sql中exists的基本用法示例
【exists语句的执行顺序如下】:
附:exists与in比较
总结:
现有:班级表(A_CLASS)

学生表( STUDENT)
注:学生表(STUDENT)的classId关联班级表(A_CLASS)的主键ID
代码:
select * from STUDENT s WHERE exists (select 1 from A_ClASS c where s.CLASS_ID=c.ID)
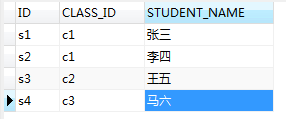
结果

1.首先会执行外循环(select * from student)
2.外循环返回的结果每一行都会拿着去内层循环执行(此时注意,内层也是循环查询的)
ps:select * from student查询的为 (c1,c1,c2,c3);此时执行顺序应该是(
第一次:select* from A_CLASS where c1=c1,第二次:select* from A_CLASS where c1=c2,
第三次:select* from A_CLASS where c1=c1,第四次:select* from A_CLASS where c1=c2,
第五次:select* from A_CLASS where c2=c1,第六次:select* from A_CLASS where c2=c2,
第七次:select* from A_CLASS where c3=c1,第八次:select* from A_CLASS where c3=c2)
注意:此时的内层子查询如果为true,则直接返回不会再继续执行本次循环;
综上所述:第二次和第四次是不会被执行的; 第一次和第三次还有第六次是符合条件的;
所以 STUDENT表中CLASS_ID字段为(c1,c2)的数据都会被查询出来;
如果将 上述语句的=换成!=会是什么效果?
select * from STUDENT s WHERE exists (select 1 from A_ClASS c where s.CLASS_ID!=c.ID)
结果如果所示:
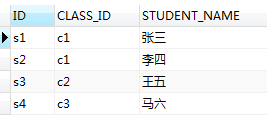
具体分析一下:此时的执行应该和第一次一模一样也是循环8次分别为:
第一次:select* from A_CLASS where c1!=c1,第二次:select* from A_CLASS where c1!=c2,
第三次:select* from A_CLASS where c1!=c1,第四次:select* from A_CLASS where c1!=c2,
第五次:select* from A_CLASS where c2!=c1,第六次:select* from A_CLASS where c2!=c2,
第七次:select* from A_CLASS where c3!=c1,第八次:select* from A_CLASS where c3!=c2
但是=换成了!=;这次是第六次和第八次没有被执行,其余的全被执行,s.CLASS_ID涉及到(c1,c2,c3)并且语句都返回了true;
所以STUDENT表中CLASS_ID字段为(c1,c2,c3)的数据都会被查询出来;
附:exists与in比较in的用法相信大家很好理解。
select * from table_name where col_name [not] in(子查询);
先运行子查询,生成结果集
再运行外查询时,判断col_name在不在子查询里,在的话则返回该行,不在则不返回。
col_name的列数和子查询的列数要相对应
当外大子小时,即查询的内容很大时,判断次数少,in优于exist【子查询小用in】
当外小子大时,即查询内容很小时,代入次数少,exists优于in【子查询大用exists】
总结:1.exists执行外循环后,会拿着外循环的值,去内层查询,如果查询到就直接返回true,并且终止本次循环,如果是false,则会一直执行,直至循环完成还为false,则本次内循环不符合条件;
2.内层的判断条件不要写!=;查询的结果会不尽人意;
到此这篇关于sql中exists基本用法的文章就介绍到这了,更多相关sql exists的用法内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!