VGG,NIN and GoogLeNet
第一次使用kaggle的notebook,可以免费使用gpu还是挺爽的,不过就是不了解读取数据集的路径到底是怎么用的?感觉 /root/Datasets/里面的数据集不是主页面的Datasets
加强记忆:计算卷积,池化的H,W
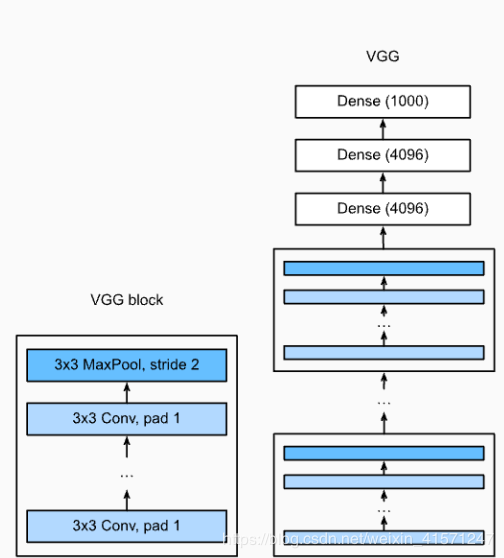
def vgg_block(num_convs, in_channels, out_channels): #卷积层个数,输入通道数,输出通道数
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
# 添加的时候超级方便,直接使用add_module,并且命个名,同样链接dense也需要flatten一下
def vgg(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(d2l.FlattenLayer(), # 展平 三维变一维
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 10)
))
return net
补充:在训练的时候,如果样本太少,参数可以适当减少;参数多样本少容易产生过拟合。
NiN 网络中的网络1*1卷积核的作用:
可以对feature map进行通道的放缩; 相当于全连接的计算过程,不flatten再计算,不会丢失空间信息,并且可以加上非线性激活参数; 大大减少参数量!(在其他博客学到的)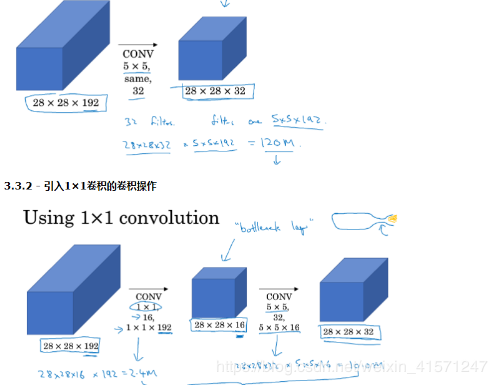
代替了Dense,将输出channel数等于label类别数
同样也是一个block一个block进行组装,不过多了一个GlobalAvgPool,我理解就是一个maxpool
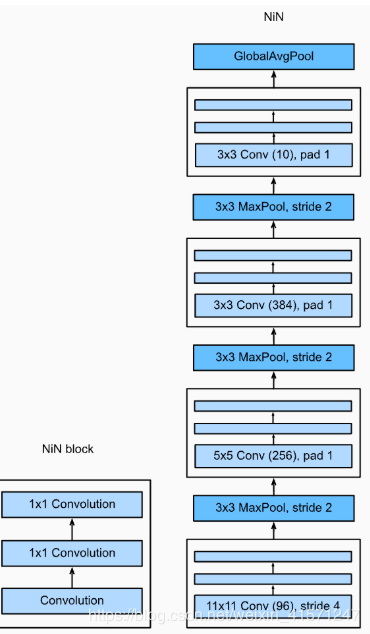
# 定义block
def nin_block(in_channels, out_channels, kernel_size, stride, padding):
blk = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), # 1 不改变形状啦
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU())
return blk
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, stride=4, padding=0),
nn.MaxPool2d(kernel_size=3, stride=2),
nin_block(96, 256, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nin_block(256, 384, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, stride=1, padding=1),
GlobalAvgPool2d(),
# 其实输出是(样本数,10,1,1) -> 需要(样本数,10)
# 将四维的输出转成二维的输出,其形状为(批量大小, 10)
d2l.FlattenLayer()) # 最后要flatten和Dense连接
# 举个例子看看
X = torch.rand(1, 1, 224, 224) # 224是h,w
for name, blk in net.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)
GoogLeNet
由Inception基础块组成。
Inception块相当于⼀个有4条线路的⼦⽹络。它通过不同窗口形状的卷积层和最⼤池化层来并⾏抽取信息,并使⽤1×1卷积层减少通道数从而降低模型复杂度。
可以⾃定义的超参数是每个层的输出通道数,我们以此来控制模型复杂度。
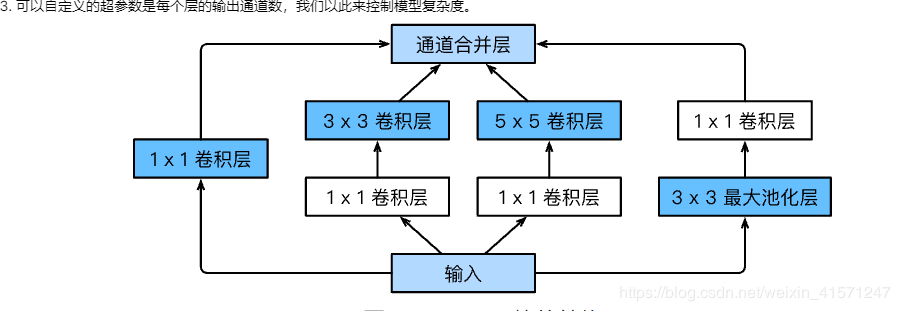
这里四条线路并行,注意最后的通道数就行!!最后cat一起!
class Inception(nn.Module):
# c1 - c4为每条线路里的层的输出通道数
def __init__(self, in_c, c1, c2, c3, c4):
super(Inception, self).__init__()
# 线路1,单1 x 1卷积层
self.p1_1 = nn.Conv2d(in_c, c1, kernel_size=1)
# 线路2,1 x 1卷积层后接3 x 3卷积层
self.p2_1 = nn.Conv2d(in_c, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1) # 保持形状固定
# 线路3,1 x 1卷积层后接5 x 5卷积层
self.p3_1 = nn.Conv2d(in_c, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3 x 3最大池化层后接1 x 1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_c, c4, kernel_size=1)
def forward(self, x): # 连接起来
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
return torch.cat((p1, p2, p3, p4), dim=1) # 在通道维上连结输出 比如10+10+10+10=40
# 完整的结构
# 7*7conv 3*3maxpool 输入是1*96*96
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 1*1conv(增加非线性) 3*3conv 3*3 maxpool
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 2* 3*3maxpool 上面的输出通道 线路一输入192输出64 线路二 1*1输出96然后3*3输出128
#线路三同理16 32 c4就是32
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32), # 64+128+32+32=256
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 5* 3*3pooling
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 2* d2l.GlobalAvgPool2d(只起到了maxpooling作用)
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
d2l.GlobalAvgPool2d())
net = nn.Sequential(b1, b2, b3, b4, b5, # 展平
d2l.FlattenLayer(), nn.Linear(1024, 10))
net = nn.Sequential(b1, b2, b3, b4, b5, d2l.FlattenLayer(), nn.Linear(1024, 10))
X = torch.rand(1, 1, 96, 96)
for blk in net.children():
X = blk(X)
print('output shape: ', X.shape)
batch_size = 128
# 如出现“out of memory”的报错信息,可减小batch_size或resize
#train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
# 表明特征值越来越深,越来越抽象
这里如果通道不懂的,可以推一推。代码给出注释咯。
C1给出输入,输出channels
C2,C3 给出输入输出,最后只用到输出
C4也只需给出输出,输入都一样的嘛
作者:陈浩天就是我