Spark的安装(Standalone模式,高可用模式,基于Yarn模式)
目录
spark的Standalone模式安装
一、安装流程
1、将spark-2.2.0-bin-hadoop2.7.tgz 上传到 /usr/local/spark/ 下,然后解压
2、进入到conf中修改名字 改为 .sh 结尾的
3、编辑 spark-env.sh
4、修改slaves 的名字 并且编辑他
5、发送到其他两台虚拟机上
6、修改ect/proflie下面的配置环境
7、到spark的sbin目录下 修改启动命令
8、启动之后的jps数目
二、检测是否安装成功
1、进谷歌浏览器看看(端口号是8080 和tomcat端口号是一样的,注意后期一块启动的冲突问题)
2、按装完之后执行Spark程序进行迭代计算Spark上的PI示例
三、进入spark的shell界面操作算子
Spark高可用(先启动zookeeper再启动spark)
一、安装流程
二、高可用安装注意事项
1、先把Standalone模式注释掉
2、在后面添加配置 注意其中的间隔
3. 在node1节点上修改slaves配置文件内容指定worker节点
4.把配置好的spark 拷贝到其他节点
5.在node1上执行sbin/start-all.sh脚本,然后在node2上执行sbin/start-master.sh启动第二个Master。
三、spark高可用启动
四、高可用模式提交任务:
Spark基于yarn调度的模式 Spark on yarn
一、Yarn集群模式安装流程:
1、需要的配置项 三台都需要配
2、配置好hadoop环境变量
3.在hadoop的yarn-site中添加如下配置 三台都需要配
二、通过往spark集群上运行jar包,测试安装效果,看是否安装成功
2.1、spark-shell --master yarn-client 进yarn spark shell界面的
2.2、测试基于yarn模式能否在集群上计算π
2.3、基于yarn的两种模式(client模式和cluster模式)
三、进入shell界面操作算子
spark的Standalone模式安装 一、安装流程 1、将spark-2.2.0-bin-hadoop2.7.tgz 上传到 /usr/local/spark/ 下,然后解压 -C 是用大写C解压 到指定目录 2、进入到conf中修改名字 改为 .sh 结尾的
2、进入到conf中修改名字 改为 .sh 结尾的
 3、编辑 spark-env.sh
export JAVA_HOME=/home/xss/java/jdk
#指定spark老大Master的IP
export SPARK_MASTER_HOST=node132
#指定spark老大Master的端口
export SPARK_MASTER_PORT=7077
#woker 使用1g和1个核心进行任务处理
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=1g
4、修改slaves 的名字 并且编辑他
3、编辑 spark-env.sh
export JAVA_HOME=/home/xss/java/jdk
#指定spark老大Master的IP
export SPARK_MASTER_HOST=node132
#指定spark老大Master的端口
export SPARK_MASTER_PORT=7077
#woker 使用1g和1个核心进行任务处理
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=1g
4、修改slaves 的名字 并且编辑他

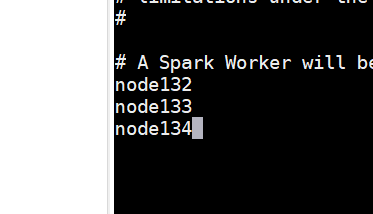 5、发送到其他两台虚拟机上
scp -r ./spark-2.2.0 node133:/usr/local/spark
scp -r ./spark-2.2.0 node134:/usr/local/spark
6、修改ect/proflie下面的配置环境
export SPARK_HOME=/usr/local/spark/spark-2.2.0
export PATH=.:$SPARK_HOME/sbin:$HBASE_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$PATH
7、到spark的sbin目录下 修改启动命令
/usr/local/spark/spark-2.2.0/sbin
修改启动命令(因为它之前的启动命令和hadoop的启动命令冲突了,所以要改它)
mv ./start-all.sh start-spark.sh
mv ./stop-all.sh stop-spark.sh
8、启动之后的jps数目
node32:
5、发送到其他两台虚拟机上
scp -r ./spark-2.2.0 node133:/usr/local/spark
scp -r ./spark-2.2.0 node134:/usr/local/spark
6、修改ect/proflie下面的配置环境
export SPARK_HOME=/usr/local/spark/spark-2.2.0
export PATH=.:$SPARK_HOME/sbin:$HBASE_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$PATH
7、到spark的sbin目录下 修改启动命令
/usr/local/spark/spark-2.2.0/sbin
修改启动命令(因为它之前的启动命令和hadoop的启动命令冲突了,所以要改它)
mv ./start-all.sh start-spark.sh
mv ./stop-all.sh stop-spark.sh
8、启动之后的jps数目
node32: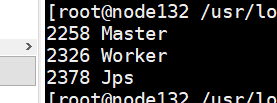 node133/node34:
node133/node34: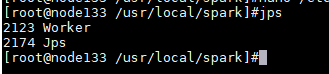 二、检测是否安装成功
1、进谷歌浏览器看看(端口号是8080 和tomcat端口号是一样的,注意后期一块启动的冲突问题)
node132:8080
2、按装完之后执行Spark程序进行迭代计算Spark上的PI示例
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node132:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.2.0.jar \
100
三、进入spark的shell界面操作算子
spark/bin 目录下 ./spark-shell 回车
二、检测是否安装成功
1、进谷歌浏览器看看(端口号是8080 和tomcat端口号是一样的,注意后期一块启动的冲突问题)
node132:8080
2、按装完之后执行Spark程序进行迭代计算Spark上的PI示例
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node132:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.2.0.jar \
100
三、进入spark的shell界面操作算子
spark/bin 目录下 ./spark-shell 回车
|
Spark高可用(先启动zookeeper再启动spark)
来源网址: file:///F:/vm/老師錄屏/stage4/spark/高可用spark提交任务.docx
作者: ℡XSs
|