group by用法详解
group_by的意思是根据by对数据按照哪个字段进行分组,或者是哪几个字段进行分组。
二. 语法三. 案例 1 创建表格并插入数据select 字段 from 表名 where 条件 group by 字段
或者
select 字段 from 表名 group by 字段 having 过滤条件
注意:对于过滤条件,可以先用where,再用group by或者是先用group by,再用having
说明:在plsql developer上创建表格并插入数据,以便下面进行简单字段分组以及多个字段分组,同时还结合聚合函数进行运算。
2 单个字段分组
创建student表create table student
(id int not null ,
name varchar2(30),
grade varchar2(30),
salary varchar2(30)
)
在student表中插入数据insert into student values(1,'zhangsan','A',1500);
insert into student values(2,'lisi','B',3000);
insert into student values(1,'zhangsan','A',1500);
insert into student values(4,'qianwu','A',3500);
insert into student values(3,'zhaoliu','C',2000);
insert into student values(1,'huyifei','D',2500);
数据插入到student表中的结果

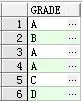
① select grade from student 查出所有学生等级(包括重复的等级)
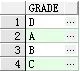
② select grade from student group by grade 查出学生等级的种类(按照等级划分,去除重复的)
select name , sum(salary) from student group by name , grade 按照名字和等级划分,查看相同名字下的工资总和
注意:这里有一点需要说明一下,多个字段进行分组时,需要将name和grade看成一个整体,只要是name和grade相同的可以分成一组;如果只是name相同,grade不同就不是一组。

常用的聚合函数:count() , sum() , avg() , max() , min()
count():计数select name , count(*) from student group by name 查看表中相同人名的个数
得出的如下结果

sum():求和select name , sum(salary) from student group by name 查看表中人员的工资和(同姓的工资相加)
得出的如下结果

avg():平均数select name , avg(salary) from student group by name , grade 查看表中人员的工资平均数(同姓工资平均数)
得出的如下结果

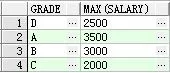
max():最大值select grade , max(salary) from student group by grade 查看按等级划分人员工资最大值
得出的如下结果
min():最小值select grade , min(salary) from student group by grade 查看按等级划分人员工资最小值
得出的如下结果
