几分钟弄明白 BP 反向传播算法
今天有朋友咨询我反向传播算法,我觉得不需要太复杂的推导,就可以解释清楚这个算法的原理。
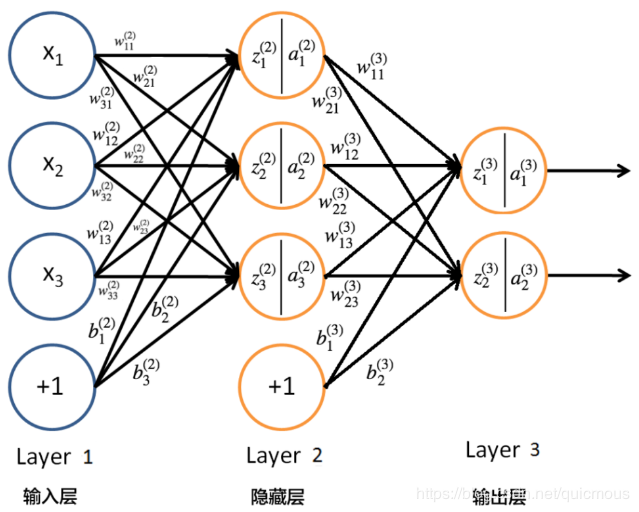
序假定神经网络采用下面的结构:
我们考虑最简单的情况:一个输入节点、一个输出节点、一个训练样本,网络结构如下图:

为了简化分析,我们假定只有一个训练样本 (x,y)(x,y)(x,y)。于是,损失函数简化为下面的形式:
E=12(y−a5)2(3)\tag3
E = \frac12(y - a_5)^2
E=21(y−a5)2(3)
其中,(x,y)(x,y)(x,y) 是训练样本、a1=xa_1=xa1=x,wiw_iwi 的初始值随机赋予,而 a5a_5a5 是网络模型输出的结果,在训练样本固定的条件下,它的值取决于权重系数 wiw_iwi,通过调整权重系数,我们可以减少 a5a_5a5 与训练样本中的结果 yyy 之间的差距。
模型中的权重系数 w2,w3,w4,w5w_2,w_3,w_4,w_5w2,w3,w4,w5 的变化影响损失函数的结果,为了利用梯度下降法使得这组权重参数从随机给出的初始值,逐步逼近到最优位置,需要求它们的偏导数。
w5w_5w5 里输出节点最近,因此求它的偏导数是最简单的,我们先进行计算。然后再依次计算前面的几个权重系数的偏导数。
注意下面这组计算非常有规律:
∂E∂w5=−(y−a5)∂a5∂w5 ∂E∂w4=−(y−a5)∂a5∂w4 ∂E∂w3=−(y−a5)∂a5∂w3 ∂E∂w2=−(y−a5)∂a5∂w2(4)\tag4
\frac{\partial E}{\partial w_5} = -(y-a_5)\frac{\partial a_5}{\partial w_5}\\
~\\
\frac{\partial E}{\partial w_4} = -(y-a_5)\frac{\partial a_5}{\partial w_4}\\
~\\
\frac{\partial E}{\partial w_3} = -(y-a_5)\frac{\partial a_5}{\partial w_3}\\
~\\
\frac{\partial E}{\partial w_2} = -(y-a_5)\frac{\partial a_5}{\partial w_2}
∂w5∂E=−(y−a5)∂w5∂a5 ∂w4∂E=−(y−a5)∂w4∂a5 ∂w3∂E=−(y−a5)∂w3∂a5 ∂w2∂E=−(y−a5)∂w2∂a5(4)
既然越往前计算,算式越长,那么,能否借助 wiw_{i}wi 的计算结果增量式地计算 wi−1w_{i-1}wi−1 的结果呢?
其实,这比较有意思。看看下面的计算过程,后面的计算,总是可以借助前面的计算结果,这样可以大大减少计算量:
∂a5∂w5=∂a5∂z5∂z5∂w5(5)\tag5
\frac{\partial a_5}{\partial w_5}={\bf\frac{\partial a_5}{\partial z_5}}\frac{\partial z_5}{\partial w_5}
∂w5∂a5=∂z5∂a5∂w5∂z5(5)
∂a5∂w4=∂a5∂z5∂z5∂w4(6)\tag6
\frac{\partial a_5}{\partial w_4}={\bf\frac{\partial a_5}{\partial z_5}}\frac{\partial z_5}
{\partial w_4}
∂w4∂a5=∂z5∂a5∂w4∂z5(6)
注意(5)、(6)两个计算式中,粗体字部分是完全相同的计算。权重的位置越靠前,重合的部分就越多,再看看下面这两个式子:
∂a5∂w3=∂a5∂z3∂z3∂w3(7)\tag7
\frac{\partial a_5}{\partial w_3}={\bf\frac{\partial a_5}{\partial z_3}}\frac{{\partial z_3}}{\partial w_3}
∂w3∂a5=∂z3∂a5∂w3∂z3(7)
∂a5∂w2=∂a5∂z3∂z3∂w2(8)\tag8
\frac{\partial a_5}{\partial w_2}={\bf\frac{\partial a_5}{\partial z_3}}\frac{{\partial z_3}}{\partial w_2}
∂w2∂a5=∂z3∂a5∂w2∂z3(8)
计算式中的粗体字部分是相同的,为了简化起见,粗体字部分计算式没展开。展开后,就是下面(9)、(10) 式的情况。注意(10)式的第一个括号部分的内容,是复用的(9)式内容,第二个括号部分的内容,是增量部分,可以用于下一个算式的计算。
实际上,从(5)式开始,后面的计算式都可以在前面的基础上,增量式地补充一部分内容就可以了,大大提高了计算效率。这个计算方法称为反向传播算法。
∂a5∂w3=(∂a5∂z5∂z5∂a4∂a4∂z3)∂z3∂w3(9)\tag9
\frac{\partial a_5}{\partial w_3}={\bf(\frac{\partial a_5}{\partial z_5}\frac{\partial z_5}{\partial a_4}\frac{\partial a_4}{\partial z_3})}\frac{\partial z_3}{\partial w_3}
∂w3∂a5=(∂z5∂a5∂a4∂z5∂z3∂a4)∂w3∂z3(9)
∂a5∂w2=(∂a5∂z5∂z5∂a4∂a4∂z3)(∂z3∂a2∂a3∂z2)∂z2∂w2(10)\tag{10}
\frac{\partial a_5}{\partial w_2}={\bf(\frac{\partial a_5}{\partial z_5}\frac{\partial z_5}{\partial a_4}\frac{\partial a_4}{\partial z_3})}(\frac{{\partial z_3}}{\partial a_2}\frac{{\partial a_3}}{\partial z_2})\frac{{\partial z_2}}{\partial w_2}
∂w2∂a5=(∂z5∂a5∂a4∂z5∂z3∂a4)(∂a2∂z3∂z2∂a3)∂w2∂z2(10)
这里举的例子太简单了,对于多个输入、多个输出、多个中间层的一般性网络模型,反向传播算法是否奏效呢?这个问题我们另行讨论。下一篇文章我计划讨论的问题是:反向传播算必须基于神经网络模型吗?
作者:quicmous