R语言中查询和分析packages的方法汇总
文章目录前言获取CRAN上package的信息根据packages的信息进行分析,可视化处理使用情况的条形图作者的关系网络图packages的关系依赖图重点!寻找需要的R包对Rpackages的另一种查找方法--packagefinder::findPackage()根据关键词在CRAN上搜索packages的信息获取每个包每月的下载量列出了每个包在其生命周期内的总下载量可视化package下载情况查找R包最简单的方法,rseek搜索引擎参考来源
前言
作者:zoujiahui_2018
各种各样的packages为R进行各种各种的工作提供了丰富的支持,了解各种package的使用情况,相互关系,有利于我们跟进技术发展的脚步也有利于知道当前分析问题的热点。
获取CRAN上package的信息library(pacman)
p_load(packagefinder)
p_load(dlstats)
p_load(cranly)
#获取CRAN上package的数据库
p_db<-tools::CRAN_package_db()
#查看有多少packages
dim(p_db)
# [1] 15438 64
#查看p_db中包的信息
View(p_db)
# 对p_db进行清洗、预处理
package_db <- clean_CRAN_db(p_db)
根据packages的信息进行分析,可视化处理
使用情况的条形图
#组建网络关系
package_network <- build_network(package_db)
package_summaries <- summary(package_network)
#做出packaages的网络关系信息做出条形图
##可以依赖的信息(according_to):names(package_summaries)
# [1] "package" "n_authors" "n_imports"
# [4] "n_imported_by" "n_suggests" "n_suggested_by"
# [7] "n_depends" "n_depended_by" "n_enhances"
# [10] "n_enhanced_by" "n_linking_to" "n_linked_by"
# [13] "betweenness" "closeness" "page_rank"
# [16] "degree" "eigen_centrality"
plot(package_summaries, according_to = "degree", top = 20)

从中可以看到目前进行R数据分析的一些常用package, 小伙伴们是不是都掌握了?请自查!
#通过build_network函数可以查看作者的关系网络,并且可以展示与某位作者相关的网络关系
author_network<-build_network(object=package_db,perspective = "author")
plot(author_network,author="JJ Allaire",exact=FALSE)
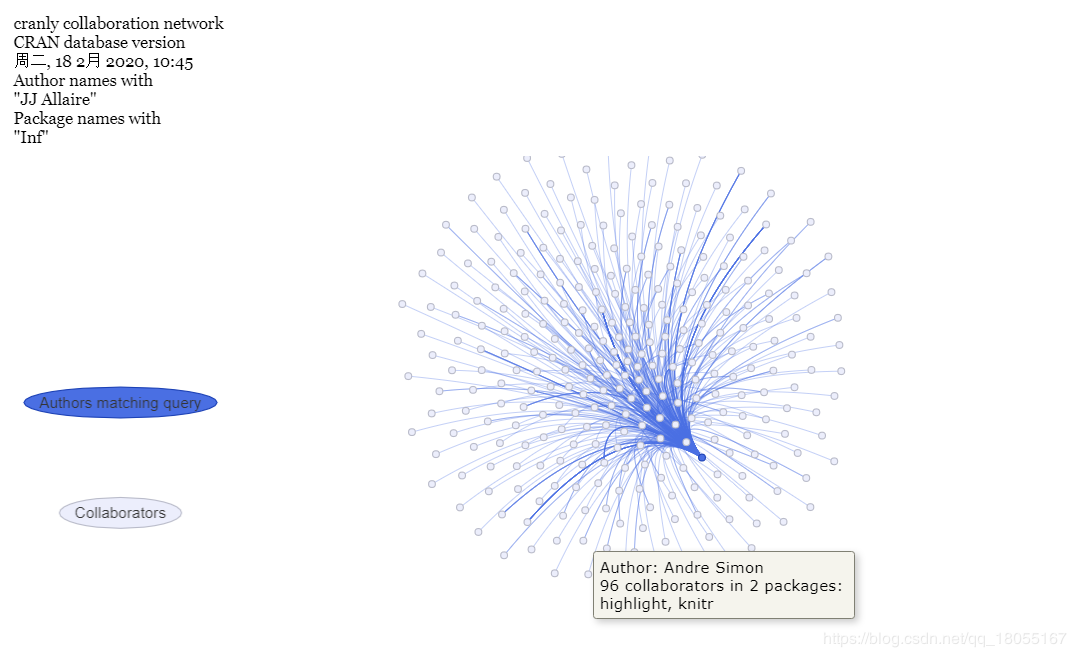
这个图是可以交互操作的,如何一个作者与其他人合作关系密切肯定就是大神,他的包可信度必然就高。
#构建cranly包的依赖关系树
xts_tree=build_dependence_tree(package_network,"ggplot2")
plot(xts_tree)
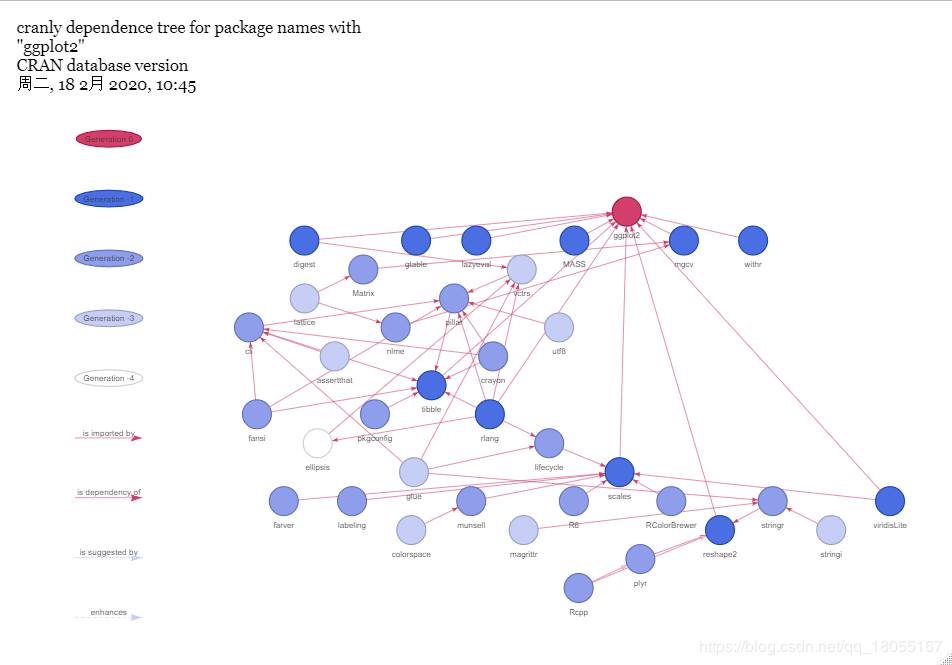
##package_with()通过预先设定关键词寻找相关R包,比如寻找带有“Bayes”
##or "MCMC"关键词的R包
Bayesian_packages=package_with(package_network,name=c("xls","trick"))
plot(package_network,package=Bayesian_packages,legend = F)

p_load(tibble)
p_load(tidyverse)
# packagefinder主要功能是帮助R使用者找到能够解决燃眉之急的R包
#packagefinder::findPackage() 支持通过关键词搜素CRAN上所有R包的元数据。
pt=as_tibble(findPackage("permutation test"))
pt
# # A tibble: 15 x 4
# SCORE NAME DESC_SHORT GO
#
# 1 100 wPerm Permutation Tests 15198
# 2 65.3 lmPerm Permutation Tests for Linear Models 7060
# 3 63.5 perm Exact or Asymptotic permutation tests 9618
# 4 55.5 flip Multivariate Permutation Tests 4324
# 5 53.7 cpt Classification Permutation Test 2376
获取每个包每月的下载量
# dlstats::cran_stats()将包名称向量作为输入,查询RStudio下载日志,并返回一个数据框,列出每个包的月份下载次数
pt_downloads <- cran_stats(pt_pkg$NAME)
# start end downloads package
# 58 2015-11-01 2015-11-30 190 wPerm
# 65 2015-12-01 2015-12-31 173 wPerm
# 72 2016-01-01 2016-01-31 236 wPerm
# 79 2016-02-01 2016-02-29 180 wPerm
# 87 2016-03-01 2016-03-31 129 wPerm
# 96 2016-04-01 2016-04-30 115 wPerm
# 105 2016-05-01 2016-05-31 113 wPerm
列出了每个包在其生命周期内的总下载量
top_downloads % group_by(package) %>%
summarize(downloads = sum(downloads)) %>%
arrange(desc(downloads))
head(top_downloads,10)
# # A tibble: 10 x 2
# package downloads
#
# 1 exactRankTests 333581
# 2 perm 126508
# 3 lmPerm 34431
# 4 flip 23641
# 5 jmuOutlier 18365
# 6 GlobalDeviance 16994
# 7 AUtests 14718
# 8 treeperm 11437
# 9 cpt 11211
# 10 wPerm 10513
可视化package下载情况
top_pkgs % filter(package %in% top_downloads$package[1:3])
ggplot(top_pkgs, aes(end, downloads, group=package, color=package)) + geom_line() + geom_point(aes(shape=package))
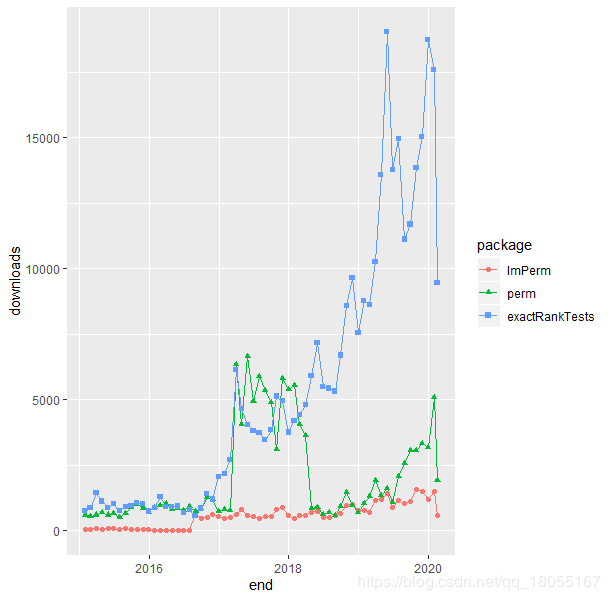
从中可以看到,实现置换检验最常用的packages,如果学习当然就使用最常用的嘛。
https://www.rdocumentation.org/
为什么把最简单的方法放最后呢?因为,不放最后,高级的方法就没人看了。
https://mp.weixin.qq.com/s/ONulutWR3a1JdPLdFq1d3w
https://mp.weixin.qq.com/s/ah9F7_0hgE3dqXsZDqljtQ
作者:zoujiahui_2018
相关文章
Fidelia
2021-01-02
Noella
2021-02-14
Serwa
2020-03-20
Rae
2023-07-22
Rhoda
2023-07-22
Hester
2023-07-22
Grace
2023-07-22
Vanna
2023-07-22
Peony
2023-07-22
Dorothy
2023-07-22
Dulcea
2023-07-22
Zandra
2023-07-22
Serafina
2023-07-24
Kathy
2023-08-08
Olivia
2023-08-08
Elina
2023-08-08
Jacinthe
2023-08-08
Viridis
2023-08-08
Hana
2023-08-08