机器学习代码实战——One-Hot编码(独热编码)
文章目录1.实验目的2.训练+预测2.1.get_dummies方法2.2.OneHotEncoder方法
1.实验目的
作者:程旭员
根据csv文件已给属性(Car Model、Mileage、Sell Price($)、Age(yrs))来预测汽车售价。下面将给出两种预测onehot编码方法,其中模型用LinearRegression。
汽车数据
密码:7izi
import pandas as pd
df = pd.read_csv('carprices.csv')
dummies = pd.get_dummies(df['Car Model']) #对Car Model字段用get_dummies数字化
dummies
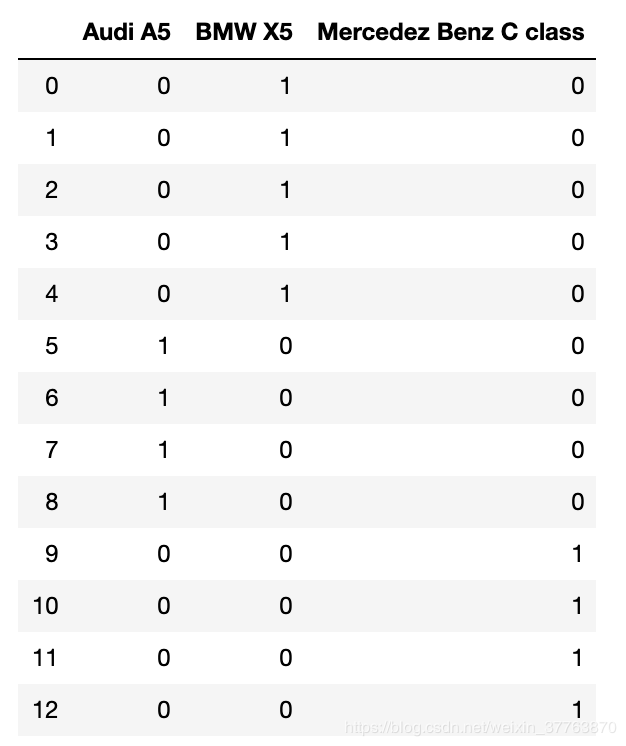
merged = pd.concat([df,dummies],axis='columns') #合并字段
final = merged.drop(['Car Model','Mercedez Benz C class'],axis='columns') #删除原Car Model字段和Mercedez Benz C class,其中删除Mercedez Benz C class是为了防止虚拟陷阱(详细请查阅相关资料)
X = final.drop('Sell Price($)',axis='columns') #训练数据
y = final['Sell Price($)'] #训练标签
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X,y) #用LinearRegression拟合训练数据
model.score(X,y) #计算得分
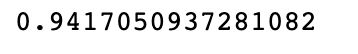
预测:

from sklearn.preprocessing import LabelEncoder #导入LabelEncoder模块
le = LabelEncoder() #实例化对象
dfle = df
dfle['Car Model'] = le.fit_transform(dfle['Car Model']) #利用LabelEncoder将字段Car Model数字化
dfle
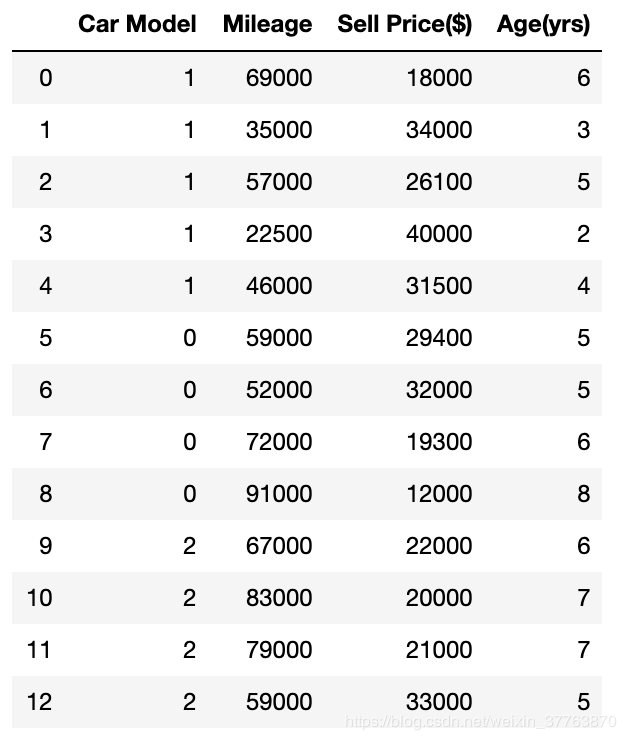
X = dfle[['Car Model','Mileage','Age(yrs)']].values
y = dfle['Sell Price($)'].values
from sklearn.preprocessing import OneHotEncoder #导入OneHotEncoder模块
ohe = OneHotEncoder(categorical_features=[0]) #对第一个字段OneHot编码
X = ohe.fit_transform(X).toarray() #转化成0、1形式
X = X[:,1:] #其中删除Mercedez Benz C class是为了防止虚拟陷阱(详细请查阅相关资料)
X
model.fit(X,y)
model.score(X,y)

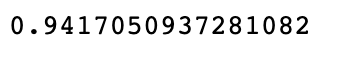
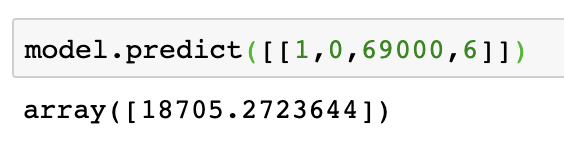
预测:
作者:程旭员