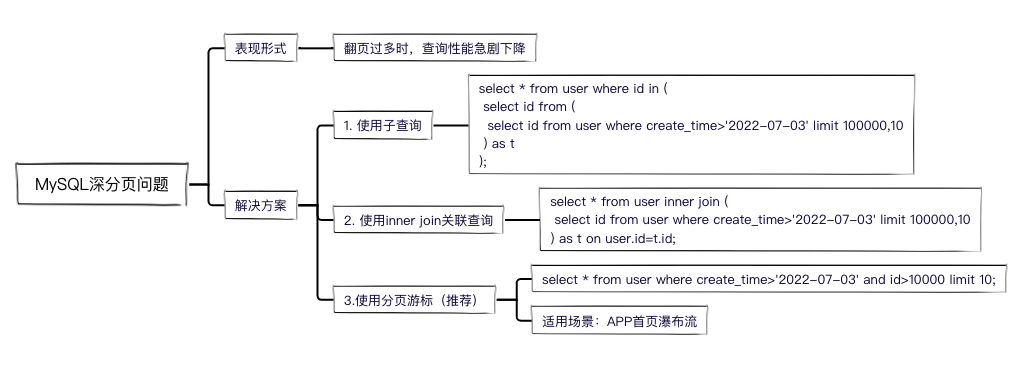
提高MySQL深分页查询效率的三种方案
开发经常遇到分页查询的需求,但是当翻页过多的时候,就会产生深分页,导致查询效率急剧下降。有没有什么办法,能解决深分页的问题呢?本文总结了三种优化方案,查询效率直接提升10倍,一起学习一下。
开发经常遇到分页查询的需求,但是当翻页过多的时候,就会产生深分页,导致查询效率急剧下降。
有没有什么办法,能解决深分页的问题呢?
本文总结了三种优化方案,查询效率直接提升10倍,一起学习一下。
1. 准备数据先创建一张用户表,只在create_time字段上加索引:
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(255) DEFAULT NULL COMMENT '姓名',
`create_time` timestamp NULL DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `idx_create_time` (`create_time`)
) ENGINE=InnoDB COMMENT='用户表';
然后往用户表中插入100万条测试数据,这里可以使用存储过程:
drop PROCEDURE IF EXISTS insertData;
DELIMITER $$
create procedure insertData()
begin
declare i int default 1;
while i <= 100000 do
INSERT into user (name,create_time) VALUES (CONCAT("name",i), now());
set i = i + 1;
end while;
end $$
call insertData() $$
2. 验证深分页问题
每页10条,当我们查询第一页的时候,速度很快:
select * from user
where create_time>'2022-07-03'
limit 0,10;

在不到0.01秒内直接返回了,所以没显示出执行时间。
当我们翻到第10000页的时候,查询效率急剧下降:
select * from user
where create_time>'2022-07-03'
limit 100000,10;
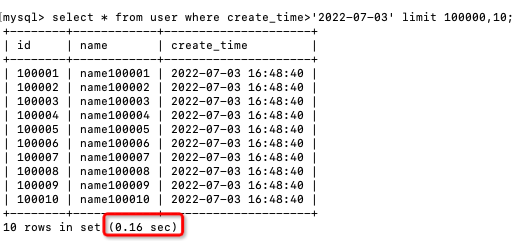
执行时间变成了0.16秒,性能至少下降了几十倍。
耗时主要花在哪里了?
需要扫描前10条数据,数据量较大,比较耗时
create_time是非聚簇索引,需要先查询出主键ID,再回表查询,通过主键ID查询出所有字段
画一下回表查询流程:
1. 先通过create_time查询出主键ID
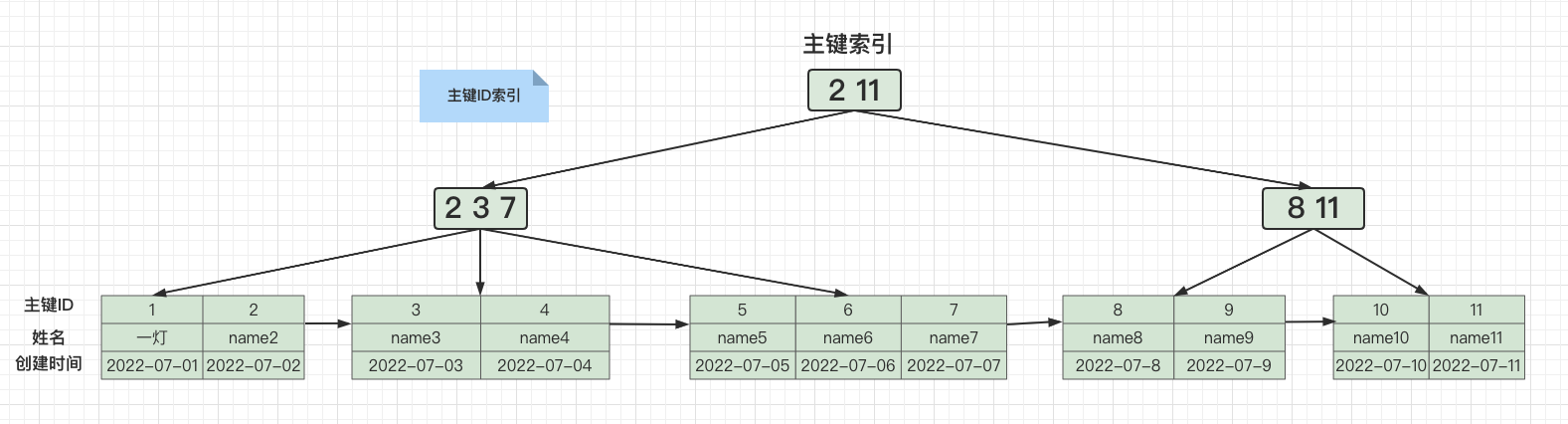
别问为什么B+树的结构是这样的?问就是规定。
可以看一下前两篇文章。
然后我们就针对这两个耗时原因进行优化。
3. 优化查询 3.1 使用子查询先用子查询查出符合条件的主键,再用主键ID做条件查出所有字段。
select * from user
where id in (
select id from user
where create_time>'2022-07-03'
limit 100000,10
);
不过这样查询会报错,说是子查询中不支持使用limit。

我们加一层子查询嵌套,就可以了:
select * from user
where id in (
select id from (
select id from user
where create_time>'2022-07-03'
limit 100000,10
) as t
);

执行时间缩短到0.05秒,减少了0.12秒,相当于查询性能提升了3倍。
为什么先用子查询查出符合条件的主键ID,就能缩短查询时间呢?
我们用explain查看一下执行计划就明白了:
explain select * from user
where id in (
select id from (
select id from user
where create_time>'2022-07-03'
limit 100000,10
) as t
);

可以看到Extra列显示子查询中用到Using index,表示用到了覆盖索引,所以子查询无需回表查询,加快了查询效率。
3.2 使用inner join关联查询把子查询的结果当成一张临时表,然后和原表进行关联查询。
select * from user
inner join (
select id from user
where create_time>'2022-07-03'
limit 100000,10
) as t on user.id=t.id;
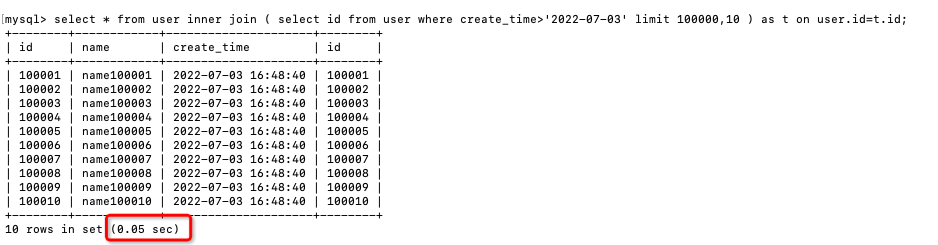
查询性能跟使用子查询一样。
3.3 使用分页游标(推荐)实现方式就是:当我们查询第二页的时候,把第一页的查询结果放到第二页的查询条件中。
例如:首先查询第一页
select * from user
where create_time>'2022-07-03'
limit 10;
然后查询第二页,把第一页的查询结果放到第二页查询条件中:
select * from user
where create_time>'2022-07-03' and id>10
limit 10;
这样相当于每次都是查询第一页,也就不存在深分页的问题了,推荐使用。
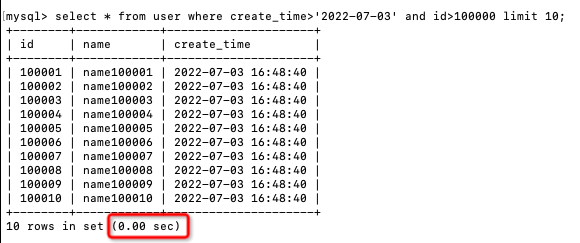
执行耗时是0秒,查询性能直接提升了几十倍。
这样的查询方式虽然好用,但是又带来一个问题,就是跳转到指定页数,只能一页页向下翻。
所以这种查询只适合特定场景,比如资讯类APP的首页。
互联网APP一般采用瀑布流的形式,比如百度首页、头条首页,都是一直向下滑动翻页,并没有跳转到制定页数的需求。
不信的话,可以看一下,这是头条的瀑布流:

传参中带了上一页的查询结果。
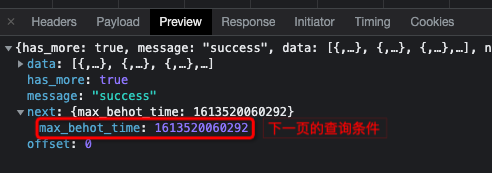
响应数据中,返回了下一页查询条件。
所以这种查询方式的应用场景还是挺广的,赶快用起来吧。
知识点总结:
到此这篇关于解决MySQL深分页低效率问题的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持软件开发网。