相加,变成789+654+123+0=1566,此时散列地址为566。
折叠法事先不需要知道关键字的分布,适合关键字位数较多的情况。
保留余数法此方法为最常用的构造哈希函数的方法。
公式为:
f(key) = key mod p (p <= m)
代码如下:
public int hashFunc(int key){
return key % length;
}
哈希冲突问题以及解决方法
哈希冲突就是,两个不同的关键字,但是通过散列函数得出来的地址是一样的。
key1 ≠ key2,但是f(key1)= f(key2)
同义词
此时的key1 和key2就被称为这个散列函数的同义词
那可不行啊,一件单人间怎么可以住两个人呢?
别担心,这个问题自然已经被神通广大的大佬们解决了。
开放地址法开发定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只需要散列表足够大,空的散列地址总能找到,并将记录存入
再哈希函数法例子:
19 01 23 14 55 68 11 86 37
要存储在表长11的数组中,其中H(key)=key MOD 11
对于我们的哈希表来说,我们事先需要准备多个哈希函数。每当发生散列地址冲突时,就换一个哈希函数,总有一个哈希函数能够使关键字不聚集。
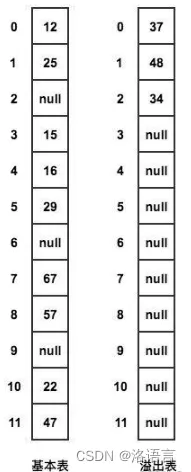
公共溢出区法在原先基础表的基础上再添加一个溢出表
当发生冲突时,就将该数据放到溢出表中
在查找时,对给定值通过散列函数计算出散列地址后,先与基本表的相应位置进行对比,如果相等就查找成功,如果不相等,则到溢出表进行顺序查找。
就时用链表将发生冲突的数据链起来,在查找时,只需要遍历链表即可,此方法也是最常用的方法。
如图:

填充因子就是 :填入表中的键值对个数 / 哈希表长度
填充因子标志着哈希表的装满程度,散列表的平均查找长度取决于填充因子,而不是取决于查找集合的键值对个数。Java中的HashMap默认初始容量为16,默认加载因子为0.75(当底层数组容量占用75%时,数组开始扩容,扩容后容量是原容量的二倍),此时虽然浪费了一定空间,但是换来的是查找效率的大大提升。
代码实现下面用链式地址法来实现哈希表。
public class HashTableDemo {
//哈希表每个位置链表的节点
class Node{
//关键字
int key;
String value;
Node next;
//无参构造
Node(){}
//有参构造
Node(int key, String value){
this.key = key;
this.value = value;
next = null;
}
//重写哈希表的equals()方法
public boolean equals(Node node){
if(this == node) return true;
else{
if(node == null) return false;
else{
return this.value == node.value && this.key == node.key;
}
}
}
}
//哈希表的长度
int length;
//哈希表存的键值对个数
int size;
//存储数据容器
Node table[];
//不指定初始化长度的无参构造
public HashTableDemo(){
length = 16;
size = 0;
table = new Node[length];
//为哈希表每一个位置初始化
for (int i = 0; i < length; i++) {
table[i] = new Node(i,null);
}
}
//指定初始化长度的有参构造
public HashTableDemo(int length){
this.length = length;
size = 0;
table = new Node[length];
for (int i = 0; i < length; i++) {
table[i] = new Node(i,null);
}
}
}
哈希函数
public int hashFunc(int key){
return key % length;
}
添加数据
思路:
先通过哈希函数算出该键值对在table中的位置。
遍历该处的链表的每一个节点,若发现某节点的key与传入的key相等,那么就更新此处的value。
若未发现相等的key,那么在链表末尾添加新的节点.
最后返回value。
代码如下:
public String put(int key, String value){
int index = hashFunc(key);
//保证cur2始终是cur的前一个节点。
Node cur = table[index].next;
Node cur2 = table[index];
while(cur != null){
if(cur.key == key){
cur.value = value;
return value;
}
cur = cur.next;
cur2 = cur2.next;
}
cur2.next = new Node(key, value);
size++;
return value;
}
删除数据
思路:
先通过哈希函数算出该键值对在table中的位置。
遍历该处的链表的每一个节点,若发现某节点的key与传入的key相等,那么就删除此节点,并返回它的value。
若未发现相等的key,返回null。
代码如下:
public String remove(int key){
int index = hashFunc(key);
Node cur = table[index];
while(cur.next != null){
if(cur.next.key == key){
size--;
String value = cur.next.value;
cur.next = cur.next.next;
return value;
}
cur = cur.next;
}
return null;
}
判断哈希表是否为空
思路:判断哈希表每个位置处的链表是否为空。
public boolean isEmpty(){
for(int i = 0; i < length; i++){
if(table[i].next != null)
return false;
}
return true;
}
遍历哈希表
public void print(){
for(int i = 0; i < length; i++){
Node cur = table[i];
System.out.printf("第%d条链表: ",i);
if(cur.next == null){
System.out.println("null");
continue;
}
cur = cur.next;
while(cur != null){
System.out.print(cur.key + "---"+ cur.value + " ");
cur = cur.next;
}
System.out.println();
}
}
获得哈希表已存键值对个数
//返回哈希表已存数据个数
public int size(){
return size;
}
到此这篇关于Java超详细分析讲解哈希表的文章就介绍到这了,更多相关Java哈希表内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!