mysql通过group by分组取最大时间对应数据的两种有效方法
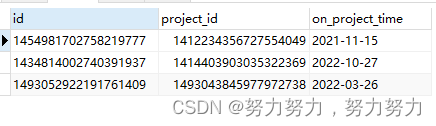
1、项目记录表project_record的结构和数据如下:

以下为项目记录表project_record的所有数据。project_id为项目Id,on_project_time为上项目时间。(每一条数据代表着上某个项目(project_id)的时间(on_project_time)记录)

2、我们的需求是:取出每个项目中最大上项目时间对应的那条数据。(即根据project_id分组,取出每组中最大的on_project_time对应的数据。)上方红框是我们要查出的数据。
3、错误代码:
SELECT *
FROM (SELECT * FROM project_record order by on_project_time desc) t
GROUP BY project_id;
查询结果错误:
结果看似正确的,实则是错误的。每个项目最大的上项目时间能正确查出,但是数据对应的id不正确。
分析发现,对于每一个分组,分组后的结果总是取组中主键(id)最小的数据,即group by project_id 总会对project_id执行排序(正序)
而不论临时表(t)中是否已排序,都会取组中主键id最小的一行数据。换句话说 临时表t 内的排序 无法影响外层的group by 的操作。
4、 正确方法如下:
方法一:
SELECT t1.*
FROM project_record t1
INNER JOIN (
SELECT DISTINCT(id) id
FROM project_record
ORDER BY on_project_time DESC) AS t2 ON t2.id = t1.id
GROUP BY t1.project_id;
查询结果正确:

思路:需要关联一张表,这个关联表t2中的数据是对原表t1按照上项目时间倒叙排列,注意,此处必须使用distinct,此处distinct的作用可以理解为将t1表数据顺序固定为t2表顺序。
主表GROUP BY 后会取出按条件分组后的第一条数据。
方法二:
select t1.*
FROM project_record t1
INNER JOIN (SELECT SUBSTRING_INDEX(GROUP_CONCAT(id ORDER BY on_project_time DESC),',',1) AS id
FROM project_record GROUP BY project_id) AS t2 ON t2.id = t1.id;
查询结果正确:

SUBSTRING_INDEX 用法:取排序后的分组的第一条数据。
本人习惯使用第一种方法。
总结
到此这篇关于mysql通过group by分组取最大时间对应数据的两种有效方法的文章就介绍到这了,更多相关mysql group by分组取对应数据内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!