LeNet、AlexNet、VGG、NiN、GoogLeNet
使用全连接层的局限性:
图像在同一列邻近的像素在这个向量中可能相距较远。它们构成的模式可能难以被模型识别。
对于大尺寸的输入图像,使用全连接层容易导致模型过大。
使用卷积层的优势:
卷积层保留输入形状。
卷积层通过滑动窗口将同一卷积核与不同位置的输入重复计算,从而避免参数尺寸过大
LeNet LeNet模型LeNet分为卷积层块和全连接层块两个部分。
 LeNet网络结构
LeNet网络结构
卷积层块里的基本单位是卷积层后接最大池化层:卷积层用来识别图像里的空间模式,如线条和物体局部,之后的最大池化层则用来降低卷积层对位置的敏感性。卷积层块由两个这样的基本单位重复堆叠构成。在卷积层块中,每个卷积层都使用5×55\times 55×5的窗口,并在输出上使用sigmoid激活函数。第一个卷积层输出通道数为6,第二个卷积层输出通道数则增加到16。这是因为第二个卷积层比第一个卷积层的输入的高和宽要小,所以增加输出通道使两个卷积层的参数尺寸类似。卷积层块的两个最大池化层的窗口形状均为2×22\times 22×2,且步幅为2。由于池化窗口与步幅形状相同,池化窗口在输入上每次滑动所覆盖的区域互不重叠。
卷积层块的输出形状为(批量大小, 通道, 高, 宽)。当卷积层块的输出传入全连接层块时,全连接层块会将小批量中每个样本变平(flatten)。也就是说,全连接层的输入形状将变成二维,其中第一维是小批量中的样本,第二维是每个样本变平后的向量表示,且向量长度为通道、高和宽的乘积。全连接层块含3个全连接层。它们的输出个数分别是120、84和10,其中10为输出的类别个数。
LeNet的pytorch实现#import
import sys
sys.path.append("../")
import d2lzh1981 as d2l
import torch
import torch.nn as nn
import torch.optim as optim
import time
class Flatten(torch.nn.Module): #展平操作
def forward(self, x):
return x.view(x.shape[0], -1)
class Reshape(torch.nn.Module): #将图像大小重定型
def forward(self, x):
return x.view(-1,1,28,28) #(B x C x H x W)
net = torch.nn.Sequential( #Lelet
Reshape(),
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2), #b*1*28*28 =>b*6*28*28
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), #b*6*28*28 =>b*6*14*14
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5), #b*6*14*14 =>b*16*10*10
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), #b*16*10*10 => b*16*5*5
Flatten(), #b*16*5*5 => b*400
nn.Linear(in_features=16*5*5, out_features=120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
AlexNet
LeNet: 在大的真实数据集上的表现并不尽如⼈意。
1.神经网络计算复杂。
2.还没有⼤量深⼊研究参数初始化和⾮凸优化算法等诸多领域。
机器学习的特征提取:手工定义的特征提取函数
神经网络的特征提取:通过学习得到数据的多级表征,并逐级表⽰越来越抽象的概念或模式。
神经网络发展的限制:数据、硬件
AlexNet模型AlexNet使用了8层卷积神经网络,并以很大的优势赢得了ImageNet 2012图像识别挑战赛。它首次证明了学习到的特征可以超越手工设计的特征,从而一举打破计算机视觉研究的前状。
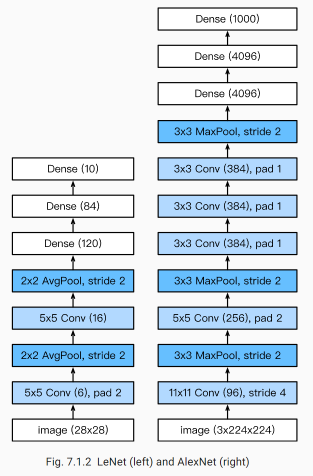 AlexNet网络结构
AlexNet网络结构
AlexNet与LeNet的设计理念非常相似,但也有显著的区别。
第一,与相对较小的LeNet相比,AlexNet包含8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层。下面我们来详细描述这些层的设计。
AlexNet第一层中的卷积窗口形状是11×1111\times1111×11。因为ImageNet中绝大多数图像的高和宽均比MNIST图像的高和宽大10倍以上,ImageNet图像的物体占用更多的像素,所以需要更大的卷积窗口来捕获物体。第二层中的卷积窗口形状减小到5×55\times55×5,之后全采用3×33\times33×3。此外,第一、第二和第五个卷积层之后都使用了窗口形状为3×33\times33×3、步幅为2的最大池化层。而且,AlexNet使用的卷积通道数也大于LeNet中的卷积通道数数十倍。
紧接着最后一个卷积层的是两个输出个数为4096的全连接层。这两个巨大的全连接层带来将近1 GB的模型参数。由于早期显存的限制,最早的AlexNet使用双数据流的设计使一个GPU只需要处理一半模型。幸运的是,显存在过去几年得到了长足的发展,因此通常我们不再需要这样的特别设计了。
第二,AlexNet将sigmoid激活函数改成了更加简单的ReLU激活函数。一方面,ReLU激活函数的计算更简单,例如它并没有sigmoid激活函数中的求幂运算。另一方面,ReLU激活函数在不同的参数初始化方法下使模型更容易训练。这是由于当sigmoid激活函数输出极接近0或1时,这些区域的梯度几乎为0,从而造成反向传播无法继续更新部分模型参数;而ReLU激活函数在正区间的梯度恒为1。因此,若模型参数初始化不当,sigmoid函数可能在正区间得到几乎为0的梯度,从而令模型无法得到有效训练。
第三,AlexNet通过丢弃法(参见3.13节)来控制全连接层的模型复杂度。而LeNet并没有使用丢弃法。
第四,AlexNet引入了大量的图像增广,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。
AlexNet的pytorch实现import time
import torch
from torch import nn, optim
import torchvision
import numpy as np
import sys
sys.path.append("/home/kesci/input/")
import d2lzh1981 as d2l
import os
import torch.nn.functional as F
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
#由于使用CPU镜像,精简网络,若为GPU镜像可添加该层
#nn.Linear(4096, 4096),
#nn.ReLU(),
#nn.Dropout(0.5),
# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
VGG
VGG模型
VGG:通过重复使⽤简单的基础块来构建深度模型。
Block:数个相同的填充为1、窗口形状为的卷积层,接上一个步幅为2、窗口形状为的最大池化层。
卷积层保持输入的高和宽不变,而池化层则对其减半。

与AlexNet和LeNet一样,VGG网络由卷积层模块后接全连接层模块构成。卷积层模块串联数个vgg_block,其超参数由变量conv_arch定义。该变量指定了每个VGG块里卷积层个数和输入输出通道数。全连接模块则跟AlexNet中的一样。
def vgg_block(num_convs, in_channels, out_channels): #卷积层个数,输入通道数,输出通道数
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
def vgg(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(d2l.FlattenLayer(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 10)
))
return net
NiN(网络中的网络)
LeNet、AlexNet和VGG:先以由卷积层构成的模块充分抽取 空间特征,再以由全连接层构成的模块来输出分类结果。
NiN:串联多个由卷积层和“全连接”层构成的小⽹络来构建⼀个深层⽹络。
⽤了输出通道数等于标签类别数的NiN块,然后使⽤全局平均池化层对每个通道中所有元素求平均并直接⽤于分类。

1×1卷积核作用
def nin_block(in_channels, out_channels, kernel_size, stride, padding):
blk = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU())
return blk
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, stride=4, padding=0),
nn.MaxPool2d(kernel_size=3, stride=2),
nin_block(96, 256, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nin_block(256, 384, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, stride=1, padding=1),
GlobalAvgPool2d(),
# 将四维的输出转成二维的输出,其形状为(批量大小, 10)
d2l.FlattenLayer())
GooLeNet
由Inception基础块组成。
Inception块相当于⼀个有4条线路的⼦⽹络。它通过不同窗口形状的卷积层和最⼤池化层来并⾏抽取信息,并使⽤1×1卷积层减少通道数从而降低模型复杂度。
可以⾃定义的超参数是每个层的输出通道数,我们以此来控制模型复杂度。
Inception块

Inception块里有4条并行的线路。前3条线路使用窗口大小分别是1×11\times 11×1、3×33\times 33×3和5×55\times 55×5的卷积层来抽取不同空间尺寸下的信息,其中中间2个线路会对输入先做1×11\times 11×1卷积来减少输入通道数,以降低模型复杂度。第四条线路则使用3×33\times 33×3最大池化层,后接1×11\times 11×1卷积层来改变通道数。4条线路都使用了合适的填充来使输入与输出的高和宽一致。最后我们将每条线路的输出在通道维上连结,并输入接下来的层中去。
Inception块中可以自定义的超参数是每个层的输出通道数,我们以此来控制模型复杂度。
完整goolenet模型GoogLeNet跟VGG一样,在主体卷积部分中使用5个模块(block),每个模块之间使用步幅为2的3×33\times 33×3最大池化层来减小输出高宽。
第一模块使用一个64通道的7×77\times 77×7卷积层。 第二模块使用2个卷积层:首先是64通道的1×11\times 11×1卷积层,然后是将通道增大3倍的3×33\times 33×3卷积层。它对应Inception块中的第二条线路。 第三模块串联2个完整的Inception块。第一个Inception块的输出通道数为64+128+32+32=25664+128+32+32=25664+128+32+32=256,其中4条线路的输出通道数比例为64:128:32:32=2:4:1:164:128:32:32=2:4:1:164:128:32:32=2:4:1:1。其中第二、第三条线路先分别将输入通道数减小至96/192=1/296/192=1/296/192=1/2和16/192=1/1216/192=1/1216/192=1/12后,再接上第二层卷积层。第二个Inception块输出通道数增至128+192+96+64=480128+192+96+64=480128+192+96+64=480,每条线路的输出通道数之比为128:192:96:64=4:6:3:2128:192:96:64 = 4:6:3:2128:192:96:64=4:6:3:2。其中第二、第三条线路先分别将输入通道数减小至128/256=1/2128/256=1/2128/256=1/2和32/256=1/832/256=1/832/256=1/8 第四模块更加复杂。它串联了5个Inception块,其输出通道数分别是192+208+48+64=512192+208+48+64=512192+208+48+64=512、160+224+64+64=512160+224+64+64=512160+224+64+64=512、128+256+64+64=512128+256+64+64=512128+256+64+64=512、112+288+64+64=528112+288+64+64=528112+288+64+64=528和256+320+128+128=832256+320+128+128=832256+320+128+128=832。这些线路的通道数分配和第三模块中的类似,首先含3×33\times 33×3卷积层的第二条线路输出最多通道,其次是仅含1×11\times 11×1卷积层的第一条线路,之后是含5×55\times 55×5卷积层的第三条线路和含3×33\times 33×3最大池化层的第四条线路。其中第二、第三条线路都会先按比例减小通道数。这些比例在各个Inception块中都略有不同。 第五模块有输出通道数为256+320+128+128=832256+320+128+128=832256+320+128+128=832和384+384+128+128=1024384+384+128+128=1024384+384+128+128=1024的两个Inception块。其中每条线路的通道数的分配思路和第三、第四模块中的一致,只是在具体数值上有所不同。需要注意的是,第五模块的后面紧跟输出层,该模块同NiN一样使用全局平均池化层来将每个通道的高和宽变成1。最后我们将输出变成二维数组后接上一个输出个数为标签类别数的全连接层。 完整模型
GooLeNet的pytorch
完整模型
GooLeNet的pytorch
class Inception(nn.Module):
# c1 - c4为每条线路里的层的输出通道数
def __init__(self, in_c, c1, c2, c3, c4):
super(Inception, self).__init__()
# 线路1,单1 x 1卷积层
self.p1_1 = nn.Conv2d(in_c, c1, kernel_size=1)
# 线路2,1 x 1卷积层后接3 x 3卷积层
self.p2_1 = nn.Conv2d(in_c, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1 x 1卷积层后接5 x 5卷积层
self.p3_1 = nn.Conv2d(in_c, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3 x 3最大池化层后接1 x 1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_c, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
return torch.cat((p1, p2, p3, p4), dim=1) # 在通道维上连结输出
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
d2l.GlobalAvgPool2d())
net = nn.Sequential(b1, b2, b3, b4, b5,
d2l.FlattenLayer(), nn.Linear(1024, 10))
net = nn.Sequential(b1, b2, b3, b4, b5, d2l.FlattenLayer(), nn.Linear(1024, 10))
X = torch.rand(1, 1, 96, 96)
for blk in net.children():
X = blk(X)
print('output shape: ', X.shape)
#batchsize=128
batch_size = 16
# 如出现“out of memory”的报错信息,可减小batch_size或resize
#train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
小结
卷积神经网络就是含卷积层的网络。
LeNet交替使用卷积层和最大池化层后接全连接层来进行图像分类。
AlexNet跟LeNet结构类似,但使用了更多的卷积层和更大的参数空间来拟合大规模数据集ImageNet。它是浅层神经网络和深度神经网络的分界线。
虽然看上去AlexNet的实现比LeNet的实现也就多了几行代码而已,但这个观念上的转变和真正优秀实验结果的产生令学术界付出了很多年。
VGG-11通过5个可以重复使用的卷积块来构造网络。根据每块里卷积层个数和输出通道数的不同可以定义出不同的VGG模型。
NiN重复使用由卷积层和代替全连接层的1×11\times 11×1卷积层构成的NiN块来构建深层网络。
NiN去除了容易造成过拟合的全连接输出层,而是将其替换成输出通道数等于标签类别数的NiN块和全局平均池化层。
NiN的以上设计思想影响了后面一系列卷积神经网络的设计。
Inception块相当于一个有4条线路的子网络。它通过不同窗口形状的卷积层和最大池化层来并行抽取信息,并使用1×11\times 11×1卷积层减少通道数从而降低模型复杂度。
GoogLeNet将多个设计精细的Inception块和其他层串联起来。其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的。
GoogLeNet和它的后继者们一度是ImageNet上最高效的模型之一:在类似的测试精度下,它们的计算复杂度往往更低。
作者:九号店