Flink笔记(二十):Flink 之 State 状态介绍
Flink 架构体系的一大特性是:有状态计算。
计算过程中产生的中间结果,并提供后续的 Function 或 算子计算结果使用
状态:任务内部数据(计算数据和元数据属性)的快照。在计算过程中会进行持久化,保存有任务中间计算结果的数据。
2.State作用
1、实时任务每次计算,需要基于上一次计算结果,所以需要通过 State 将任务每次计算的中间结果进行持久化。
2、任务执行出现错误时,需要从成功的检查点(CheckPoint)中,根据 State 数据进行恢复
3、Flink 增量计算、Failover 机制等,都需要 State 的支撑。
3.State存储实现 1.基于JobManager内存的 HeapStateBackend:在 debug 模式下使用,不建议在生产环境使用;
2.基于 HDFS 的 FsStateBackend:分布式文件持久化,每次读写都产生网络 IO,整体性能不佳;
3.基于RocksDB 的 RocksDBStaeBackend:本地文件+异步HDFS持久化;
4.还有一个是基于 Niagara(Alibaba 内部实现)NiagaraStateBackend:分布式持久化,在Alibaba 生产环境应用。
提示:此部分内容,同 Flink笔记(十八):Flink 之 StateBackend 介绍 & 使用
State 按照是否根据 KeyBy() 分组操作,可以分为 KeyedState 和 OperatorState。两者都支持并行度发生变化时,进行状态数据的重新分配。
KeyedState 是与 Key 相关的一种 State,只能用于 KeyedStream 类型数据集对应的 Transformation 算子操作之上。
KeyedState 是 OperatorState 的特例。区别是 KeyedState 事先按照 Key 对数据进行分区,每个 KeyState 仅对应一个 Key(即:分组之后,每个组都会有一个 KeyedState 用于状态数据存储)
OperatorState 只与 Transformation 算子实例绑定,每个算子实例中持有所有数据元素中的一部分状态数据
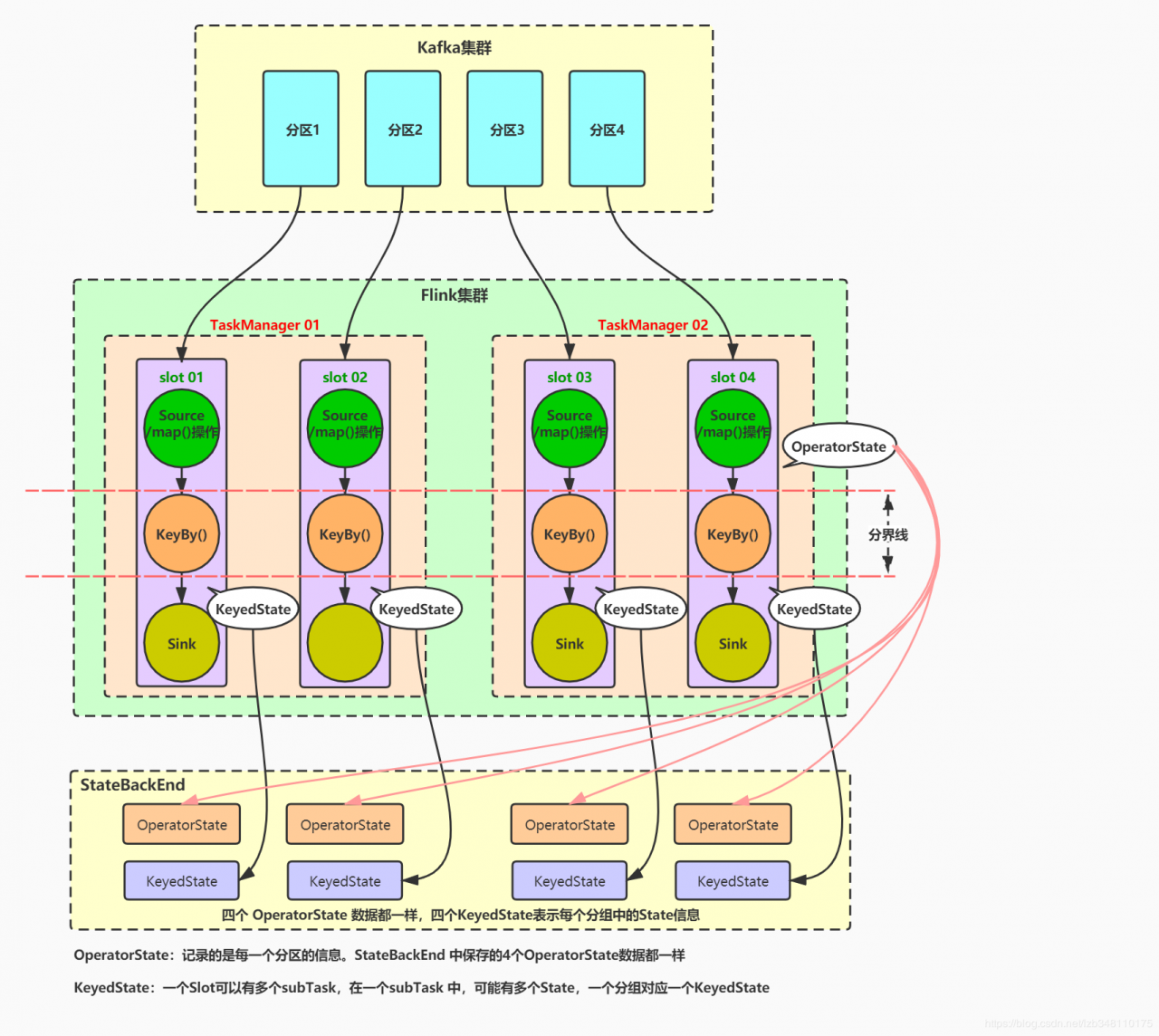
5.KeyedState 和 OperatorState 图示 场景: Flink 从 Kafka 集群中读取数据(读取到的是一行一个单词),并对读取到的数据进行 KeyBy() 分组求和操作。本例集群配置为:Flink集群 2 个TaskManager,4 个Slot,任务开启4个并行度。Kafka集群 4 个分区。
1.整体图:
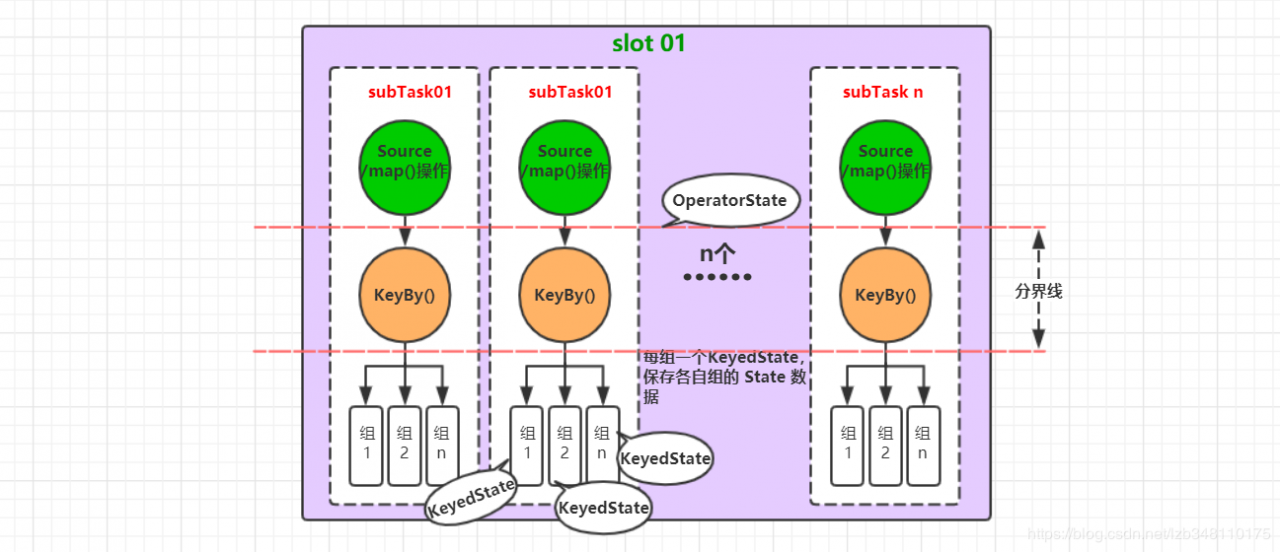
2.Slot && Task关系图:
一个 Slot 可以有多个 subTask,每个 subTask 中执行 keyBy()操作后,又会分成多个组。分组前为 OperatorState,分组后为KeyedState。每个组中都会各自存储一个 KeyedState,保存有当前分组中的中间数据。
请参考:
Flink 之 OperatorState的使用 Flink 之 KeyedState 的使用Flink 之 State 状态,介绍到此为止
文章都是博主用心编写,如果本文对你有所帮助,那就给我点个赞呗 ^ _ ^
End
作者:扛麻袋的少年