linux 根文件系统,根设备,sys_open, sys_read, sys_write, sys_mount, sys_mknod
笔者语:
1. 内容涉及比较多,自己也没有分章节,因为觉得这些内容关联性很强,自己也懒的去弄了。
2. 本文涉及以下内容:
2.1 内核启动过程中,第一个文件系统为rootfs, 描述内核如何从rootfs切换到真正的根文件系统,
这其中包括了根设备的查找,还包括ramdisk, cpiok-initrd, image-initrd的描述。
2.2 内核如何关联文件dentry&inode。
2.3 内核与文件系统操作的几个相关的系统调用sys_open, sys_read, sys_write, sys_mount, sys_mknod。
2.4 最后还列了下ext4文件系统的inode操作接口。
3. 文中的代码片段中,不相关的或者不是“主线任务”的,都被我删去了。
4. 文件的代码基于linux 4.7.1版本。
5. 下一篇准备写linux 网络相关的,从socket创建,send/receive,到内核路由(策略路由),neighour机制
一直到驱动创建的net_dev. 包括周边的,比如eth接口的创建,vlan接口的创建,vlan头的创建(offload and non-offload)等等。
6. 转载,请注明来源。
7. 文中有描述不对的,或不清楚的,欢迎发邮件给我 shaohui973@163.com, 一起交流学习。
Linux设备启动时,ubootd主要工作就是加载kernel image,然后将控制权交给kernel.
Kernel 刚起来时,是没有文件系统的,所以,它要设置并找到根文件系统。本文主要将与这个相关的部分(基于linux kernel 4.7.1版本)。
Dentry代表某个目录项(目录或文件), vfsmount代表一个挂载的某种文件系统,它包含它自己的root dentry(比如rootfs的root dentry,就是’/’目录的dentry)。
Kernel的入口函数为start_kernel() /* init/main.c */

setup_arch():
这个函数主要是将bootloader给kernel的参数保存到command_line。
parse_early_param():
解析来自bootloader的参数,只涉及early params.
parse_early_param() -> parse_early_options() -> do_early_param()

do_early_param()取在[__setup_start, __setup_end]之间的obs_kernel_param参数,如果该参数设置early为1,且是bootloader传入的参数,则调用setup_func()来处理。
那么,问题随之而来,__setup_start这段地址之间的数据在哪里定义?
为了讲清楚这个,我们就要先来讲一讲kernel image是如果安排image数据的(text, data, bss等)
Kernel的image在link的时候,安排了各数据的位置,比如text段, data 段的数据,各个数据段的位置的安排是由arch/x86/kernel/vmlinux.lds.S来决定,这个vmlinux.lds.S是一个链接脚本文件(ld script),连接器使用它来链接各个section.
我们来看一下这个vmlinux.lds.S是怎么设置各个section的。
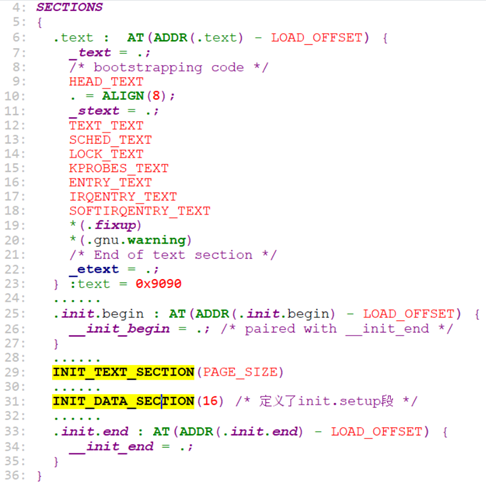
这个文件定义了所有的.text和.data段。我们看一下
INIT_TEXT_SECTION()和INIT_DATA_SECTION()的定义。
INIT_TEXT_SECTION()在文件include/asm-generic/vmlinux.lds.h.

INIT_TEXT_SECTION定义了.init.text段的地址。

INIT_TEXT又定义了段.init.text, .text.startup.
在include/linux/init.h中有如下定义:
#define __init __section(.init.text) __cold notrace
所以,内核中所有用__init修饰的函数,都被放在了这个.init.text段,即
INIT_TEXT_SECTION段中。
再来看另外一个:INIT_DATA_SECTION()

类似的,这里定义了.init.data段地址。里面的INIT_SETUP又定义新的段: .init.setup

并且这个init.setup段导出了符号__setup_start和__setup_end,即这两个符号所在的位置代表了.init.setup段中的数据。do_early_param()解析时,就是和这个段中的数据比较,取对应参数的段数据,读取其中的fn地址,并调用fn。我们看一下.init.setup段放了些什么样的数据。
在文件include/linux/init.h中,有个定义__setup().
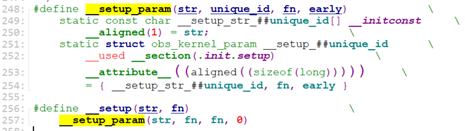
从这里我们看出,__setup修饰的被放在了.init.setup段, 所以.init.setup中放的数据就是__setup()修饰的,kernel在早期内核参数解析do_early_param()时取(__setup_start, __setup_end)地址处的struct obs_kernel_param[] 的结构中的函数fn。
我们来看几个__setup()数据。
/* init/do_mounts.c */

root_dev_setup,用于将”root=/dev/hda1”参数拷贝到saved_root_name中。

fs_names_setup, 用于设置根文件系统rootfs类型root_fs_names */
说完INIT_SETUP, 来看一下INIT_CALLS。 INIT_CALLS也定义了新段:


可见,这里定义了下面这些段:
.initcall0.init, .initcall0s.init
.initcall1.init, .initcall1s.init
.initcall2.init, .initcall2s.init
.initcall3.init, .initcall3s.init
.initcall4.init, .initcall4s.init
initcall5.init, .initcall5s.init
.initcallrootfs.init, .initcallrootfss.init
.initcall6.init, .initcall6s.init
.initcall7.init .initcall7s.init
vfs_caches_init:


sysfs_init:
sysfs_init主要就是注册sysfs文件系统。
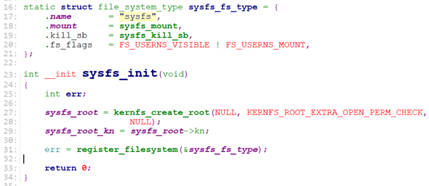
这个sysfs_fs_type定义了当mount一个sysfs类型的文件系统时调用的mount函数sysfs_mount.
init_rootfs:
init_rootfs和 sysfs_init一样,注册了rootfs文件系统。并且还注册了ramfs文件系统。
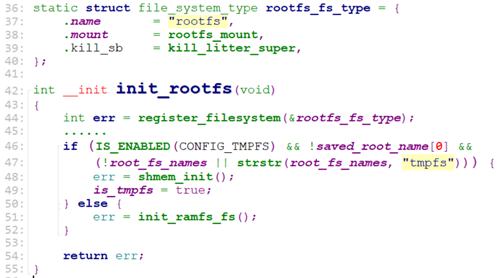
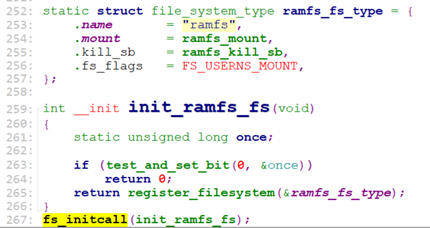
Init_ramfs_fs是被fs_initcall修饰的,所以在do_basic_setup的时候就会被调用。
到这里位置,我们还没有创建任何目录,也没有挂在任何文件系统设备。
我们来到mnt_init最后一个函数调用:init_mount_tree
init_mount_tree的工作就是使用rootfs文件系统来创建我们的第一个目录: 根目录’/’。
在接下去之前,我们先来了解下内核对文件的描述和表达。
从内核的角度来看,内核要找文件,不需要文件名。设备上的数据组织格式如下:

/* include/linux/fs.h */

struct inode结构中,这个i_mode表明当前的dentry/inode对应的是普通文件,目录,FIFO, SOCK,字符设备,块设备,链接。
/* include/uapi/linux/stat.h */
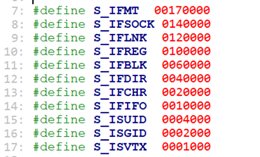
对于实际的文件(dentry.d_inode.i_mode == S_IFREG),这个d_inode间接代表这个文件的内容(通过inode句柄i_op,取出设备上对应的数据块block中数据。)
如果denty是个目录,d_inode间接指向的数据结构,后面我们会讲到,这里先略过。
假设我们要open(“/home/softdev/log.txt”): open对应的系统调用如下:
/* fs/open.c */

内核首先在进程控制块task_struct中分配一个fd:
struct task_struct { /* include/linux/sched.h */
……
struct files_struct *files;
……
};
struct files_struct { /* include/linux/fdtable.h */
……
/* open返回的就是这个数组的索引 */
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
}

进程中的文件描述符fd是一个struct file*[]的索引。
然后内核将文件路径名转成nameidata结构并申请一个struct file内存:
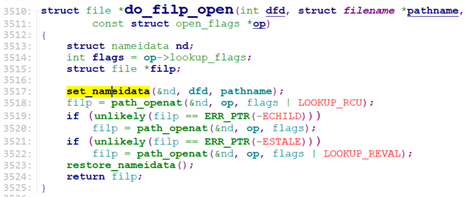
之后从当前进程的root dentry(‘/’ 根目录)查找这个文件:
path_openat() -> path_init()
/* fs/namei.c */
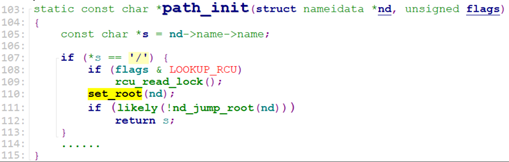
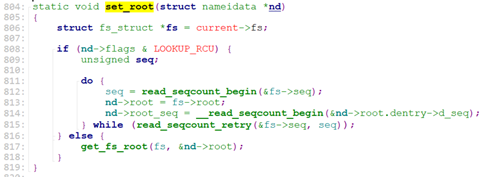
current->fs->root的结构如下:

查找过程:
link_path_walk() -> walk_component() -> lookup_fast() -> __d_lookup_rcu() -> d_hash()
先计算‘home’的hash,从hash表中找到这个’home’对应的dentry:

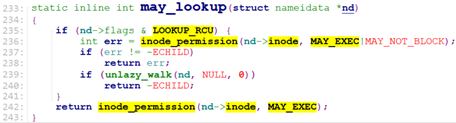
对于路径上的每一个dentry指向的inode,要检查是否有可执行权限X,没有可执行权限,就没有权限获取inode的内容。这个检查发生在path_init.

找到’home’的dentry后,再找’softdev’的dentry, 最终找到这个文件‘log.txt’对应的dentry。
找到’log.txt’的dentry后,将file和’log.txt’的dentry->d_inode关联起来。
do_last() -> vfs_open() -> do_dentry_open()
/* fs/open.c */
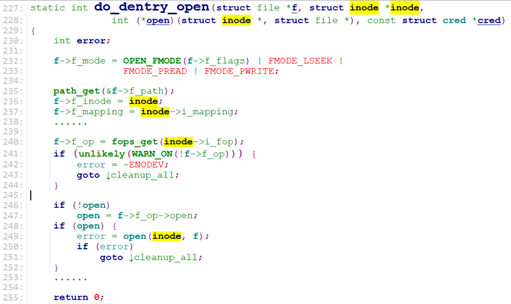
函数open()的主要工作就是加载文件的inode,后面的read(), write(),就可以直接使用文件的inode的操作函数来read/write了。
do_dentry_open()会调用inode的open函数。Inode的open做了什么?我们在后面的例子中会详细介绍。
init_mount_tree:
init_mount_tree主要工作是创建了我们第一个目录: 根目录 ‘/’。
它首次按获取之前注册的rootfs文件系统,通过vfs_kern_mount()间接调用该文件系统的mount函数,来为’/’目录创建对应的dentry & vfsmount, 最后将当前进程的pwd&root都指向这个 ‘/’的dentry&vfsmount.
/* fs/namespace.c */

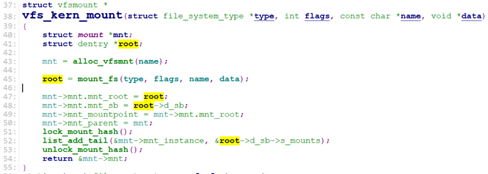
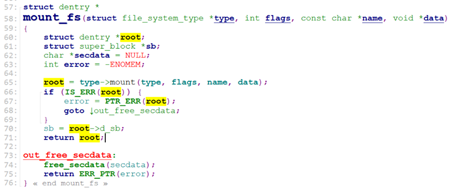
对于rootfs,这里的type->mount就是rootfs_mount。
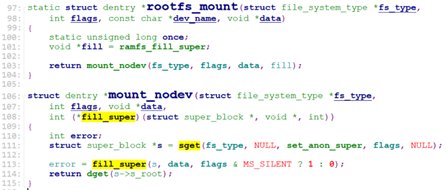
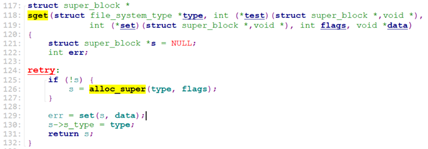
rootfs使用的就是ramfs的操作,即操作的是内存设备。

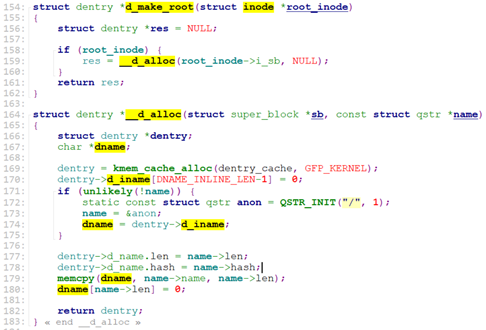
d_make_root的主要工作就是创建”/”目录的dentry.
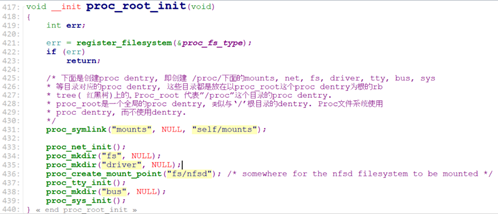
proc_root_init:
start_kernel接着取注册proc文件系统。

/* fs/proc/root.c */
nsfs_init:
创建“nsfs”的vfsmount挂载文件系统,文件系统类型为nsfs, 创建它的root dentry, 目录名为“nsfs:”
rest_init:
rest_init用于做剩余的工作,它会创建第一个内核thread, 该内核thread用于剩下的初始化工作, 并run init进程。
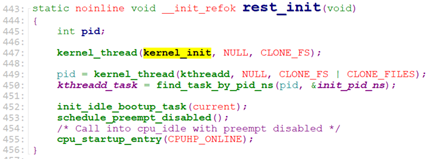
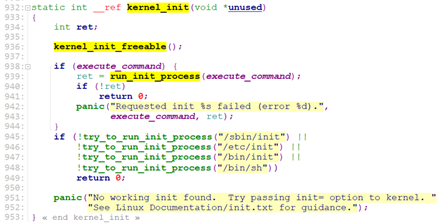
我们来看看初始化函数 kernel_init_freeable().

do_pre_smp_initcalls()调用所有载initcall.start 到initcall0.start这个段之间的函数, 即调用放在initcallearly.init段中的函数。

那么,放在initcalleartly.init段中的有哪些函数?
我们看include/linux/init.h中的定义:

所以所有用early_initcall()修饰的函数,都放在这个段。
下面列出几个early_initcall修饰的函数:
early_initcall(init_workqueues) /* kernel/workqueue.c */
early_initcall(relay_init) /* kernel/relay.c */
early_initcall(validate_x2apic) /* kernel/apic/apic.c */
我们接下去看下一个kernel_init_freeable()调用的函数do_basic_setup().
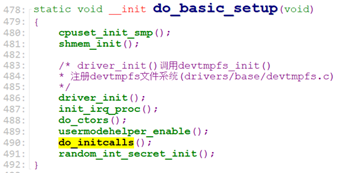
do_initcalls()调用所有载initcall0.init – initcall7.init段(共9段,initcallrootfs.init在initcall5.init和initcall6.init之间)中的所有函数。



在include/linux/init.h中定义了这些段的修饰符:
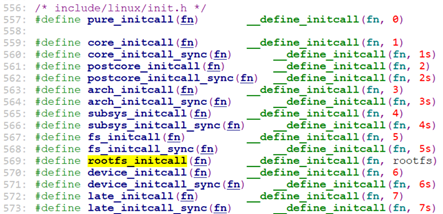
和根文件系统有关的就是rootfs_initcall()。
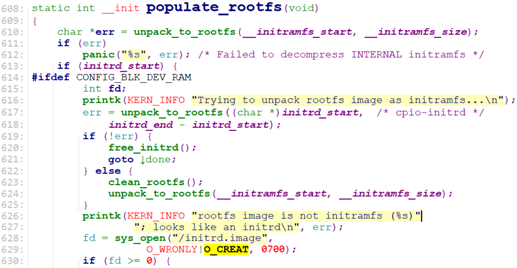
当我们配置INITRD时,即CONFIG_BLK_DEV_INITRD=y, rootfs_initcall为populate_rootfs
rootfs_initcall(populate_rootfs); /* init/initramfs.c */
否则使用(比如initramfs)
rootfs_initcall(default_rootfs); /* init/noinitramfs.c */
接下来,我们介绍下内核挂载根设备的操作。
内核挂载真正的根设备时,有三种方式:
通过内核启动参数root来指定(比如root =/dev/hda, rootfstype=ext4)这种方式需要将hda的驱动加载进来,bootloader设置root参数。内核会调用prepare_namespace()来mount根设备。Init进程程序可由参数init=来指定。
这种方式下,CONFIG_BLK_DEV_INITRD=n, 即rootfs_initcall为default_rootfs.
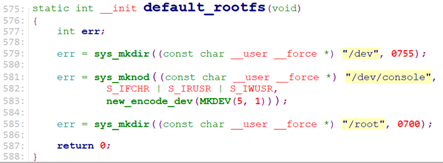
default_rootfs()只是创建了几个目录项:/dev, /dev/console, /root, 这里这个/dev/console是个字符设备,设备号为MKDEV(5,1),这是个tty设备(串口),在驱动drivers/tty/tty_io.c中注册。有了这个tty,就可以把log信息定向输出到串口设备。
kernel_init() -> kernel_init_freeable() -> do_basic_setup() -> do_initcalls() -> do_initcall_level() -> do_one_initcall() -> rootfs_initcall(default_rootfs)
kernel_init_freeable()在rootfs_initcall(default_rootfs)后,如果内核启动参数没有”init=”,则设置默认init程序为”/init”, 由于此时并没有mount任何根设备或load文件系统,所以”/init”不存在,则进入prepare_namespace()处理。

prepare_namespace从内核启动参数”root=”获取根设备名,通过name_to_dev_t,将根设备名转换为设备号,保存到ROOT_DEV中。
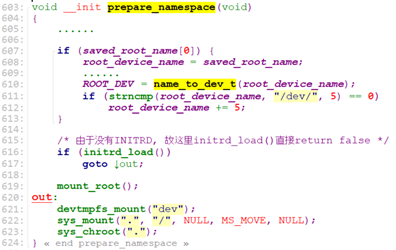

那么这里name_to_dev_t()是如何获取设备名对应的设备号呢?

blk_lookup_devt()获取已经注册的块设备(磁盘设备),比较设备名,来取对应的设备号。

比如hda设备是在驱动drivers/block/hd.c中注册的, 注册的函数在do_basic_setup()中通过do_initcall_level()来调用,level为7.
late_initcall(hd_init); /* drivers/block/hd.c */
#define late_initcall(fn) __define_initcall(fn, 7) /* include/linux/init.h */
拿到rootdev设备号后,prepare_namespace()调用mount_root(), 创建设备文件”/dev/root”, 设备号为ROOT_DEV, 然后将”/dev/root”挂载到“/root”, 文件系统类型为内核参数”rootfstype=”指定的。
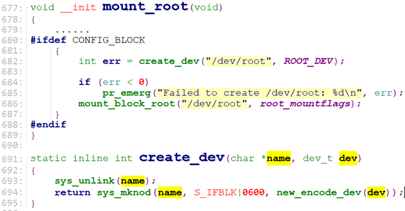


do_mount_root挂载完根设备后,切换PWD(current->fs.pwd)到”/root”目录,即切换当前目录到了根设备。
最后prepare_namespace切换root根目录为刚刚挂载的根设备。

至此,我们完成了真实根文件系统/根设备的切换。
通过initrd.Initrd称为ramdisk,即由内存虚拟的磁盘,是一个独立的小型文件系统,这个文件系统中包含/linuxrc程序,该程序/linuxrc用于加载需要的驱动模块,并mount根设备(pivot_root),之后Initrd被卸载。Initrd由prepare_namespace()来load, load之后运行它的/linuxrc程序。(需要内核配置CONFIG_BLK_DEV_RAM和CONFIG_BLK_DEV_INITRD).
initrd 的英文含义是 boot loader initialized RAM disk,就是由 boot loader 初始化的内存盘。在 linux内核启动前,boot loader 会将存储介质中的 initrd 文件加载到内存,内核启动时会在访问真正的根文件系统前先访问该内存中的 initrd 文件系统。在 boot loader 配置了 initrd 的情况下,内核启动被分成了两个阶段,第一阶段先执行 initrd 文件系统中的"init or linuxrc",完成加载驱动模块等任务,第二阶段才会执行真正的根文件系统中的 /sbin/init, Linux2.6既支持cpio-initrd,也支持image-initrd,但是cpio-initrd有着更大的优势,在使用中我们应该优先 考虑使用cpio格式的initrd.
Initrd是独立的小型文件系统,会以一个单独的文件存在,由bootloader将其加载到内存中。Initrd有两种格式,一种是传统的方式(2.4内核使用),称为image-initrd; 另外一种是cpio格式,由cpio工具生成,称为cpio-initrd。cpio-initrd和initramfs会跳过prepare_namespace(),而image-initrd则由prepare_namespace()处理.
start_kernel()->setup_arch() -> reserve_initrd() -> relocate_initrd()
/* arch/x86/kernel/setup.c */


在start_kernel的时候,initrd这个文件系统的image已经被bootloader加载的某个内存位置,并且这个内存地址传递给了kernel, kernel通过start_kernel()->setup_arch() -> reserve_initrd() -> relocate_initrd() 将image拷贝到initrd_start处。
之后,在do_basic_setup()时调用rootfs_initcall()来进一步处理。
kernel_init() -> kernel_init_freeable() -> do_basic_setup() -> do_initcalls() -> do_initcall_level() -> do_one_initcall() -> rootfs_initcall(populate_rootfs)
在使用initrd文件系统的方式下,rootfs_initcall为rootfs_initcall(populate_rootfs).
/* init/initramfs.c */
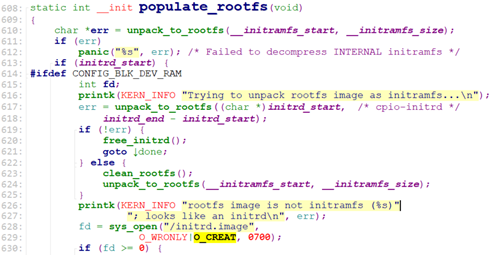
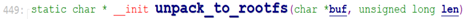

unpack_to_rootfs()只处理cpio归档,非cpio的处理不了。因此如果是image-initrd, 则unpack_to_rootfs无法解析内部文件,即解析会报错。
假设当前使用的是cpio归档,采用gzip压缩的,gzip压缩时头部前几个字节为0x1f, 0x8b, 0x08, 所以*buf不为‘0’,故程序先根据头部2字节0x1f, 0x8b,找到initrd是用gzip压缩算法,然后调用压缩算法函数去解压缩。目前内核支持的压缩算法如下:
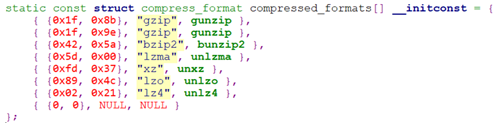
当解压缩出数据后,调用flush_buffer处理。Flush_buffer入参vbuf为解压出来的数据,len为解压出来的数据的长度。
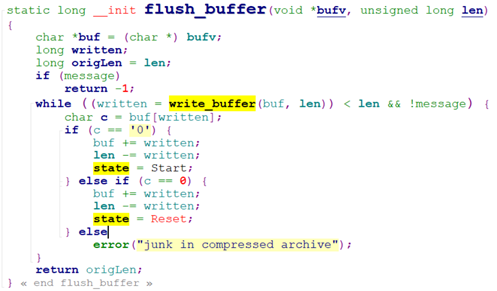
得到解压后的数据,flush_buffer调用write_buffer去解析cpio头。

actions[]()这里依次调用do_start() -> do_header()解析cpio头:
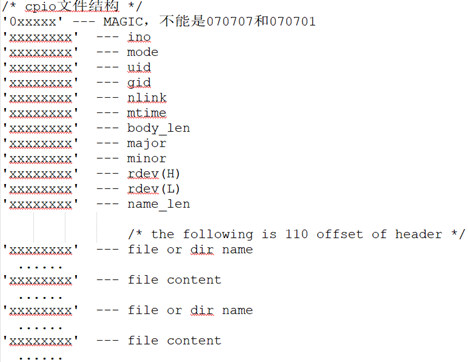
如果mode指示是个REG或者此时body_len为0,(我们假设为普通文件) 则读取name_len字节,并调用do_name。
do_name在当前的根文件系统(“rootfs”)下创建这个文件, 并截断这个文件长度为body_len。且,设置文件的uid, gid, mode等。
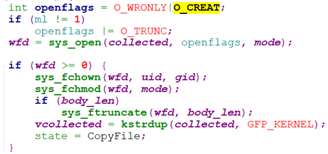
然后调用do_copy, 拷贝body_len字节数据到这个文件。
如果mode指示为DIR,则在当前文件系统下,创建这个目录:

当do_copy或者do_name之后(REG或DIR mode),write_buffer()返回。
所以,当解析一切正常时,initrd的数据被解压缩,并且kernel创建了initrd描述的所有文件和目录。
当然了如果initrd没有压缩的,那么unpack_to_rootfs则直接调用write_buffer去解析并创建对应的文件或目录。
我们回到populate_rootfs.
populate_rootfs()首先尝试去cpio的unpack initramfs,如果initramfs不存在(使用initrd), unpack_to_rootfs()返回NULL;如果使用Initrd,image已经被move到initrd_start处了,故populate_rootfs()去unpack initrd_start处的image。
当使用cpio-initrd时,unpack_to_rootfs(initrd_start)会成功,返回时程序已经将initrd中的内容移到了当前文件系统上(initrd中描述的文件和目录被在当前rootfs文件系统上创建)。
当使用image-initrd时,unpack_to_rootfs(initrd_start)会失败。然后去创建”/initrd.img”文件,并将initrd_start处的数据拷贝到这个文件。

接下来,我们回到kernel_init_freeable().
![]()

当我们使用initramfs, 或者cpio-initrd时,我们已经“复制” initramfs或initrd中的文件系统,即initramfs或initrd中的所有文件都已经move到当前文件系统rootfs中了,故”/init”文件是存在的。故initramfs/cpio-initrd时会跳过prepare_namespace(). 对于这种情况,kernel_init_freeable就返回到kernel_init中了,kernel_init则启动init进程去跑/init程序。
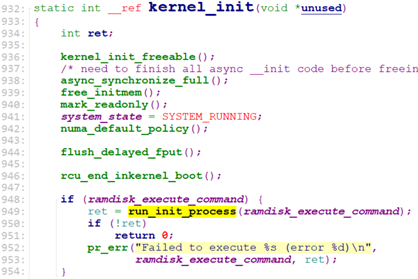
当我们使用image-initrd时,由于populate_rootfs只是创建了/initrd.img, 且导入了initrd的内容到这个文件。“/init“文件不存在,无法access。这种情况下,kernel_init_freeable在populate_rootfs返回后,进入prepare_namespace处理。
prepare_namespace()调用initrd_load去加载image-initrd.

Initrd_load先创建”/dev/ram”设备文件,然后调用rd_load_image(“/initrd.image”);
![]()
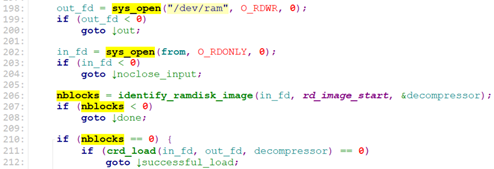
rd_load_image()打开”/dev/ram”文件,打开”/initrd.image”文件,然后调用identify_ramdisk_image. identify_ramdisk_image识别initrd, 并获取压缩格式,得到解压缩函数句柄。最后进入crd_load()。
crd_load()读取”/initrd.image”数据并 解压,然后把解压后的数据写入/dev/ram.
![]()
![]()
![]()
![]()

加载完initrd后,回到initrd_load.

对于工作站设备,root_dev就是root_ram0,不能保存数据。Initrd_load返回false,最后, prepare_namespace调用mount_root, 创建”/dev/root”, 设备号为Root_RAM0, 然后将次设备mount到”/root”, 并chdir到”/root”目录,最后调用
sys_mount(".", "/", NULL, MS_MOVE, NULL); 将当前目录移动到跟目录”/”。
最后修改task中的path,使得path的root dentry指向当前目录。
![]()

![]()
![]()
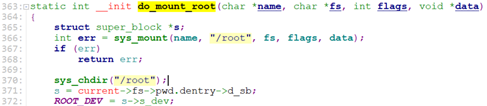
对于其他的root_dev为非ram的,则进入handle_initrd()中。
handle_initrd()创建”/dev/root.old”设备文件,关联设备为Root_RAM0, 然后将其挂载到”/root”, 并创建”/old”,切换到这个“/old“目录,然后创建一个work.
![]()
这个work会调用初始化函数init_linuxrc, init_linuxrc会切到”/root”, 即Root_RAM0设备(initrd 文件系统),并mount “/root”到根目录”/”,最后设置task path的root dentry为当前目录(即此时Root_RAM0为根文件系统)
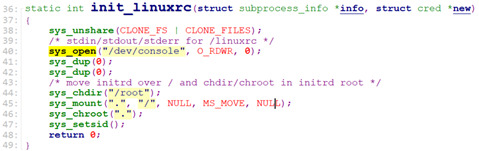
然后,这个work调用”/linuxrc”脚本,这个脚本会去加载内核module,以及mount最终的根设备(即挂载最终的根文件系统)。
完了之后,返回到prepare_namespace, 将加载的最终的根设备mount到根目录“/“, 设置task的path的root dentry 为当前根目录。
最后返回kernel_init_freeable, 并最终返回kernel_init. 在kernel_init中启动init进程。
通过initramfs.Initramfs不使用prepare_namespace()。
Initramfs是从2.5 kernel开始引入的一种新的实现机制。顾名思义,initramfs只是一种RAM filesystem而不是disk。它是一个包含在内核映像内部的cpio归档,内核启动所需的用户程序和驱动模块被归档成一个文件。它不需要cache,也不需要文件系统。 编译2.6版本的linux内核时,编译系统总会创建initramfs,然后通过连接脚本arch\x86\kernel\vmlinux.lds.S把它与编译好的内核连接成一个文件,它被链接到地址__initramfs_start~__initramfs_end处。内核源代码树中的usr目录就是专门用于构建内核中的initramfs的。缺省情况下,initramfs是空的,X86架构下的文件大小是134个字节。实际上它的含义就是:在内核镜像中附加一个cpio包,这个cpio包中包含了一个小型的文件系统,当内核启动时,内核将这个cpio包解开,并且将其中包含的文件系统释放到rootfs中,内核中的一部分初始化代码会放到这个文件系统中,作为用户层进程来执行。这样带来的明显的好处是精简了内核的初始化代码,而且使得内核的初始化过程更容易定制。
注意initramfs和initrd都可以是cpio包,可以压缩也可以不压缩。但initramfs是包含在内核映像中的,作为内核的一部分存在,因此它不会由bootloader(如grub)单独地加载,而initrd是另外单独编译生成的,是一个独立的文件,会由bootloader单独加载到RAM中内核空间以外的地址处。目前initramfs只支持cpio包格式,它会被populate_rootfs--->unpack_to_rootfs(&__initramfs_start, &__initramfs_end - &__initramfs_start, 0)函数解压、解析并拷贝到根目录。initramfs被解析处理后原始的cpio包(压缩或非压缩)所占的空间(&__initramfs_start - &__initramfs_end)是作为系统的一部分直接保留在系统中,不会被释放掉。而对于initrd镜像文件,如果没有在命令行中设置"keepinitd"命令,那么initrd镜像文件被处理后其原始文件所占的空间(initrd_end - initrd_start)将被释放掉。
Initramfs为cpio格式,和linux kernel是link成一个文件的,参考usr/initramfs_data.S。
在usr/Makefile中这么描述了cpio-initrd的生成:
调用scripts/gen_initramfs_list.sh, 这个脚本调用usr/gen_init_cpio $timestamp ${cpio_list} > ${cpio_tfile}来生成cpio-initrd的二进制文件*.o
关于initramfs的解压,挂载过程,参考initrd段的描述。
至此,linux已经找到被挂载了最终的根设备,run了系统的第一个进程,init进程。
通过上面内容的学习,我们已经知道了系统启动过程中,kernel是如何发现和挂载根设备的,接下来,我们来介绍和文件系统相关的几个系统调用: sys_mknod(), sys_open(), sys_mount(), sys_read(), sys_write().
sys_open()sys_open用于打开一个文件,或者新建一个文件。sys_open调用do_sys_open

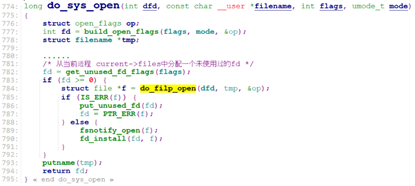
do_sys_open调用get_unused_fd_flags从current->files中分配一个fd,这个fd就是task_struct中的files_struct结构中struct file*fd_array[]的数组索引,从这个定义可以看出,一个进程能打开的最大的文件的数目为NR_OPEN_DEFAULT。

分配完fd后,调用do_filp_open()创建一个struct file, 并通过fd_install将这个sturct file放到fd_array[fd]中。
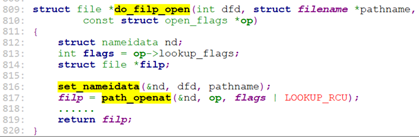
do_filp_open调用set_nameidata去构建strutct nameidata.

构建完nameidata后,调用path_openat,
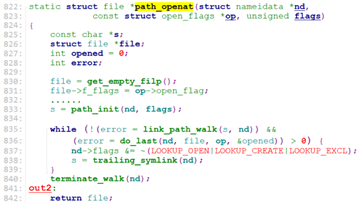
path_openat调用get_empty_filp分配一个struct file, 然后调用path_init
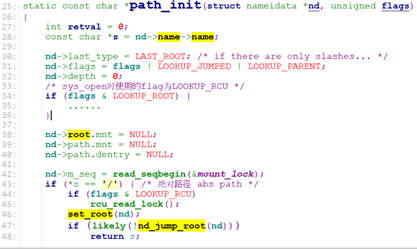
nd->name->name为open的文件路径,假设我们使用绝对路径(“/test.txt”或者”/testfiles/test.txt”), path_init调用set_root去设置nd->root为当前进程的root(current->fs->root), 这个current->fs->root包含两个信息,一个是vfsmount, 一个是denty. vfsmount为当前rootfs文件系统(或者ext4文件系统,这里假设为rootfs),dentry为该文件系统的root denty, 这里为rootfs的第一个目录”/”.

set_root之后, path_init调用nd_jump_root() 设置nd->path, nd->inode以及LOOKUP_JUMPED flags.
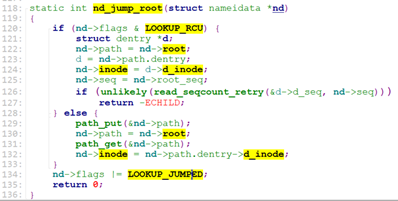
nd_jump_root之后,path_init就返回了,path_openat来到while()段:
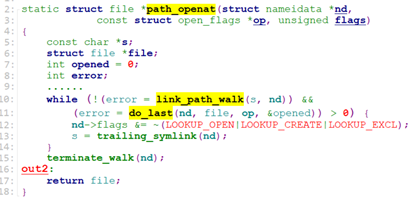
While中循环调用link_path_walk去一级一级地寻找文件的dentry.
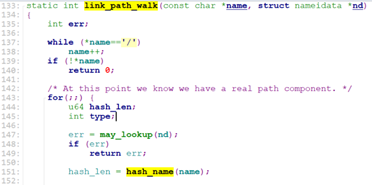
Link_path_walk首先跳过文件路径中的”/”,进入循环,调用may_lookup检查当前dentry的inode是否有可执行权限x.
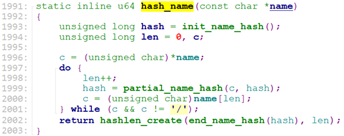
再调用hash_name计算目录的hash(比如”/test1/test2/test.txt”, 首先计算目录名”test1”的hash, 再计算目录名”test2”的hash,最后组成(dname_len << 32 | hash)返回).
![]()
计算出hash后,name指向下一个目录名,并调用walk_component()
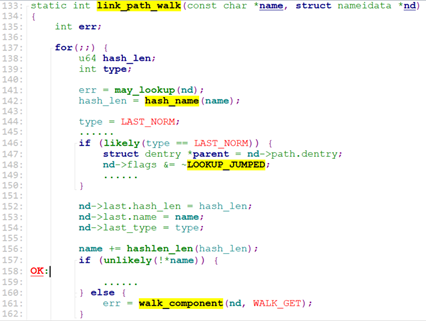
walk_component的主要任务是找到目录对应的dentry, inode, 和vfsmount(代表某个filesystem),它调用了lookup_fast来查找这三种信息。
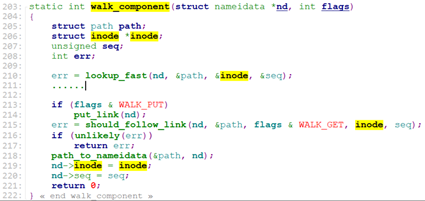
lookup_fast从当前文件系统的root dentry开始查找目录(比如”/”所在的文件系统的root dentry)

如果不存在这样的dentry,则返回0.
如果找到了,还要判断是否找到的dentry是否是挂载点,如果是,则需要修改为挂载的文件系统的vfsmount, 以及它的root dentry. 这部分的工作是由__follow_mount_rcu来做。
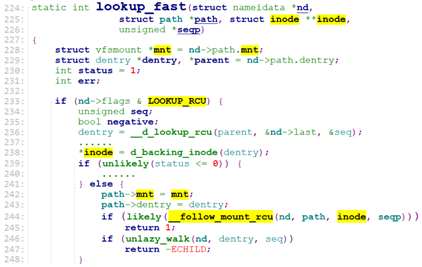
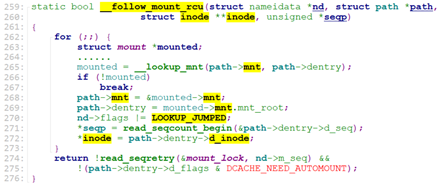
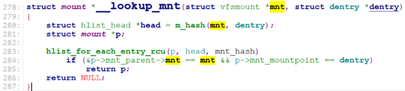
到此,我们完成了目录dentry和vfsmount的查找(不存在返回0,存在则vfsmount和dentry记录在path中)。walk_component从lookup_fast返回后,就将path中的信息转到nameidata中。

link_path_walk通过循环调用walk_component来根据path路径的一级级目录dentry找到文件所在的目录的dentry(),注意,文件的dentry并没有找出来,只找到文件所在目录(比如文件为”/test1/test2/test3/test.txt”, walk_component一次找出test1的dentry, test2的dentry, test3的dentry, 找到test3的dentry后就返回了,nd->last.name指向”test.txt”)的dentry。
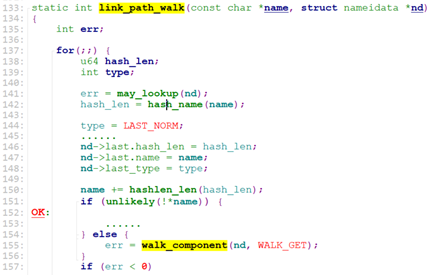
现在返回link_path_walk的上一级,
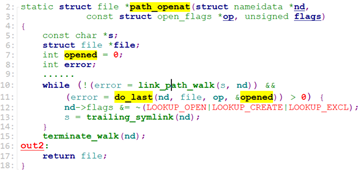
当link_path_walk正常返回0时,path_openat调用do_last
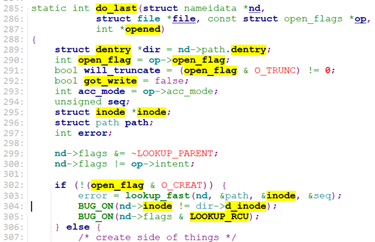
do_last调用了lookup_open.
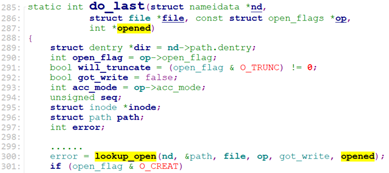
lookup_open主要是找到文件的dentry, 如果不存在,且O_CREATE(新建文件),则创建文件的dentry, 并调用文件所在最后一级目录dentry的d_inode的i_op->create去创建文件的inode.
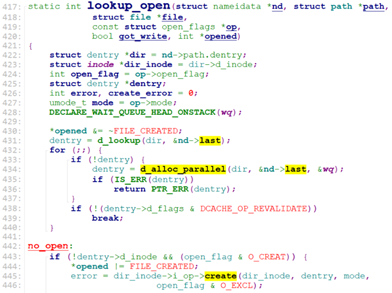
如果当前是rootfs文件系统,则dir_inode->i_op就是ramfs_file_inode_operations,定义在fs/ramfs/inode.c中。

因此对应的dir_inode->i_op->create就是ramfs_create.
![]()
ramfs_create调用ramfs_mknod创建文件的inode, 并关联dentry和inode(d_instantiate())。
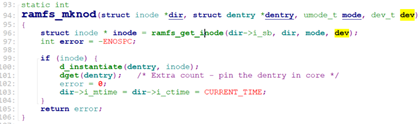
ramfs_mknod调用ramfs_get_inode创建inode,并设置inode的i_op, i_fop.
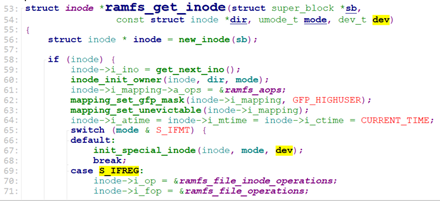
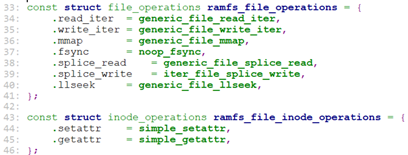
我们来看一下对于rootfs(rootfs使用ramfs的i_op, i_fop)的这两个操作的定义:
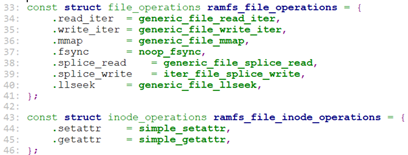
对于文件的操作,定义了read_iter, write_iter, mmp, llseek等操作。所以对于rootfs上对文件的读写,最终就是调用这里的generic_file_read_iter, generic_file_write_iter.
我们回到lookup_open, lookup_open找到文件的dentry或者创建了文件的dentry,并将其赋给path.

do_last在lookup_open之后,将path中的dentry转给nd后(path_to_nameidata),调用vfs_open。

vfs_open将path信息存储到struct file中,并调用do_dentry_open.

do_dentry_open设置struct file中f_mode,f_inode,f_op, 且如果inode->i_fop->open有效,就调用open函数。
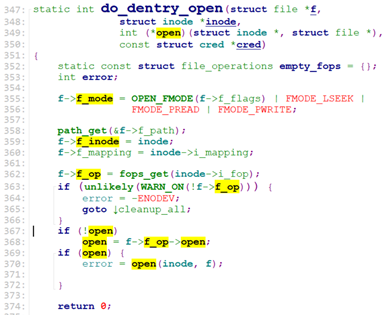
对于我们之前的rootfs而言,open函数为null。
至此,sys_open大致的过程结束了。从结果来看,sys_open就是找到文件对应的dentry, 并设置struct file中的文件操作为文件的inode->i_fop.
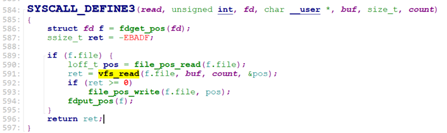
sys_read()该系统调用定义在fs/read_write.c.
sys_read首先获取struct file, 然后调用vfs_read().
vfs_read做一些检查后,调用__vfs_read.
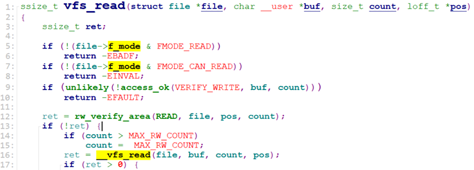
__vfs_read则直接调用了inode的read或read_iter函数。

对于rootfs,就是generic_file_read_iter(), 定义在fs/ramfs/file-mmu.c
sys_write()定义在fs/read_write.c,和sys_read()类似,最终调用了inode的write或write_iter函数
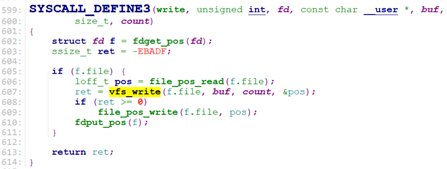
vfs_write()->__vfs_write()

定义在fs/namei.c
![]()
Mknod第一个参数filename为要创建的设备文件, 类型由mode指定,比如字符设备文件S_IFCHR,块设备文件S_IFBLK等。
sys_mknodat()也是定义在fs/namei.c
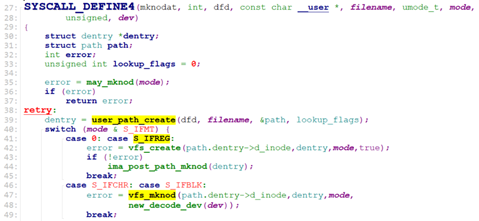
sys_mknodat调用user_path_create() -> filename_create().

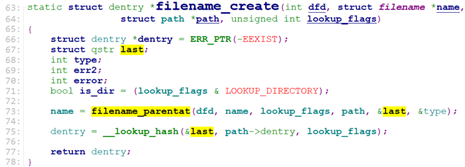
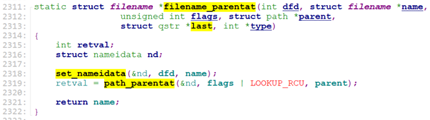
filename_create调用filename_parentat()->path_parentat()找出要创建的文件的path上的最后一级目录dentry。之后调用__lookup_hash()创建文件对应的dentry.
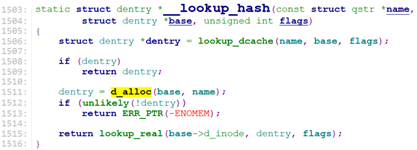
sys_mknodat通过user_path_create() -> filename_create()得到文件的dentry后(此时文件的dentry的d_inode是null的),调用vfs_mknod去创建文件的inode,并关联到文件的dentry. (我们以字符设备文件或块设备文件为例来说明)
vfs_mknod的第一个参数dir_inode是设备文件所在的最后一级目录的dentry->d_inode,第二个参数dentry为设备文件的dentry, 最后一个参数dev为设备号。
Vfs_mknod是直接调用了最后一级目录的dentry->d_inode的inode操作i_op->mknod.

对于rootfs, 这个dir->i_op->mknod就是ramfs_mknod, 定义在fs/ramfs/inode.c
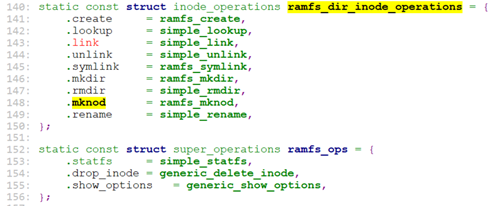
ramfs_mknod之前在open的时候介绍过了,这里简单重复下:
ramfs_mknod创建inode,并关联到dentry, 设置inode操作。

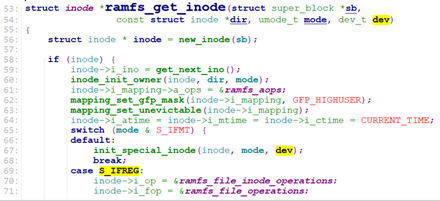
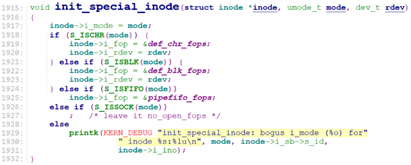
注意,我们前面约定好了,设备文件为字符设备文件或块设备文件,故ramfs_get_inode设置inod->i_fop时,进入的init_special_inode.

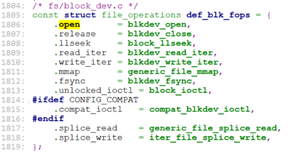
至此,sys_mknod大体上结束了。
sys_mount()定义在fs/namespace.c
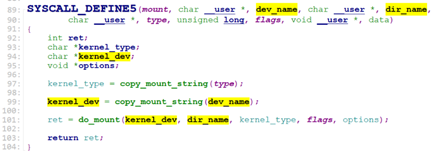
sys_mount第一个参数dev_name为设备文件(sys_mknod创建或驱动创建),第二个参数dir_name为挂载点,第三个参数type为文件系统类型。
sys_mount调用do_mount。
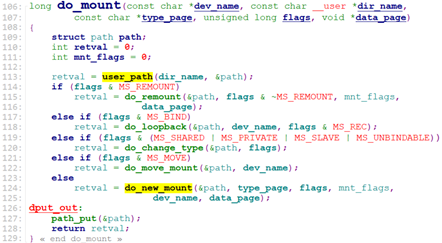
do_mount调用user_path() -> user_path_at_empty() -> filename_lookup() -> path_lookupat()来get到挂载点dir_name的dentry&vfsmount, 并存放于path中。
![]()


最后do_mount调用do_new_mount().

do_new_mount调用get_fs_type获取文件系统类型,调用vfs_kern_mount()->mount_fs()->type->mount(),来获取对应文件系统的vfsmount以及它的root dentry.
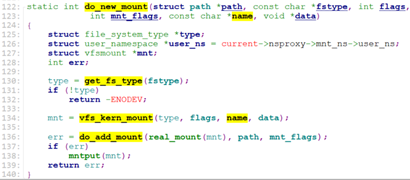
最后调用do_add_mount().

do_add_mount调用lock_mount()->new_mountpoint(path->dentry)创建一个挂载点的mp(mountpoint)。
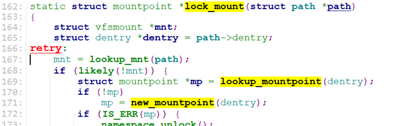
然后调用real_mount获取挂载点的vfsmount, 最后调用graft_tree()去关联设备文件vfsmount和挂载点vfsmount, 并将设备文件vfsmount关联到挂载点的mp上。
![]()


至此, sys_mount也大体结束了。
这里列一下ext4文件系统的实现:
文件在fs/ext4/super.c
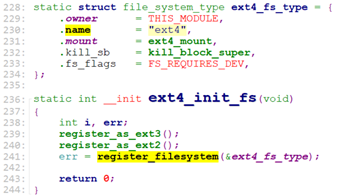
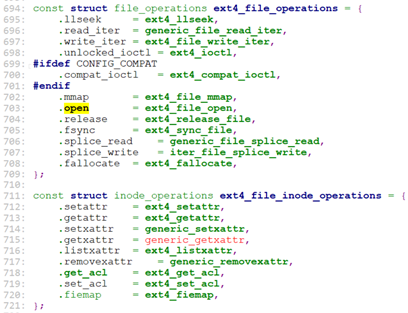
ext4文件系统的inode操作:

![]()
这里列一下对于普通文件REG的操作函数:
 shaohui973
shaohui973
 原创文章 2获赞 6访问量 1万+
关注
私信
展开阅读全文
原创文章 2获赞 6访问量 1万+
关注
私信
展开阅读全文
作者:shaohui973