Elasticsearch之倒排索引
Elasticsearch通过倒排索引的数据结构来实现全文搜索
在关系数据库系统里,索引是检索数据最有效率的方式。但对于搜索引擎,它并不能满足其特殊要求,比如海量数据下比如百度或者谷歌要搜索百亿级的网页,如果使用类似关系型数据库使用的B+树索引,可想而知其对cpu的计算能力要求得有多高。其次关系型数据库中一般存储的都是结构化的数据,数据格式都是一定的,操作上一般也都是curd等比较简单的操作。
倒排索引区别于正向索引,一般的倒排索引被用来做全文搜索。比如现在有一本10w字的书,单词使用量为3k,我要从中搜索某个词出现的章节,我们该怎么做?
正排索引:遍历这本书,记录该次出现的章节。我们几乎要遍历完10w个词才能统计完。
倒排索引:建立倒排索引,将每个词作为key,该词出现的章节为value。我们只要在3k个单词中找到我们的目标词即可。
这样的话,显然倒排索引对于全文搜索性能更好。
一般的正排索引是以key找value,而倒排索引则是以value找key。反转了key-value的关系。
例如,假设我们有两个文档,每个文档的 content 域包含如下内容:
doc_1 : The quick brown fox jumped over the lazy dog
doc_2 : Quick brown foxes leap over lazy dogs in summer
为了创建倒排索引,我们首先将每个文档的 content 域拆分成单独的 词(我们称它为 词条 或 tokens),分词和标准化的过程称为分析,创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。结果如下所示:
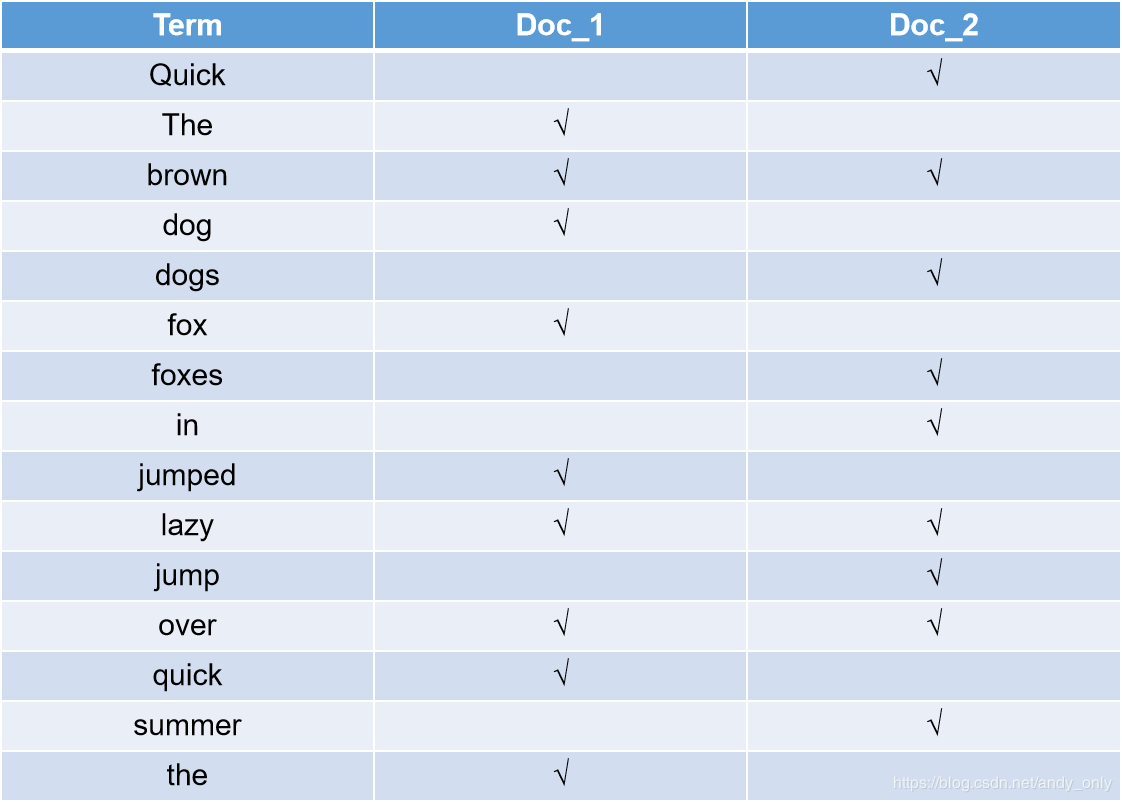
因为每个doc都是由id唯一标识的,所以其会建立一个映射关系
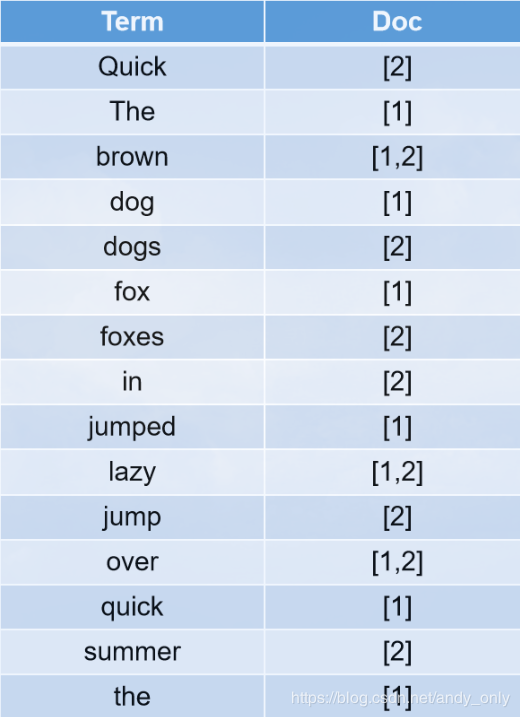
分词和标准化分析
标准分析器是Elasticsearch默认使用的分析器。它是分析各种语言文本最常用的选择。它根据 Unicode 联盟 定义的 单词边界 划分文本。删除绝大部分标点。最后,将词条小写。
大小写转换:Quick --> quick
近义词转换:mother --> mom
时态转换:jumped --> jump
单复数转换:dogs --> dog
…
我们还可以 自定义分析器 注意:不同的分词器的分词方式和算法都是不尽相同的。要注意这一点。
分析后的结果如下:
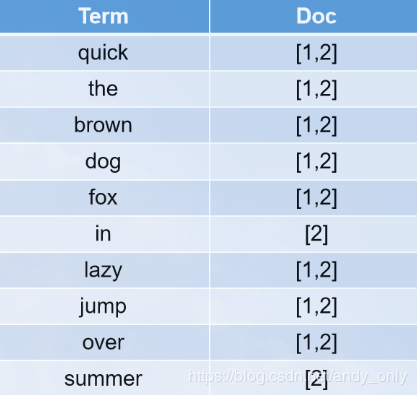
ik分词器:常用的是IKAnalyzer,但IK是第三方插件,需要安装。
IK软件包下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v5.6.16
不变性
倒排索引被写入磁盘后是 不可改变 的:它永远不会修改。 不变性有重要的价值:
当然,一个不变的索引也有不好的地方。主要事实是它是不可变的! 你不能修改它。如果你需要让一个新的文档 可被搜索,你需要重建整个索引。这要么对一个索引所能包含的数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。
评分算法
ES5.0使用BM25代替TF/IDF
Okapi BM25
能与 TF/IDF 和向量空间模型媲美的就是 Okapi BM25 ,它被认为是 当今最先进的 排序函数。 BM25 源自 概率相关模型(probabilistic relevance model) ,而不是向量空间模型,但这个算法也和 Lucene 的实用评分函数有很多共通之处。
BM25 同样使用词频、逆向文档频率以及字段长归一化,但是每个因子的定义都有细微区别。与其详细解释 BM25 公式,倒不如将关注点放在 BM25 所能带来的实际好处上。
BM25 调优
不像 TF/IDF ,BM25 有一个比较好的特性就是它提供了两个可调参数:
k1
这个参数控制着词频结果在词频饱和度中的上升速度。默认值为 1.2 。值越小饱和度变化越快,值越大饱和度变化越慢。
b
这个参数控制着字段长归一值所起的作用, 0.0 会禁用归一化, 1.0 会启用完全归一化。默认值为 0.75 。
在实践中,调试 BM25 是另外一回事, k1 和 b 的默认值适用于绝大多数文档集合,但最优值还是会因为文档集不同而有所区别,为了找到文档集合的最优值,就必须对参数进行反复修改验证。
TF-IDF算法 (term frequency–inverse document frequency)
Elasticsearch 的相似度算法被定义为检索词频率/反向文档频率, TF/IDF包括以下内容:
检索词频率
检索词在该字段出现的频率?出现频率越高,相关性也越高。 字段中出现过 5 次要比只出现过 1 次的相关性高。
反向文档频率
每个检索词在索引中出现的频率?频率越高,相关性越低。检索词出现在多数文档中会比出现在少数文档中的权重更低。
字段长度准则
字段的长度是多少?长度越长,相关性越低。 检索词出现在一个短的 title 要比同样的词出现在一个长的 content 字段权重更大。
在es中进行全文搜索时,搜索结果的匹配度也是采用的TF-IDF算法。这个匹配度是能够在es的元数据 _score 属性中体现出来的。每个文档都有相关性评分,用一个正浮点数字段 _score 来表示 。 _score 的评分越高,相关性越高;
Elasticsearch 在 每个查询语句中都有一个 explain 参数,将 explain 设为 true 就可以得到更详细的信息。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/relevance-intro.html
GET /_search?explain { “query” : { “match” : { “tweet” : “honeymoon” }}}
WARNING : 输出 explain 结果代价是十分昂贵的,它只能用作调试工具 。千万不要用于生产环境。
参考文献:
《elasticsearch-权威指南》
部分内容参考:https://www.cnblogs.com/hello-shf/p/11543460.html
作者:兮妹的傲娇