机器学习(MACHINE LEARNING) 【周志华版-”西瓜书“-笔记】 DAY14-概率图模型
14.1 隐马尔可夫模型
隐马尔科夫模型(HMM)及Viterbi算法实现
隐马尔科夫模型通过给定观察序列,预测隐藏序列,常用于需要从序列的表面信息挖掘隐藏信息的任务,例如语音识别、手写识别。原则上,隐马尔科夫模型还可进行诸如词性标注、中文分词等任务,但由于混淆矩阵的高宽同时由观察序列的种类数量决定,当运用到大型语料库时,词集的大小动辄上万,则混淆矩阵需要存储上亿的参数,对计算机而言不论是运行次数还是内存占用都是灾难性的;同时,隐马尔科夫模型的一大假设是,当前时间步长的隐状态只和当前时刻的显状态以及上一时刻的隐状态相关,而实际情况是,词语的含义和标注形式同时受上下文多个词语的影响,因此,隐马尔科夫模型在该类 NLP 任务上被迅速淘汰,机会转让给条件随机场等破除该时间依赖关系假设的模型。
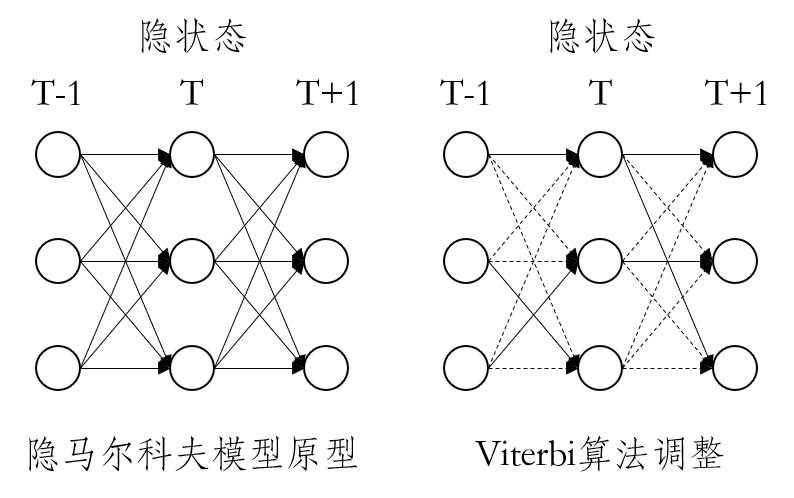
Viterbi 算法在动态规划领域用于寻求最大概率路径。隐马尔科夫模型对当前时间步长某一类隐状态的预测实际上是基于将上一时刻隐状态进行转移后,加总所有可能性而得出的;Viterbi 算法对该思路进行调整,将上一时刻隐状态进行转移后,仅取其中概率最大的路径。如下图所示:
import numpy as np
class HMM(object):
'''
算法原理:
- 训练
依据统计学条件分布原理生成隐状态边缘分布、转移矩阵以及混淆矩阵
- 预测
i.将全局隐状态概率分布与混淆矩阵中显状态对应的列相乘预测初始时刻隐状态分布
ii.进入下一个时间步长,将上一时刻的隐状态分布与转移矩阵相乘
iii.将相乘的结果与混淆矩阵中该时刻显状态对应的列相乘预测该时刻隐状态分布
iii.循环第ii、iii步.
- 预测(Viterbi)
i.将全局隐状态概率分布与混淆矩阵中显状态对应的列相乘预测初始时刻隐状态分布
ii.进入下一个时间步长,将上一时刻的隐状态分布与转移矩阵中的元素相乘,取最大值
iii.将最大概率序列与混淆矩阵中该时刻显状态对应的列相乘预测该时刻隐状态分布
iii.循环第ii、iii步.
'''
def __init__(self):
self.train = None #训练集显状态序列
self.label = None #训练集隐状态序列
self.prob = None #全局隐状态边缘分布
self.trans = None #转移矩阵(row:T时刻隐状态 col:T+1时刻隐状态)
self.emit = None #发射(混淆)矩阵(row:隐状态 col:显状态)
def fit(self,train,label):
'''导入训练集,生成全局隐状态边缘分布、转移矩阵以及混淆矩阵'''
assert isinstance(train,list)
assert isinstance(label,list)
assert len(train) == len(label)
self.train = train
self.label = label
self.cal_prob()
self.cal_trans()
self.cal_emit()
def cal_prob(self):
'''生成全局隐状态边缘分布'''
prob = np.zeros(max(self.label)+1)
for y in set(self.label):
prob[y] += float(self.label.count(y)/len(self.label))
self.prob = np.mat(prob)
def cal_trans(self):
'''生成转移矩阵'''
trans = np.zeros((len(set(self.label)),len(set(self.label))))
last = self.label[0]
for y in self.label[1:]:
trans[last,y] += 1
last = y
self.trans = np.mat([row/row.sum() for row in trans])
def cal_emit(self):
'''生成发射(混淆)矩阵'''
emit = np.zeros((len(set(self.label)),len(set(self.train))))
for x,y in zip(self.train,self.label):
emit[y,x] += 1
self.emit = np.mat([row/row.sum() for row in emit])
def predict(self,test):
'''依据显状态预测隐状态序列'''
assert isinstance(test,list)
assert len(set(test)-set(np.arange(self.emit.shape[1]))) == 0
seq = []
for t in range(len(test)):
if t == 0:
pred = np.multiply(self.prob,self.emit[:,test[t]].T) #预测初始时刻隐状态
else:
pred = np.multiply(pred*self.trans,self.emit[:,test[t]].T) #预测T时刻隐状态
pred = pred/(pred.sum()+1e-12) #防止计算下限溢出
seq.append(pred.argmax())
return seq
def viterbi_predict(self,test):
'''Viterbi算法调整'''
assert isinstance(test,list)
assert len(set(test)-set(np.arange(self.emit.shape[1]))) == 0
seq = []
for t in range(len(test)):
if t == 0:
pred = np.multiply(self.prob,self.emit[:,test[t]].T) #预测初始时刻隐状态
else:
pred = np.mat([(pred[0,y]*self.trans[:,y]).max() for y in range(pred.shape[1])]) #在原模型上添加此行
pred = np.multiply(pred,self.emit[:,test[t]].T) #预测T时刻隐状态
pred = pred/(pred.sum()+1e-12) #防止计算下限溢出
t+=1
seq.append(pred.argmax())
return seq
if __name__ == '__main__':
train = [0,5,2,6,4,3,2,0,5,1,5,1,2,5,2,0,2,0,2,3,6,4,6,4,2,5,1,0,2,5]
label = [1,0,2,1,2,1,2,2,0,2,0,1,0,0,2,1,1,2,2,0,1,2,0,2,1,2,0,0,0,1]
test = [0,2,3,6,3,1,1,2,2,5,1,5,4,2,3,6,2,5,0,5,2]
model = HMM()
model.fit(train,label) #模型训练
print('Prediction result (original): %s'%model.predict(test)) #模型预测
print('Prediction result (Viterbi): %s'%model.viterbi_predict(test)) #模型预测(Viterbi)

14.2 马尔可夫随机场
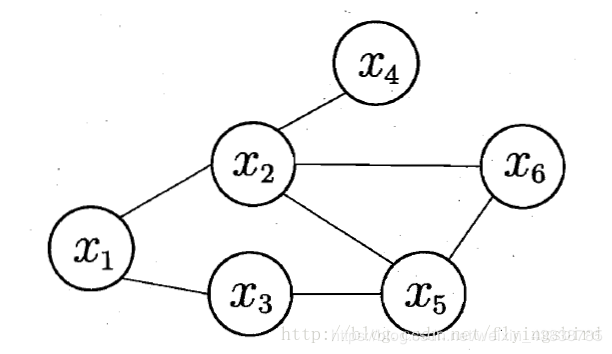
马尔可夫随机场(Markov Random Field,简称MRF)是典型的马尔可夫网,这是一种著名的无相图模型。图中每个节点表示一个或一组变量,节点之间的边表示两个变量之间的依赖关系。马尔可夫随机场有一组势函数(potential functions),亦称“因子”(factor),这是定义在变量子集上的非负实函数,主要用于定义概率分布函数。
一个简单的马尔可夫随机场
14.3 条件随机场
CRF即条件随机场(Conditional Random Fields),是在给定一组输入随机变量条件下另外一组输出随机变量的条件概率分布模型,它是一种判别式的概率无向图模型,既然是判别式,那就是对条件概率分布建模。
CRF较多用在自然语言处理和图像处理领域,在NLP中,它是用于标注和划分序列数据的概率化模型,根据CRF的定义,相对序列就是给定观测序列X和输出序列Y,然后通过定义条件概率P(Y|X)来描述模型。
CRF的输出随机变量假设是一个无向图模型或者马尔科夫随机场,而输入随机变量作为条件不假设为马尔科夫随机场,CRF的图模型结构理论上可以任意给定,但我们常见的是定义在线性链上的特殊的条件随机场,称为线性链条件随机场。

14.4 学习与推断

14.5 近似推断

14.6 话题模型
1、LDA数学定义
1)话题模型:传统的文本分类器,比如贝叶斯、kNN和SVM,只能将其分到一个确定的类别中。假设我给出3个分类“算法”“分词”“文学”让其判断,如果某个分类器将该文归入算法类,我觉得还凑合,如果分入分词,那我觉得这个分类器不够准确。
假设一个文艺小青年来看我的博客,他完全不懂算法和分词,自然也给不出具体的备选类别,有没有一种模型能够告诉这个白痴,这篇文章很可能(80%)是在讲算法,也可能(19%)是在讲分词,几乎不可能(1%)是在讲其它主题呢?
有,这样的模型就是话题模型。
作者:理想007