爬虫【6】链家二手房信息和图片并保存到本地
爬虫【6】链家二手房信息和图片并保存到本地
爬虫回顾:
爬虫【1】打开网站,获取信息 爬虫【2】重构UserAgent 爬虫【3】URL地址编码 爬虫【4】爬取百度贴吧并生成静态页面 爬虫【5】爬虫猫眼电影100榜单并保存到csv 爬虫【6】链家二手房信息和图片并保存到本地 网页URL分析:首先我们打开链家二手房的网站,选择二手房页面
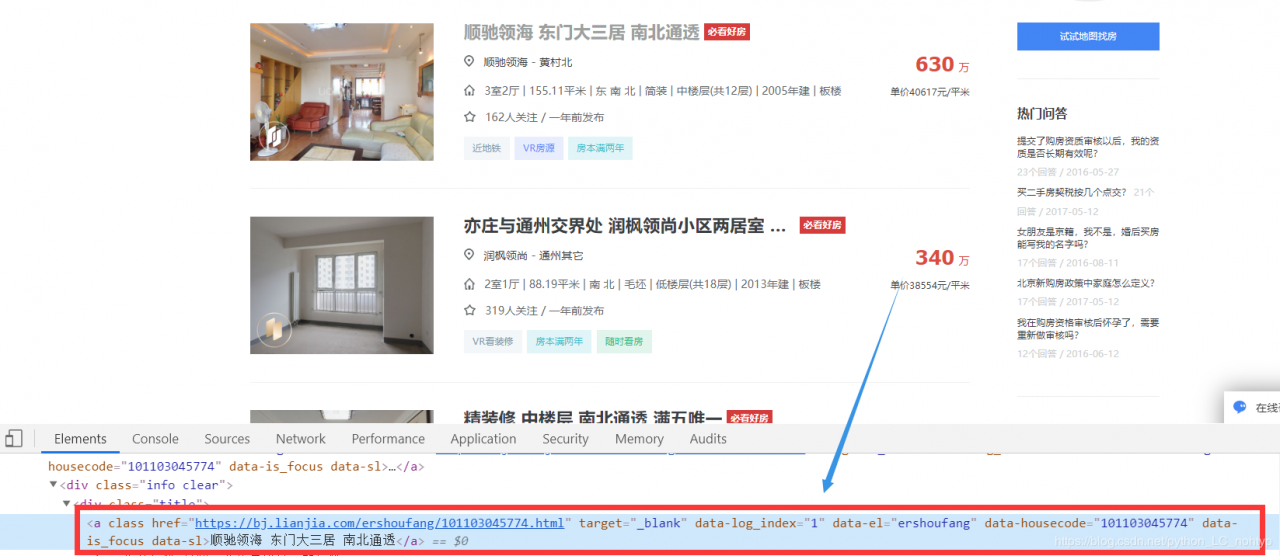
可以看到url长这个样子,当然第一步是查看网页源代码看看是不是静态页面,如果是动态js加载的就要换方法了。
我们在获取url之后可以写这样的正则代码去匹配所有的二级页面url:
def get_urls(self, html):
"""
获取二级html标签
"""
html = html.decode()
pattern = re.compile('', re.S)
urls = pattern.findall(html)
while '' in urls:
urls.remove('')
return urls
之后我们需要再获取二级界面里的url
这里我们选择获取里面的名字,价格和图片,名字和价格写入到csv文件中,图片单独的保存到文件当中。
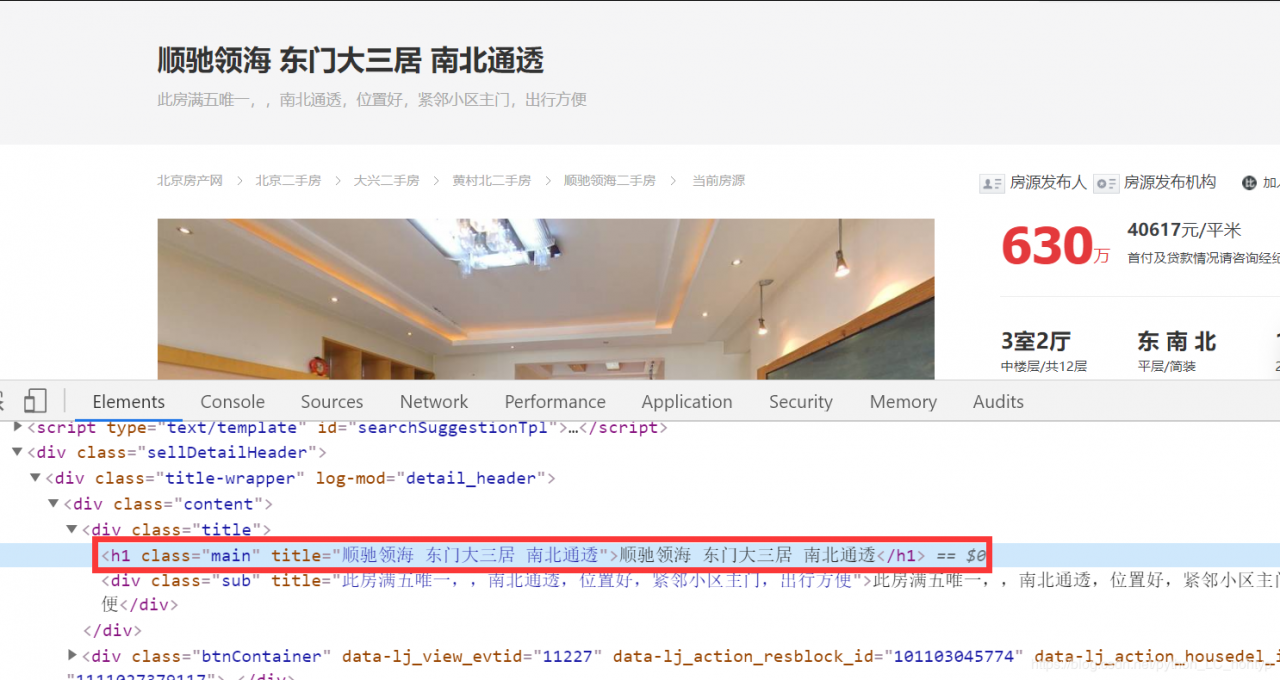
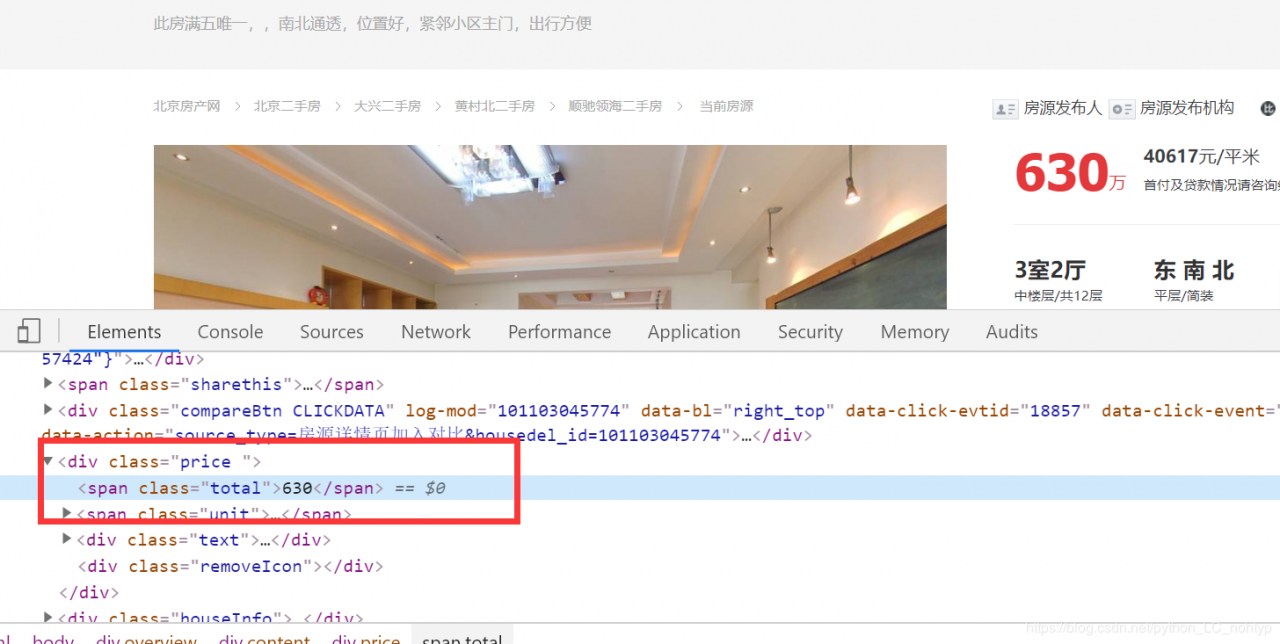
经过分析我们可以写出这样的匹配方式:
def pattern_img(self, html):
pattern = re.compile('', re.S)
return pattern.findall(html)
def pattern_html(self, html):
html = html.decode()
pattern = re.compile('(.*?)
.*?.*?>(.*?)', re.S)
info = pattern.findall(html)
images = self.pattern_img(html)
return info[0], images
保存文件
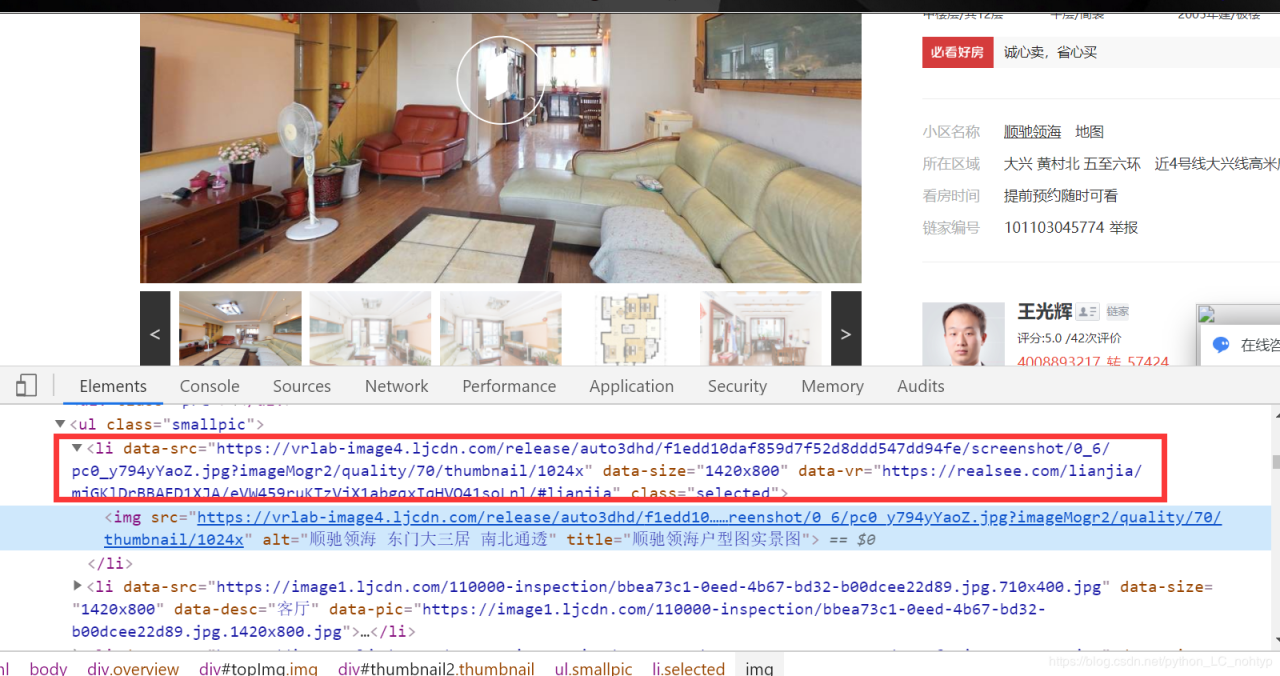
下面我们将房间信息和图片信息分别保存
def save_image(self, name, images):
directory = 'image/' + name
if not os.path.exists(directory):
os.makedirs(directory)
i = 1
for image in images:
filename = directory + '/'+str(i)+'.jpg'
html = self.get_html(image)
with open(filename, 'wb') as f:
f.write(html)
time.sleep(random.randint(2, 3))
i += 1
def write_csv(self, info):
"""
将内容保存到csv中
"""
L = []
with open('house.csv', 'a') as f:
writer = csv.writer(f)
name = info[0]
price = info[1] + '万'
L.append((name, price))
print(name, price)
writer.writerows(L)
完整代码
"""
二手房信息爬取
"""
from urllib import request, parse
from fake_useragent import UserAgent
import os, re, csv
import random, time
class HouseSpider:
def __init__(self):
self.url = 'https://bj.lianjia.com/ershoufang/'
def get_html(self, url):
"""
获取html页面信息
"""
headers = self.get_headers()
res = request.Request(url, headers=headers)
req = request.urlopen(res)
html = req.read()
return html
def get_headers(self):
"""
获取随机的headers
"""
ua = UserAgent()
headers = {'User-Agent': ua.random}
return headers
def get_urls(self, html):
"""
获取二级html标签
"""
html = html.decode()
pattern = re.compile('', re.S)
urls = pattern.findall(html)
while '' in urls:
urls.remove('')
return urls
def pattern_img(self, html):
pattern = re.compile('', re.S)
return pattern.findall(html)
def pattern_html(self, html):
html = html.decode()
pattern = re.compile('(.*?)
.*?.*?>(.*?)', re.S)
info = pattern.findall(html)
images = self.pattern_img(html)
return info[0], images
def write_csv(self, info):
"""
将内容保存到csv中
"""
L = []
with open('house.csv', 'a') as f:
writer = csv.writer(f)
name = info[0]
price = info[1] + '万'
L.append((name, price))
print(name, price)
writer.writerows(L)
def save_image(self, name, images):
directory = 'image/' + name
if not os.path.exists(directory):
os.makedirs(directory)
i = 1
for image in images:
filename = directory + '/'+str(i)+'.jpg'
html = self.get_html(image)
with open(filename, 'wb') as f:
f.write(html)
time.sleep(random.randint(2, 3))
i += 1
def run(self):
html = self.get_html(self.url)
urls = self.get_urls(html)
for url in urls:
html = self.get_html(url)
info, imgs = self.pattern_html(html)
self.write_csv(info)
self.save_image(info[0].replace(" ", ""), imgs)
time.sleep(random.randint(9, 12))
if __name__ == '__main__':
spider = HouseSpider()
spider.run()
作者:Jupiter-king