Python复健练习:多线程图片爬取(豆瓣)
[爬取豆瓣坂本龙一 Ryuichi Sakamoto图片]
成果:
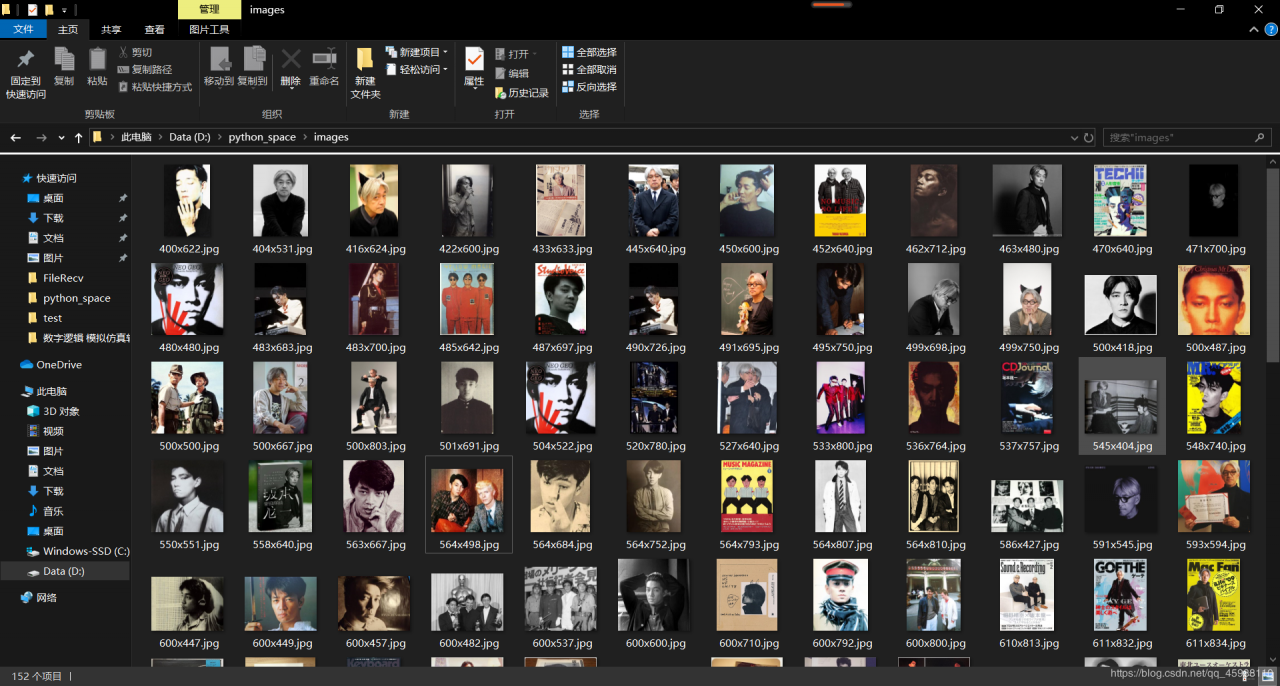 (多线程访问速度过快导致极少部分无法下载,需要完全下载可time.sleep())
(多线程访问速度过快导致极少部分无法下载,需要完全下载可time.sleep())
[下方附代码与部分知识点解析]
[代码链接:https://paste.ubuntu.com/p/TYhCK4vnbB/]
import threading
import time
def multi_thread():
t1 = threading.Thread(target=coding)
t2 = threading.Thread(target=drawing)
t1.start()
t2.start()
#基础模块
threading.enumerate():当前线程的数量
threading.current_thread():当前线程的信息。

使用锁机制解决多线程共享全局变量(global类型)的问题: eg:
gLock = threading.Lock()
gLock.acquire()
需锁定运行的线程
gLock.release()
threading.Condition可以在没有数据的时候处于阻塞等待状态。一旦有合适的数据了,可以使用notify相关的函数来将处于等待状态的线程唤醒。
gCondition = threading.Condition()
gCondition.acquire()
gCondition.wait()
gCondition.release()
gCondition.notify():通知默认是第1个等待的线程。
gCondition.notify_all():通知所有正在等待的线程。
[notify和notify_all不会释放锁需要在release之前调用]
Queue线程安全队列:
from queue import Queue
request.urlretrieve() 用于下载制定url内容到本地
[request.urlretrieve(url, filename, reporthook, data) ]
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。[可利用这个回调函数来显示当前的下载进度]
data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头
eg:
from urllib import request
request.urlretrieve(img_url,‘images/’+filename)
[‘images/’+filename:保存在images文件夹下以filename命名]
os.path.splitext(“文件路径”) 分离文件名与扩展名;默认返回(fname,fextension)元组,可做分片操作 eg:
import os
path_01=‘E:\STH\Foobar2000\install.log’
res_01=os.path.splitext(path_01)
print(root_01)
print(root_01)[1]
输出:(‘E:\STH\Foobar2000\install’, ‘.log’)
(’.log’)
作者:RyuichiSakamoto