机器学习分类算法总结
knn算法的原生实现
knn算法的一般步骤:
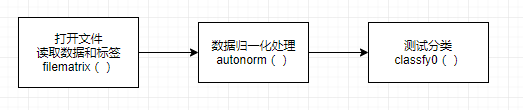
其中测试分类classfy0()函数是算法的核心,需默背下来,并且能够运用到其他的数据集上。
classify0函数流程图
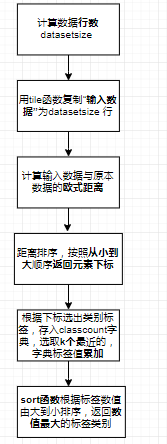
注意classfy0()函数中一些语句的用法:
distance.argsort() : 将distance元素从大到小顺序的下标返回
classcount.get(votelabel, 0) + 1 :classcount字典中如果没有votelabel则字典classCount中生成voteIlabel元素,并使其对应的数字为0,然后加1;如果有votelabe,取出值对应值,然后加1(0不起作用)
sorted(classcount.items(), key=operator.itemgetter(1), reverse=True): 其中.items将字典分解为元祖列表;operator.itemgetter(1)按位置为1的元素进行排序;reverse=True从大到小排序
classfy0()代码如下:(knn完整算法请见前期的博客)
def classify0(inx, dataset, labels, k): # inX是你要输入的要分类的“坐标”,dataSet是上面createDataSet的array,
# 就是已经有的,分类过的坐标,label是相应分类的标签,k是KNN,k近邻里面的k
datasetsize = dataset.shape[0] # dataSetSize是dataSet的行数,用上面的举例就是4行
# .min(0) 读取每行最小值.max(0) .shape[0]计算行数 .min(1) 读取每列最小值.max(1) .shape[1]计算列数
diffmat = tile(inx, (datasetsize, 1)) - dataset # 前面用tile,把一行inX变成4行一模一样的(tile有重复的功能,
# dataSetSize是重复4遍,后面的1保证重复完了是4行,而不是一行里有四个一样的),
# 然后再减去dataSet,是为了求两点的距离,先要坐标相减,这个就是坐标相减
sqdiffmat = diffmat ** 2
sqdistances = sqdiffmat.sum(axis=1) # axis=1是行相加,这样得到了(x1-x2)^2+(y1-y2)^2
distance = sqdistances ** 0.5 # 这样求出来就是欧式距离
sorteddistanceindicies = distance.argsort() # argsort是排序,将元素按照由小到大的顺序返回下标,比如([3,1,2]),它返回的就是([1,2,0])
classcount = {}
for i in range(k):
votelabel = labels[sorteddistanceindicies[i]]
classcount[votelabel] = classcount.get(votelabel, 0) + 1 # 求每个类别的个数,有‘A’就让'A'的计数加1
sortclass = sorted(classcount.items(), key=operator.itemgetter(1),
reverse=True) # classCount.items()将classCount字典分解为元组列表 ,operator.itemgetter(1)按照第二个元素的次序对元组进行排序,reverse=True是逆序,即按照从大到小的顺序排列
return sortclass[0][0] # 第一个就是最大的,返回最大的类别就是预测的类别
Knn算法的sklearn实现:
默背模块导入函数:
from sklearn.neighbors import KNeighborsClassifier as KNN:导入KNN模块;KNN.fit(train_x,train_y)训练数据、标签学习,KNN.predict(数据):进行预测
from sklearn.preprocessing import LabelEncoder 对数据进行编码
LabelEncoder .inverse_transform(数据)用于将序列化数据还原
from sklearn.preprocessing import StandardScaler 数据标准化
from sklearn.model_selection import train_test_split 构建测试数据和训练数据
from sklearn.preprocessing import MinMaxScaler 数据大小归一化
代码如下:
from sklearn.model_selection import train_test_split
from numpy import *
from sklearn.neighbors import KNeighborsClassifier as kNN
from sklearn.preprocessing import MinMaxScaler
def filematrix(filename):
fr=open(filename) #打开文件
arrayoflines=fr.readlines() #读取文件
numberoflines=len(arrayoflines) #得到文件的行数
returnmat=zeros((numberoflines,3)) #returnmat是一个numberoflines行3列的0矩阵,用来存放feature
classlabelvector=[] #设置一个空list来存label
index=0
for line in arrayoflines: #一行一行读数据
line=line.strip() #截取所有回车字符 strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
listfromline=line.split('\t') #将上一步得到的整行数据分割成一个列表
returnmat[index,:]=listfromline[0:3] #注意矩阵的索引和列表的索引 #1-3列是特征列,依次将特征存放到returnmat中
#下面两行代码和下下面的代码。注意输出是数字还是字符串
a = float(listfromline[-1]) # 列表转换为数字
classlabelvector.append(a) #最后一列也就是第4列是label列,存放到classlabelvector中
index+=1
return returnmat,classlabelvector #返回特征矩阵和标签列表
#测试
def datingtest():
horatio=0.10
datingdatamat,datinglabel=filematrix('datingTestSet2.txt') #打开文件,并把特征和标签都存到相应的矩阵和列表中
# 进行数据最大最小归一化处理
ss=MinMaxScaler()
normmat=ss.fit_transform(datingdatamat) #得到归一化后的数据
X_train, X_test, y_train, y_test = train_test_split(normmat, datinglabel, test_size=0.1)
neigh = kNN(n_neighbors=3, algorithm='auto')
neigh.fit(X_train,y_train)
# neigh.predict(X_test)
accuracy = neigh.score(X_test,y_test)
print(accuracy)
datingtest()
结果:
![]()
决策树算法原生实现的一般步骤:
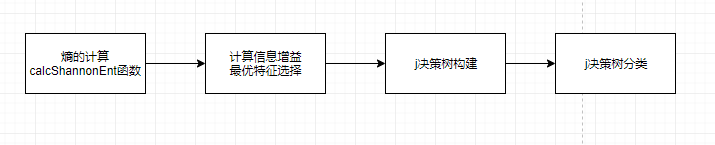
其中calcShannonEnt()函数中两个for循环较为重要,在以后的机器学习中经常会见到,第一个for:遍历出数据集的类别,并计算每个类别个数;第二个for:遍历每个类别的个数,计算熵。
代码如下:
# 计算香农熵
def calcShannonEnt(dataSet):
numEntires = len(dataSet) # 计算数据样本个数
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
labelCounts[currentLabel] = labelCounts.get(currentLabel,0)+1
shannonEnt = 0.0 # 经验熵(香农熵)
for key in labelCounts.values(): # 计算香农熵
prob = key / numEntires # 计算概率
shannonEnt -= prob * log(prob, 2) # 利用上述文本公式计算
# for key in labelCounts.keys(): # 遍历键
# prob = float(labelCounts[key]) / numEntires # 计算概率
# shannonEnt -= prob * log(prob, 2) # 利用上述文本公式计算
return shannonEnt # 返回经验熵(香农熵)
构建决策树createTree函数是算法原生实现的重点。程序流程图如下:

其中采用递归构建决策树,遍历每一个特征,遍历每个特征下不同取值:
代码如下:
# 构建决策树
def createTree(dataSet, labels, featLabels):
classList = [example[-1] for example in dataSet] #取分类标签(是否放贷:yes or no)
if classList.count(classList[0]) == len(classList): #如果数据集只有一个类别,停止分类,构建单决策树
return classList[0]
if len(dataSet[0]) == 1: #遍历完所有特征时返回出现次数最多的类标签
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) #选择最优特征
bestFeatLabel = labels[bestFeat] #最优特征的标签
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel:{}} #根据最优特征的标签生成树
del(labels[bestFeat]) #删除已经使用特征标签
featValues = [example[bestFeat] for example in dataSet] #得到训练集中所有最优特征的属性值
uniqueVals = set(featValues) #去掉重复的属性值
for value in uniqueVals: #遍历特征,创建决策树。
# 运用递归构建决策树
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), labels, featLabels)
# print(myTree)
return myTree
from sklearn.tree import DecisionTreeClassifier 使用sklearn实现决策树分类,这里不再显示。
朴素贝叶斯朴素贝叶斯算法原生实现的一般步骤:

其中trainNB0函数-贝叶斯模型参数估计为重点核心。
p0Num = zeros(numWords); p1Num = zeros(numWords);p0Denom = 2.0; p1Denom = 2.0拉普拉斯平滑,防止后面计算概率其中一个值为0,从而导致最终为0;使用log计算防止值过小。
代码:
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = zeros(numWords); p1Num = zeros(numWords)
p0Denom = 2.0; p1Denom = 2.0
# 遍历文档,向量相加
for i in range(numTrainDocs):
if trainCategory[i] == 1: # 侮辱类文档,向量相加
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else: # 非侮辱类文档向量相加
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom) #change to log()各个单词在侮辱类中出现的概率
# 计算not abusive下每个词出现的概率
p0Vect = log(p0Num/p0Denom) #change to log()各个单词在非侮辱类中出现的概率
#返回词出现的概率和文档为abusice的概率
return p0Vect,p1Vect,pAbusive
Logistic回归
logistic算法原生实现的一般步骤:

其中gradAscent()函数为核心,求解决策线的最佳系数。
流程图如下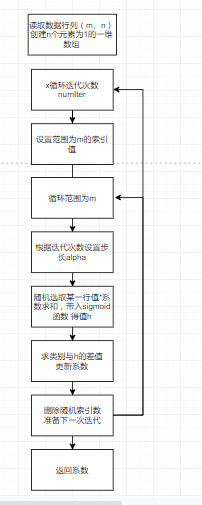
随机梯度上升算法alpha在每次迭代都会调整,通过随机选取样本更新回归系数,减少数据波动。
代码:
def gradAscent(dataMat,classlabel,numIter):
dataMat = array(dataMat) # 数组
m,n = shape(dataMat)
weights = ones(n)
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
alpha = 4/(j+i+1.0) +0.01
randIndex = int(random.uniform(0,len(dataIndex))) # 选取随机数
h = sigmoid(sum(dataMat[randIndex]*weights))
error = classlabel[randIndex] - h #计算误差
weights = weights + alpha * error * dataMat[randIndex]
del(list(dataIndex)[randIndex]) # 删除迭代后的数据
return weights
logistic算法的sklearn实现:
from sklearn.linear_model import LogisticRegression
classfier = LogisticRegression(solver=‘liblinear’,max_iter=10).fit(trainingSet,trainingLabels) max_iter为最大迭代次数
test_accuracy = classfier.score(testingSet,testingLabels)计算正确率
作者:走了又走