Linux下安装Hadoop集群详细步骤
目录
1.在usr目录下创建Hadoop目录,将安装包导入目录中并解压文件
2.进入vim /etc/profile文件并编辑配置文件
3.使文件生效
4.进入Hadoop目录下
5.编辑配置文件
6.进入slaves添加主节点和从节点
7.将各个文件复制到其他虚拟机上
8.格式化hadoop (仅在主节点中进行操作)
9.回到Hadoop目录下(仅在主节点操作)
1.在usr目录下创建Hadoop目录,将安装包导入目录中并解压文件 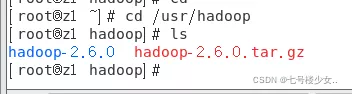
#hadoop
export HADOOP_HOME=/usr/hadoop/hadoop-2.6.0
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin
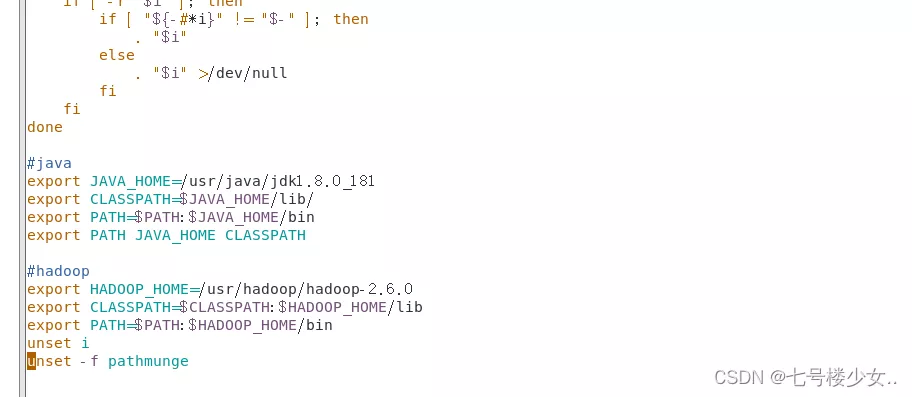
source /etc/profile

cd /usr/hadoop/hadoop-2.6.0/etc/hadoop

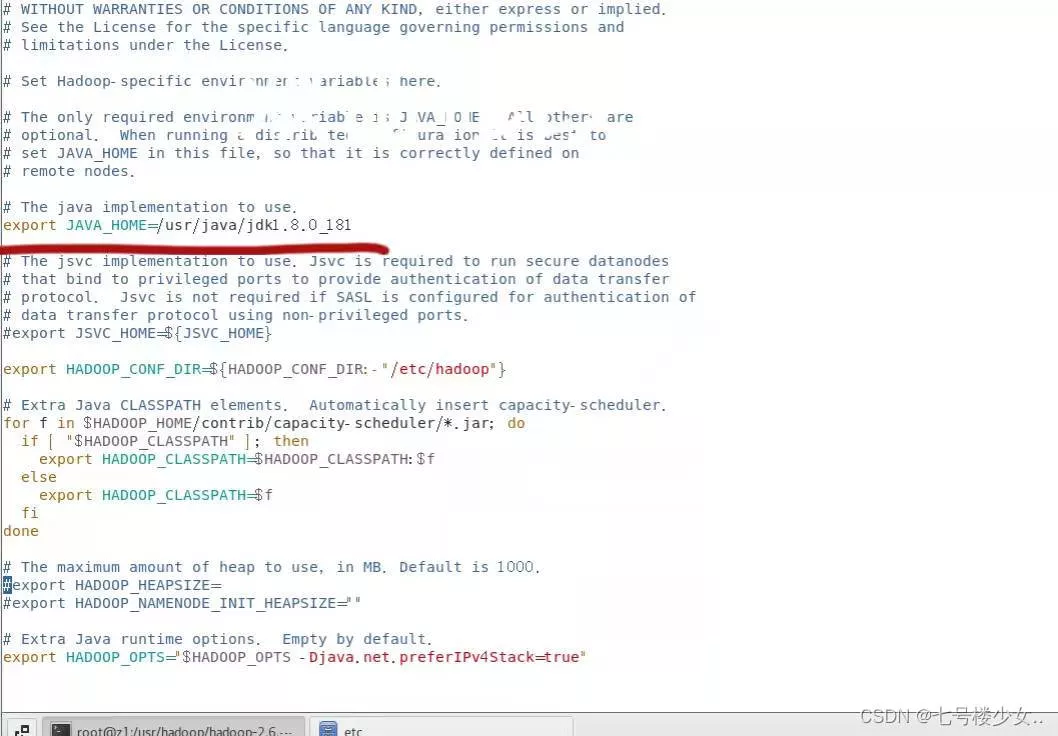
(1)进入vim hadoop-env.sh文件添加(java jdk文件所在位置)
export JAVA_HOME=/usr/java/jdk1.8.0_181
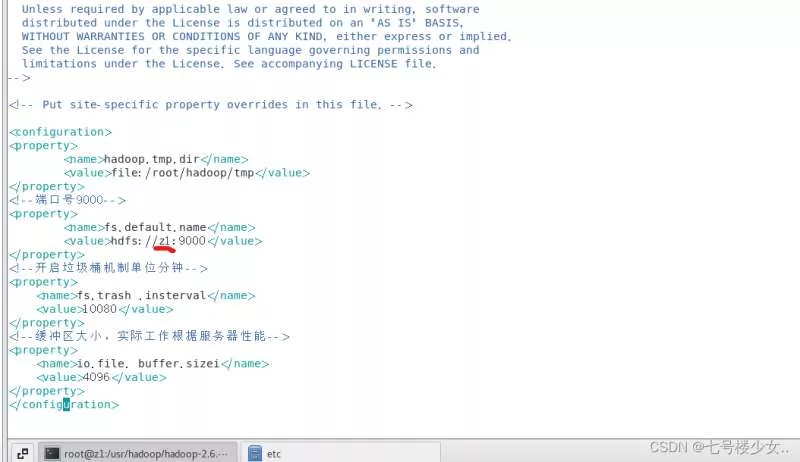
(2)进入 vim core-site.xml(z1:在主节点的ip或者映射名(改成自己的))
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/hadoop/tmp</value>
</property>
<!--端口号9000-->
<property>
<name>fs.default.name</name>
<value>hdfs://z1:9000</value>
</property>
<!--开启垃圾桶机制单位分钟-->
<property>
<name>fs.trash .insterval</name>
<value>10080</value>
</property>
<!--缓冲区大小,实际工作根据服务器性能-->
<property>
<name>io.file. buffer.sizei</name>
<value>4096</value>
</property>
</configuration>
39,9 底端
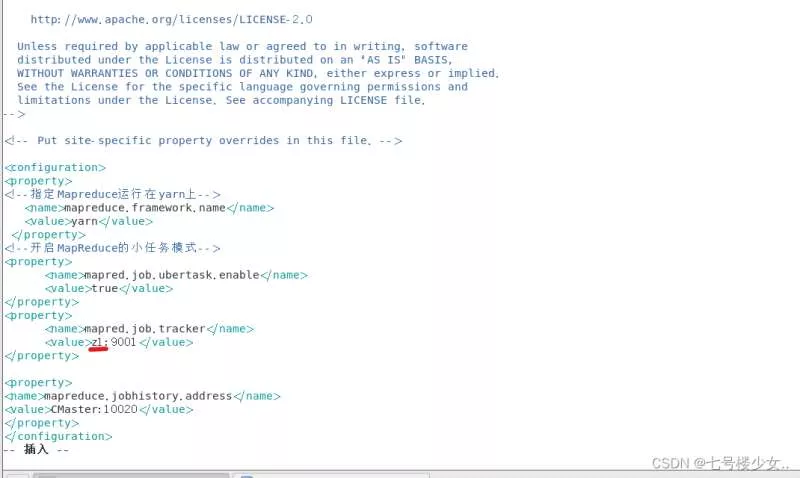
(3)Hadoop没有mapred-site.xml这个文件现将文件复制到这然后进入mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
(z1:在主节点的ip或者映射名(改成自己的))
<configuration>
<property>
<!--指定Mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--开启MapReduce的小任务模式-->
<property>
<name>mapred.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>z1:9001</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>CMaster:10020</value>
</property>
</configuration>
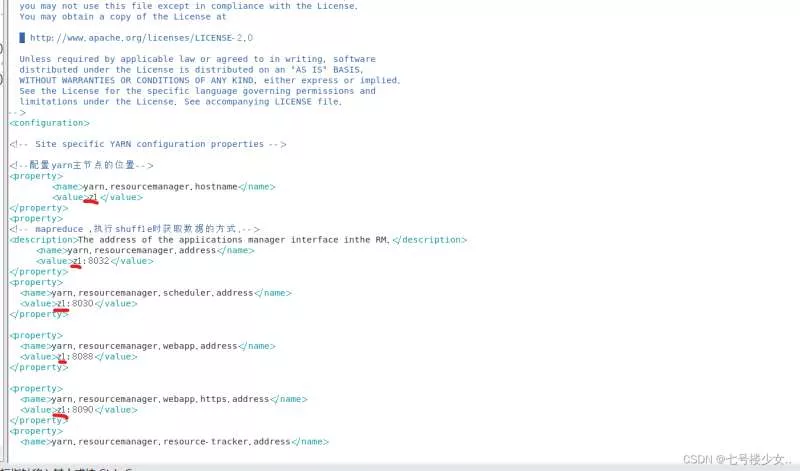
(4)进入yarn-site.xml
vim yarn-site.xml
(z1:在主节点的ip或者映射名(改成自己的))
<configuration>
<!-- Site specific YARN configuration properties -->
<!--配置yarn主节点的位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>z1</value>
</property>
<property>
<!-- mapreduce ,执行shuff1e时获取数据的方式.-->
<description>The address of the appiications manager interface inthe RM.</description>
<name>yarn.resourcemanager.address</name>
<value>z1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>z1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>z1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>z1:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>z1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>z1:8033</value>
</property>
<property><!--mapreduce执行shuff1e时获取数据的方式,-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--设置内存,yarn的内存分配-->
<name>yarn.scheduler.maximum-a11ocation-mb</name>
<value>2024</value>
<discription>每个节点可用内存,单位M,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
(5)进入hdfs-site.xml
vim hdfs-site.xml
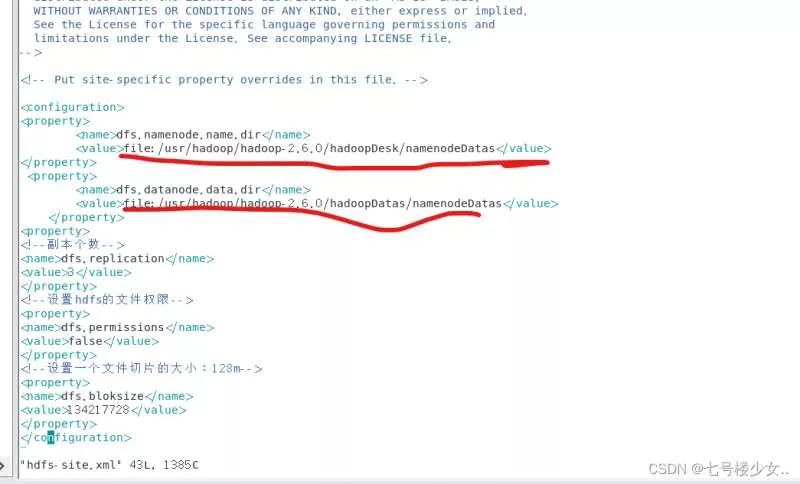
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.6.0/hadoopDesk/namenodeDatas</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.6.0/hadoopDatas/namenodeDatas</value>
</property>
<property>
<!--副本个数-->
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置hdfs的文件权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!--设置一个文件切片的大小:128m-->
<property>
<name>dfs.bloksize</name>
<value>134217728</value>
</property>
</configuration>
6.进入slaves添加主节点和从节点
vim slaves
添加自己的主节点和从节点(我的是z1,z2,z3)

scp -r /etc/profile root@z2:/etc/profile #将环境变量profile文件分发到z2节点
scp -r /etc/profile root@z3:/etc/profile #将环境变量profile文件分发到z3节点
scp -r /usr/hadoop root@z2:/usr/ #将hadoop文件分发到z2节点
scp -r /usr/hadoop root@z3:/usr/ #将hadoop文件分发到z3节点
生效两个从节点的环境变量
source /etc/profile
8.格式化hadoop (仅在主节点中进行操作)
首先查看jps是否启动hadoop
hadoop namenode -format
当看到Exiting with status 0时说明格式化成功
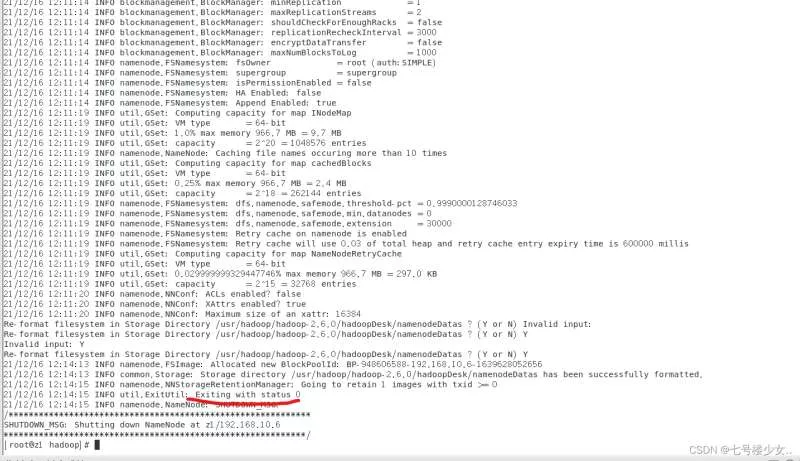
cd /usr/hadoop/hadoop-2.6.0
sbin/start-all.sh 启动Hadoop仅在主节点操作
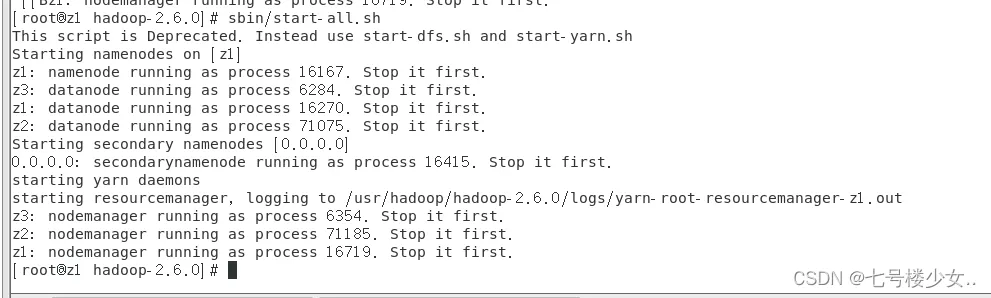
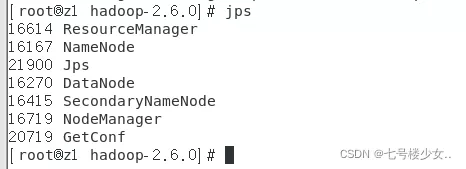
主节点输入jps效果:
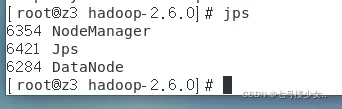
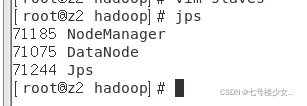
从节点输jps效果:
到此这篇关于Linux下安装Hadoop集群详细步骤的文章就介绍到这了,更多相关Linux安装Hadoop集群内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!
相关文章
Adeline
2020-07-08
Meta
2023-07-22
Samira
2023-07-22
Ursula
2023-07-22
Radinka
2023-07-22
Gella
2023-07-22
Miette
2023-07-22
Zandra
2023-07-22
Kara
2023-07-22
Irma
2023-07-22
Kande
2023-08-08
Tricia
2023-08-08
Karli
2023-08-08
Ula
2023-08-08
Dulcea
2023-08-08
Malina
2023-08-08
Fawn
2023-08-08
Rose
2023-08-08
Tia
2023-08-08