Spring Cloud集成ELK完成日志收集实战(elasticsearch、logstash、kibana)
对于日志来说,最常见的需求就是收集、存储、查询、展示,开源社区正好有相对应的开源项目:logstash(收集)、elasticsearch(存储+搜索)、kibana(展示),我们将这三个组合起来的技术称之为ELK,所以说ELK指的是Elasticsearch、Logstash、Kibana技术栈的结合。ELK对外作为一个日志管理系统的开源方案,能够可靠和安全地从任何格式的任何来源获取数据,并实时搜索、分析和可视化。
1 Elasticsearchelasticsearch是一个高可扩展的、开源的、全文本搜索和分析的引擎。它能够近乎实时地存储,检索和分析大量数据,通常用作底层引擎/技术,为具有复杂搜索特性和需求的应用程序提供动力。
elasticsearch的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
1.1节点和集群elasticsearch 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 elasticsearch 实例。单个 elasticsearch 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
1.2索引(Index)elasticsearch 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。所以,elasticsearch 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
下面的命令可以查看当前节点的所有 Index。
curl -X GET ‘http://localhost:9200/_cat/indices?v’
1.3文档(Document)索引里面的单条记录称为文档(Document),多个文档就组成了一个索引。文档是用JSON格式表示。同一个索引的文档不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。一个简单的文档示例:
{
“user”: “张三”,
“profession”: “java工程师”,
}
索引可能存储大量数据,超出单个节点的硬件限制。例如,一个包含10亿个文档的索引占用了1TB的磁盘空间,它可能不适合于单个节点的磁盘,或者可能太慢,无法单独为单个节点提供搜索请求。为了解决这个问题,Elasticsearch提供了将索引细分为多个碎片的功能。当你创建索引时,可以简单地定义你想要的碎片的数量。每个碎片本身都是一个功能齐全、独立的“索引”,可以驻留在集群中的任何节点上。
总而言之,每个索引可以分成多个碎片。一个索引也可以被复制零次(意思是没有副本)或多次。一但复制,每个索引将具有主碎片(原始碎片)和复制碎片(主碎片的副本)。在创建索引时,每个索引可以定义碎片和副本的数量。默认情况下,Elasticsearch中的每个索引分配5个主碎片和1个副本。
关于elasticsearch的深入了解请参考elastic官方网站:https://www.elastic.co/cn/
2 LogstashLogstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
2.1管道logstash的事件处理管道通常具有一个或多个的输入插件、过滤器、输出插件。logstash的事件处理通常分为三个阶段:输入→过滤器→输出。
2.2输入数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
logstash使用输入插件实现数据导入。常用的输入插件如下:
| 插件 | 说明 |
|---|---|
| tcp | 从TCP套接字读取事件 |
| http | 从http请求中读取事件 |
| file | 从文件中读取 |
| beats | 从Elastic Beats框架接收事件 |
| kafka | 从kafka中读取 |
| rabbitmq | 从rabbitmq中读取 |
| redis | 从Redis实例读取事件 |
| log4j | 从Log4j SocketAppender对象通过TCP读取事件 |
| elasticsearch | 从Elasticsearch集群读取 |
| jdbc | 从jdbc数据中读取 |
| websocket | 从网络套接字读取事件 |
Filebeat客户端是一个轻量级的、资源友好的工具,它从服务器上的文件中收集日志,并将这些日志转发到你的Logstash实例以进行处理。Filebeat设计就是为了可靠性和低延迟。Filebeat在主机上占用的资源很少,而且Beats input插件将对Logstash实例的资源需求降到最低。
关于更多输入插件参照:
https://www.elastic.co/guide/en/logstash/current/input-plugins.html
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响。常用的过滤器如下:
1.grok插件:解析并构造任意文本。Grok是目前Logstash中将非结构化日志数据解析为结构化和可查询内容的最佳方式。有了内置于Logstash的120种模式,很可能会找到满足需求的模式!
2.ruby插件: 官方对ruby插件的介绍是无所不能。ruby插件可以使用任何的ruby语法,无论是逻辑判断,条件语句,循环语句,还是对字符串的操作,对EVENT对象的操作,都是极其得心应手的。
3.mutate插件: mutate插件是用来处理数据的格式的。
4.json插件:这个插件也是极其好用的一个插件,现在我们的日志信息,基本都是由固定的样式组成的,我们可以使用json插件对其进行解析,并且得到每个字段对应的值。
更多过滤器插件请参考:
https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
输出是Logstash管道的最后阶段。事件可以通过多个输出,但是一旦所有输出处理完成,事件就完成了它的执行。 Logstash有很多输出选择,最常用的是输出到elasticsearch。常见的输出还有:
1.elasticsearch
2.File
3.Emial
4.http
5.Kafka
6.Redis
7.MongoDB
8.Rabbitmq
9.Syslog
10.Tcp
11.Websocket
12.Zabbix
13.Stdout
14.Csv
更多输出插件请参照:
https://www.elastic.co/guide/en/logstash/current/output-plugins.html
Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch 协作。您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。
Kibana 可以使大数据通俗易懂。它很简单,基于浏览器的界面便于您快速创建和分享动态数据仪表板来追踪 Elasticsearch 的实时数据变化。
更多资料请参考:
https://www.elastic.co/guide/cn/kibana/current/index.html
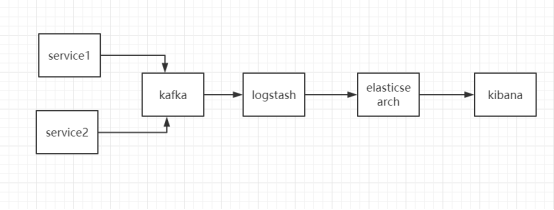
此方案大致思路如下:
1.应用将日志传入kafka。
2.logstash在kafka上消费(读取)日志内容,写入elasticsearch。
3.kibana读elasticsearch,做对应的展示。
这样的好处是:
1)几乎不用做特别大的修改,只需做一定的配置工作即可完成日志收集;
2)日志内容输入kafka几乎没有什么瓶颈,可以做到解耦,另外kafka的扩展性能很好,也很简单;
3)收集的日志几乎是实时的;
4)整体的扩展性很好,很容易消除瓶颈,例如elasticsearch分片、扩展都很容易。
方案架构图如下:
 -->
UTF-8
INFO
<!--ACCEPT-->
<!--DENY-->
applog
bootstrap.servers=ip:9092
-->
UTF-8
INFO
<!--ACCEPT-->
<!--DENY-->
applog
bootstrap.servers=ip:9092
注意: bootstrap.servers=ip:9092填写你自己的kafka所在服务器的ip地址
application指定日志文件:
logging:
config: classpath:logback.xml
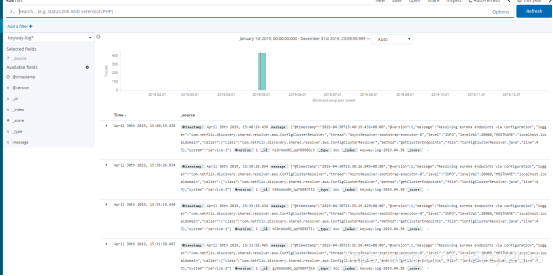
至此,Spring Cloud整合ELK已经弄好了。调用微服务接口,然后就可以在kibana上看到日志信息,如图所示:
作者:zhaojiaxing0216