关系型数据库
非关系型数据库:Redis / MongoDB / ElasticSearch
我们在这里对数据库的安装不做过多的解释,网上有很多关于这方面的例子,
SQL基本操作通常将SQL分为三类:DDL(数据库定义语言)、DML(数据库操作语言)和DCL(数据库控制语言)。DDL主要用于创建(create)、删除(drop)、修改(alter)数据库中的对象,比如创建、删除和修改二维表;DML主要负责插入数据(insert)、删除数据(delete)、更新数据(update)和查询(select);DCL通常用于授予权限(grant)和召回权限(revoke)。
说明:SQL是不区分大小写的语言,为了书写方便,下面的SQL都使用了小写字母来书写。
DDL有几点需要注意:
- 创建数据库时,指定数据库默认的字符集,我们一般使用utf8。
create database learn default charset utf8 collate utf8_bin;
- 创建表的时候指定表的存储引擎,mysql支持多种引擎,5.5版本以后默认的是InnoDB,也是推荐的引擎,它更适合应用对高并发、性能及事务方面的需求。
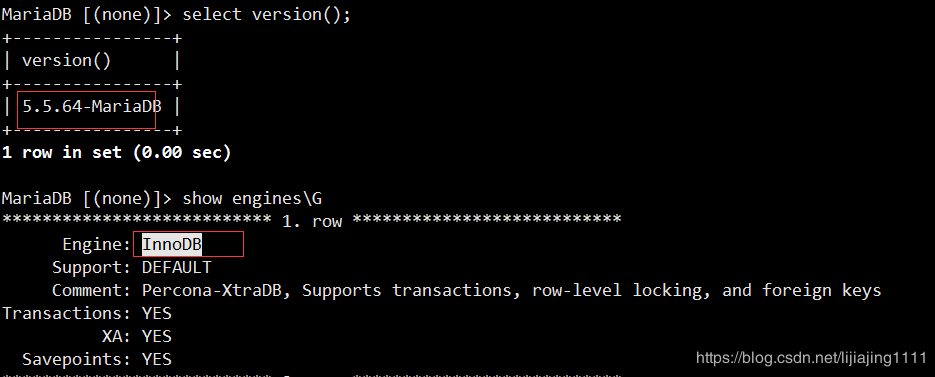
索引是我们在数据库中常用的手段,用于提高查询性能,索引就像一本书中的目录。创建索引虽然会带来存储空间上的开销,就像一本书的目录会占用一部分的篇幅一样,但是在牺牲空间后换来的查询时间的减少也是非常显著的。
MySQL中,所有数据类型的列都可以被索引,常用的存储引擎InnoDB和MyISAM能支持每个表创建16个索引。InnoDB和MyISAM使用的索引其底层算法是B-tree(B树),B-tree是一种自平衡的树,类似于平衡二叉排序树,能够保持数据有序。这种数据结构能够让查找数据、顺序访问、插入数据及删除的操作都在对数时间内完成。
我们通过一个简单的例子来说明索引的意义,使用MySQL的explain关键字来查看SQL的执行计划。
explain select * from tb_student where stuname=‘乖乖’\G;
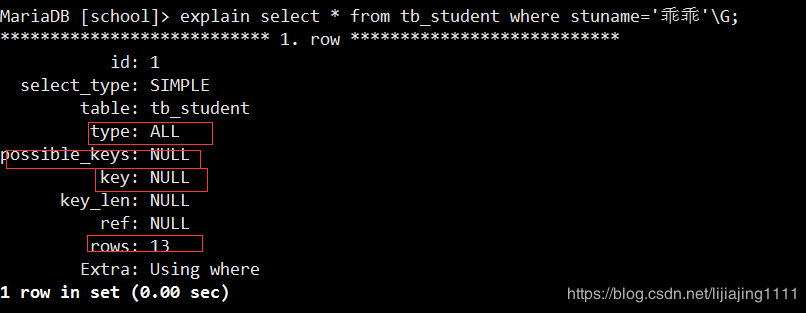
在上面的SQL执行计划中,我们关注以下几点:
type:MySQL在表中找到满足条件的行的方式,也称为访问类型,包括:ALL(全表扫描)、index(索引全扫描)、range(索引范围扫描)、ref(非唯一索引扫描)、eq_ref(唯一索引扫描)、const/system、NULL。在所有的访问类型中,很显然ALL是性能最差的,它代表了全表扫描是指要扫描表中的每一行才能找到匹配的行。 possible_keys:MySQL可以选择的索引,但是有可能不会使用。 key:MySQL真正使用的索引。 rows:执行查询需要扫描的行数,这是一个预估值,上述我们可以看到是个13。从上面的执行计划可以看出,通过学生名字查询学生时实际上是进行了全表扫描。如果我们需要经常通过学生姓名来查询学生,那么就应该在学生姓名对应的列上创建索引,通过索引来加速查询。
create index idx_student_name on tb_student(stuname);
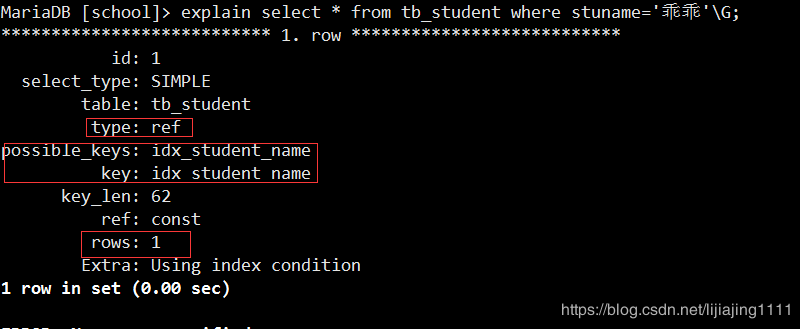
可以看到我们创建了索引之后刚才的查询已经不是全表扫描,而且扫描的行只有唯一的一行,这显然大大的提升了查询的性能。
MySQL中还允许创建前缀索引,即对索引字段的前N个字符创建索引,这样的话可以减少索引占用的空间(但节省了空间很有可能会浪费时间,时间和空间是不可调和的矛盾),如下所示。
create index idx_student_name_1 on tb_student(stuname(1));
如果要删除索引,可以使用下面的SQL。
drop index idx_student_name on tb_student;
我们总结一下索引的设计原则:
最适合索引的列是出现在WHERE子句和连接子句中的列。 索引列的基数越大(取值多重复值少),索引的效果就越好。 使用前缀索引可以减少索引占用的空间,内存中可以缓存更多的索引。 索引不是越多越好,虽然索引加速了读操作(查询),但是写操作(增、删、改)都会变得更慢,因为数据的变化会导致索引的更新,就如同书籍章节的增删需要更新目录一样。 使用InnoDB存储引擎时,表的普通索引都会保存主键的值,所以主键要尽可能选择较短的数据类型,这样可以有效的减少索引占用的空间,利用提升索引的缓存效果。 视图视图是关系型数据库中将一组指令构成的结果集组合成可查询的数据表的对象。简单的说,视图就是虚拟的表。
使用视图可以获得以下好处:
创建视图:
create view vw_score
as
select sid, round(avg(score), 1) as avgscore from tb_record group by sid;
create view vw_student_score
as
select stuname, avgscore
from tb_student, vw_score
where stuid=sid;
提示:因为视图不包含数据,所以每次使用视图时,都必须执行查询以获得数据,如果你使用了连接查询、嵌套查询创建了较为复杂的视图,你可能会发现查询性能下降得很厉害。因此,在使用复杂的视图前,应该进行测试以确保其性能能够满足应用的需求。
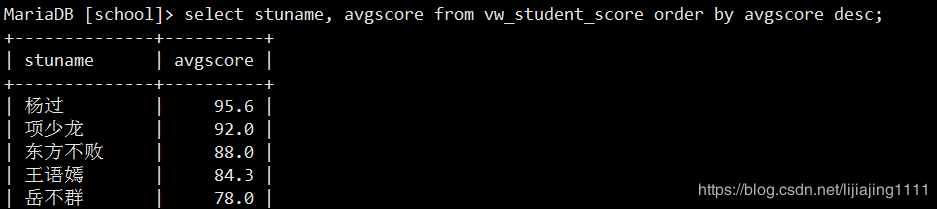
使用视图。
select stuname, avgscore from vw_student_score order by avgscore desc;
视图的规则和限制。
视图可以嵌套,可以利用从其他视图中检索的数据来构造一个新的视图。视图也可以和表一起使用。 创建视图时可以使用order by子句,但如果从视图中检索数据时也使用了order by,那么该视图中原先的order by会被覆盖。 视图无法使用索引,也不会激发触发器(实际开发中因为性能等各方面的考虑,通常不建议使用触发器,所以我们也不对这个概念进行介绍)的执行。 存储过程存储过程是事先编译好存储在数据库中的一组SQL的集合,调用存储过程可以简化应用程序开发人员的工作,减少与数据库服务器之间的通信,提升数据操作的性能。
delimiter $$
create procedure sp_get_score(courseId int,
out maxScore decimal(4,1),
out minScore decimal(4,1),
out avgScore decimal(4,1))
begin
select max(score) into maxScore from tb_record where cid=courseId;
select min(score) into minScore from tb_record where cid=courseId;
select avg(score) into avgScore from tb_record where cid=courseId;
end $$
delimiter ;
说明:在定义存储过程时,因为可能需要书写多条SQL,而分隔这些SQL需要使用分号作为分隔符,如果这个时候,仍然用分号表示整段代码结束,那么定义存储过程的SQL就会出现错误,所以上面我们用delimiter $$ 将整段代码结束的标记定义为 $$,那么代码中的分号将不再表示整段代码的结束,需要马上执行,整段代码在遇到end $$时才输入完成并执行。在定义完存储过程后,通过delimiter ; 将结束符重新改回成分号。
上面定义的存储过程有四个参数,第一个参数是输入参数,代表课程的编号,后面的参数都是输出参数,因为存储过程不能定义返回值,只能通过输出参数将执行结果带出,定义输出参数的关键字是 out,默认情况下都是输入参数。
调用存数过程
call sp_get_score(1111, @a, @b, @c);
获取输出参数的值
select @a as 最高分, @b as 最低分, @c as 平均分;

删除存储过程
drop procedure sp_get_score;
数据的一致性
1、事务:事务:一系列对数据库进行读/写的操作,这些操作要么全都成功,要么全都失败。
2、事务的ACID特性
3、MySQL中的事务操作
开启事务环境
start transaction
或
begin
提交事务
commit
回滚事务
rollback
Python数据库编程
PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中则使用mysqldb。
插入数据
"""
pymysql - 插入数据
Version: 0.1
Author: Luicy
Date: 2020-3-26
"""
import pymysql
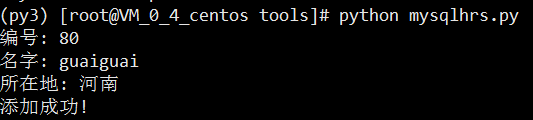
def main():
id = int(input('编号: '))
name = input('名字: ')
loc = input('所在地: ')
# 1. 创建数据库连接对象
con = pymysql.connect(host='localhost', port=3306,
database='hrs', charset='utf8',
user='root', password='')
try:
# 2. 通过连接对象获取游标
with con.cursor() as cursor:
# 3. 通过游标执行SQL并获得执行结果
result = cursor.execute(
'insert into tb_dept values (%s, %s, %s)',
(id, name, loc)
)
if result == 1:
print('添加成功!')
# 4. 操作成功提交事务
con.commit()
finally:
# 5. 关闭连接释放资源
con.close()
if __name__ == '__main__':
main()
说明:pymysql语句中想要使用变量的方法:
cursor.execute( ‘insert into tb_dept values (%s, %s, %s)’, (id, name, loc))
注意占位符统统是%s字符串类型,不再区分字符串,数字或者其他类型。另外%s不能加引号
删除数据
import pymysql
def main():
id = int(input("输入要删除的编号:"))
#打开数据库连接,autocommit=True自动提交事务
con = pymysql.connect(host='localhost', port=3306,
database='hrs', charset='utf8',
user='root', password='',
autocommit=True)
try:
#通过连接对象获取游标
with con.cursor() as cursor:
#通过游标执行sql并获得结果
result = cursor.execute(
'delete from tb_dept where dno=%s',
(id,))
if result == 1:
print("删除成功!")
finally:
con.close()
if __name__ == '__main__':
main()
更新数据
import pymysql
def main():
id = int(input("输入更新的编号:"))
name = input("更新后的名字:")
loc = input("更新后的所在地:")
con = pymysql.connect(host='localhost', port=3306,
database='hrs', charset='utf8',
user='root', passwd='',
autocommit=True)
try:
with con.cursor() as cursor:
result =cursor.execute('update tb_dept set dname=%s, dloc=%s where dno=%s', (name, loc, id))
if result == 1:
print('更新成功!')
finally:
con.close()
if __name__ == '__main__':
main()
查询
Python查询Mysql使用 fetchone() 方法获取单条数据, 使用fetchall() 方法获取多条数据。
"""
pymysql - 查询数据
Version: 0.1
Author: Luicy
Date: 2020-3-26
"""
import pymysql
from pymysql.cursors import DictCursor
def main():
con = pymysql.connect(host='localhost', port=3306,
database='hrs', charset='utf8',
user='root', passwd='',
autocommit=True)
try:
with con.cursor(cursor=DictCursor) as cursor:
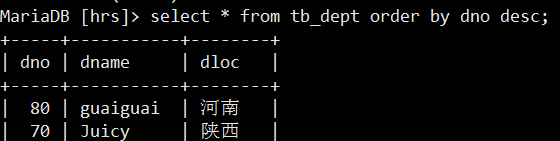
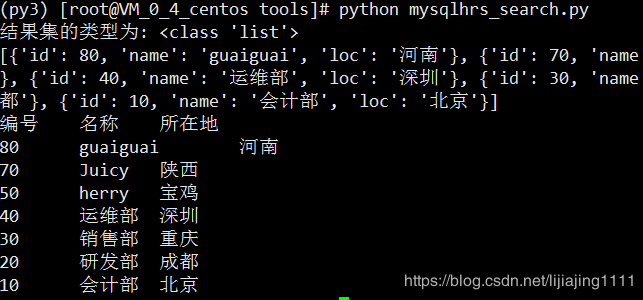
cursor.execute('select dno as id, dname as name, dloc as loc from tb_dept order by dno desc')
result = cursor.fetchall()
print("结果集的类型为:",type(result))
print(result)
print("编号\t名称\t所在地")
for i in result:
print(i['id'], end='\t')
print(i['name'], end='\t')
print(i['loc'])
finally:
cursor.close()
if __name__ == '__main__':
main()
说明:cursor结果集默认是元组类型,如果我们想要获取到字典类型,通过指定DictCursor方法
分页查询员工信息
limit的两种方式。
limit a,b 后缀两个参数的时候(参数必须是一个整数常量),其中a是指记录开始的偏移量,b是指从第a+1条开始,取b条记录。 limit b 后缀一个参数的时候,是直接取值到第多少位,类似于:limit 0,b 。import pymysql
class Emp(object):
def __init__(self, no, name, job, sal):
self.no = no
self.name = name
self.job = job
self.sal = sal
def __str__(self):
return f'\n编号:{self.no}\n姓名:{self.name}\n职位:{self.job}\n月薪:{self.sal}\n'
def main():
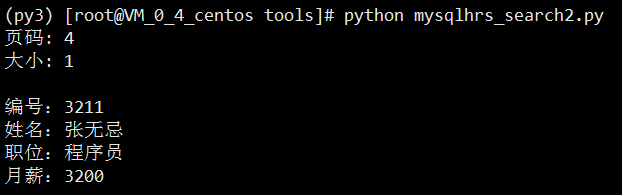
page = int(input('页码: '))
size = int(input('大小: '))
con = pymysql.connect(host='localhost', port=3306,
database='hrs', charset='utf8',
user='root', password='123456')
try:
with con.cursor() as cursor:
cursor.execute(
'select eno as no, ename as name, job, sal from tb_emp limit %s,%s',
((page - 1) * size, size)
)
for emp_tuple in cursor.fetchall():
emp = Emp(*emp_tuple)
print(emp)
finally:
con.close()
if __name__ == '__main__':
main()
思考:怎么增加代码的健壮性,在上述程序中用户有可能输入的页码不在表的长度范围内里。
一个功能比较全的程序,包含查询、删除、更新等。
"""
-- 创建名为address的数据库
create database address default charset utf8;
-- 切换到address数据库
use address;
-- 创建联系人表tb_contacter
create table tb_contacter
(
conid int auto_increment comment '编号',
conname varchar(31) not null comment '姓名',
contel varchar(15) default '' comment '电话',
conemail varchar(255) default'' comment '邮箱',
primary key (conid)
);
"""
import pymysql
INSERT_CONTACTER = """
insert into tb_contacter (conname, contel, conemail)
values (%s, %s, %s)
"""
DELETE_CONTACTER = """
delete from tb_contacter where conid=%s
"""
UPDATE_CONTACTER = """
update tb_contacter set conname=%s, contel=%s, conemail=%s
where conid=%s
"""
SELECT_CONTACTERS = """
select conid as id, conname as name, contel as tel, conemail as email
from tb_contacter limit %s offset %s
"""
SELECT_CONTACTERS_BY_NAME = """
select conid as id, conname as name, contel as tel, conemail as email
from tb_contacter where conname like %s
"""
COUNT_CONTACTERS = """
select count(conid) as total from tb_contacter
"""
class Contacter(object):
def __init__(self, id, name, tel, email):
self.id = id
self.name = name
self.tel = tel
self.email = email
def input_contacter_info():
name = input('姓名: ')
tel = input('手机: ')
email = input('邮箱: ')
return name, tel, email
def add_new_contacter(con):
name, tel, email = input_contacter_info()
try:
with con.cursor() as cursor:
if cursor.execute(INSERT_CONTACTER,
(name, tel, email)) == 1:
print('添加联系人成功!')
except pymysql.MySQLError as err:
print(err)
print('添加联系人失败!')
def delete_contacter(con, contacter):
try:
with con.cursor() as cursor:
if cursor.execute(DELETE_CONTACTER, (contacter.id, )) == 1:
print('联系人已经删除!')
except pymysql.MySQLError as err:
print(err)
print('删除联系人失败!')
def edit_contacter_info(con, contacter):
name, tel, email = input_contacter_info()
contacter.name = name or contacter.name
contacter.tel = tel or contacter.tel
contacter.email = email or contacter.email
try:
with con.cursor() as cursor:
if cursor.execute(UPDATE_CONTACTER,
(contacter.name, contacter.tel,
contacter.email, contacter.id)) == 1:
print('联系人信息已经更新!')
except pymysql.MySQLError as err:
print(err)
print('更新联系人信息失败!')
def show_contacter_detail(con, contacter):
print('姓名:', contacter.name)
print('手机号:', contacter.tel)
print('邮箱:', contacter.email)
choice = input('是否编辑联系人信息?(yes|no)')
if choice == 'yes':
edit_contacter_info(con, contacter)
else:
choice = input('是否删除联系人信息?(yes|no)')
if choice == 'yes':
delete_contacter(con, contacter)
def show_search_result(con, cursor):
contacters_list = []
for index, row in enumerate(cursor.fetchall()):
contacter = Contacter(**row)
contacters_list.append(contacter)
print('[%d]: %s' % (index, contacter.name))
if len(contacters_list) > 0:
choice = input('是否查看联系人详情?(yes|no)')
if choice.lower() == 'yes':
index = int(input('请输入编号: '))
if 0 <= index < cursor.rowcount:
show_contacter_detail(con, contacters_list[index])
def find_all_contacters(con):
page, size = 1, 5
try:
with con.cursor() as cursor:
cursor.execute(COUNT_CONTACTERS)
total = cursor.fetchone()['total']
while True:
cursor.execute(SELECT_CONTACTERS,
(size, (page - 1) * size))
show_search_result(con, cursor)
if page * size < total:
choice = input('继续查看下一页?(yes|no)')
if choice.lower() == 'yes':
page += 1
else:
break
else:
print('没有下一页记录!')
break
except pymysql.MySQLError as err:
print(err)
def find_contacters_by_name(con):
name = input('联系人姓名: ')
try:
with con.cursor() as cursor:
cursor.execute(SELECT_CONTACTERS_BY_NAME,
('%' + name + '%', ))
show_search_result(con, cursor)
except pymysql.MySQLError as err:
print(err)
def find_contacters(con):
while True:
print('1. 查看所有联系人')
print('2. 搜索联系人')
print('3. 退出查找')
choice = int(input('请输入: '))
if choice == 1:
find_all_contacters(con)
elif choice == 2:
find_contacters_by_name(con)
elif choice == 3:
break
def main():
con = pymysql.connect(host='localhost', port=3306,
user='root', passwd='',
db='address', charset='utf8',
autocommit=True,
cursorclass=pymysql.cursors.DictCursor)
while True:
print('=====通讯录=====')
print('1. 新建联系人')
print('2. 查找联系人')
print('3. 退出系统')
print('===============')
choice = int(input('请选择: '))
if choice == 1:
add_new_contacter(con)
elif choice == 2:
find_contacters(con)
elif choice == 3:
con.close()
print('谢谢使用, 再见!')
break
if __name__ == '__main__':
main()
代码参考:github上的 python-100-Days-master 项目,非常好的学习材料,强烈推荐。
作者:Juicy Li