区块链Fabric 排序、二次开发
1、排序(Orderer)
排序(Orderer)指对区块链网络中不同通道产生的交易进行排序,并广播给节点(Peer)。排序(Orderer)是以可插拔组件的方式实现,目前分为SOLO和Kafka两种类型。
SOLO:仅有一个Orderer服务节点负责接收交易信息进行排序,是最简单的排序算法,一般用于测试环境。
Kafka:是由Apache软件基金会开发的一个开源流处理平台,一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,可以配置多个排序节点集群方式,以便使用在生成环境。Hyperledger Fabric利用kafka的高吞吐、低延时的特性,对交易信息进行排序处理,实现在集群内部支持节点故障容错。
正式环境中需要使用Kafka搭建,保证数据可靠性和安全性,以下介绍基于Kafka集群和ZooKeeper集群的排序服务的原理。
排序(Orderer)操作步骤:
1)在网络的创世块中写入Kafka相关的信息
在生成创世区块时,需要在configtx.yaml文件中配置Kafka相关的信息,如Orderer.OrdererType设置为kafka、Orderer.Kafka.Brokers设置Kafka集群中的节点IP地址和端口;
2)设置区块最大容量
区块最大容量在configtx.yaml文件中设置Orderer.AbsoluteMaxBytes项的值,以字节为位置,不包括区块头信息大小。
3)创建创世区块
使用 configtxgen 工具,根据步骤1和2中配置生成创世区块。
2、二次开发(SDK)
Fabric SDK提供调用账本(Ledger)、智能合约(Smart contract)、通道(Channel)、节点(Peer)、排序(Orderer)等接口,方便用第三方应用程序的开发,大大扩展了Fabric的应用场景。
Fabric提供了许多SDK来支持各种编程语言,目前正式发布了Node.js和Java两种版本的SDK。将来还会发布Python、Go、REST版本的SDK,还在测阶段。
Fabric SDK应该可以为开发人员提供编写应用程序的多种操作区块链网络的方式。应用程序可以部署/执行Chaincode,监听网络中产生的事件,接收块信息,把交易存储到账本中等。
接口模块如下:
1) Package: Hyperledger Fabric Client
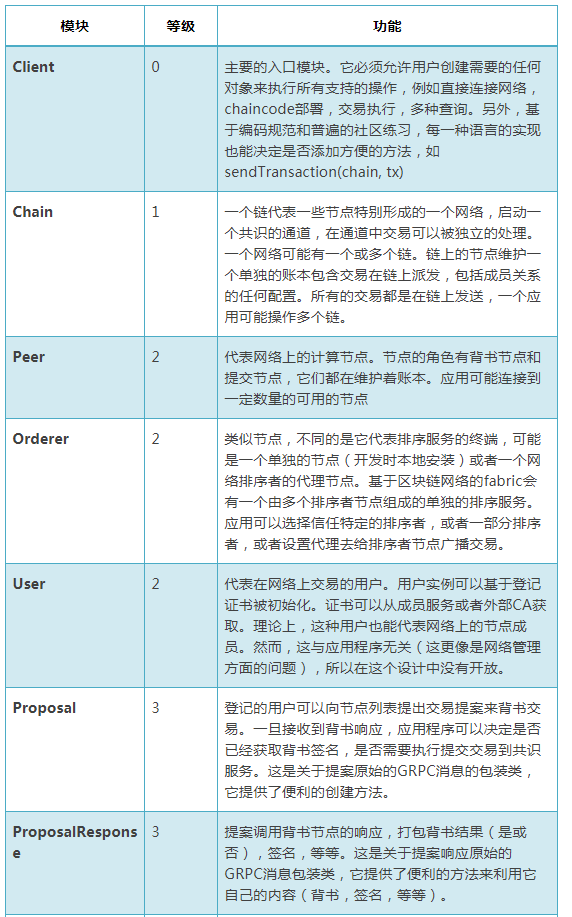

2)Package: Member Service

作者:jappy1