Modin.pandas使用多核CPU加速pandas?Modin.pandas可以代替pandas?看看就知道了
答案先写在开头,免得你们直接拉到下面看结果~
modin.pandas 确实能使得一部分函数使用多核cpu进行加速处理,但是现在有些功能还不完善,有些函数还是用的默认pandas处理…
具体哪些函数是可以加速的可以往下看看
主要测试了apply,groupby,read_csv
在讲modin之前,简单介绍一下pandas,pandas主要是python用来处理数据的时候用到的一个库,并且为了追求效率,并不是用python写的,底层逻辑用的是c语言。而且对于各种计算逻辑已经被开发者开发到相对优秀的程度了。
但是即便如此,由于python本身语言的特点,pandas也只能在单核上进行计算,因此在考虑加速pandas处理大量数据的时候,使用多核cpu也就成为第一考虑目标了。
这个时候Modin项目就出现了。
Modin是加州大学伯克利分校RISELab的早期项目,旨在促进分布式计算在数据科学中的应用。它是一个多进程Dataframe库,具有与pandas相同的API,允许用户加速其Pandas工作流程。
总而言之,modin.pandas就是在pandas的基础之上多封装了一层使用多核cpu进行加速计算。
废话不多说,我们直接看试验结果。
二、Modin.pandas试验测试代码如下
def pandas_test():
import pandas as pd
from time import time
df = pd.DataFrame(zip(range(1000000),range(1000000,2000000)),columns=['a','b'])
start = time()
df['c'] = df.apply(lambda x:x.a+x.b ,axis=1)
df['d'] = df.apply(lambda x:1 if x.a%2==0 else 0, axis=1)
print('pandas_df.apply Time: {:5.2f}s'.format(time() - start))
start = time()
group_df = df[['d','a']].groupby('d',as_index=False).agg({"a":['sum','max','min','mean']})
print('pandas_df.groupby Time: {:5.2f}s'.format(time() - start))
start = time()
data = pd.read_csv('test_modin.csv')
print('pandas_df.read_csv Time: {:5.2f}s'.format(time() - start))
def modin_pandas_test():
import modin.pandas as pd
from time import time
df = pd.DataFrame(zip(range(1000000),range(1000000,2000000)),columns=['a','b'])
start = time()
df['c'] = df.apply(lambda x:x.a+x.b ,axis=1)
df['d'] = df.apply(lambda x:1 if x.a%2==0 else 0, axis=1)
print('modin_pandas_df.apply Time: {:5.2f}s'.format(time() - start))
start = time()
group_df = df[['d','a']].groupby('d',as_index=False).agg({"a":['sum','max','min','mean']})
print('modin_pandas_df.groupby Time: {:5.2f}s'.format(time() - start))
start = time()
data = pd.read_csv('test_modin.csv')
print('modin_pandas_df.read_csv Time: {:5.2f}s'.format(time() - start))
if __name__ == '__main__':
pandas_test()
modin_pandas_test()
创建一个百万行的df 进行apply ,groupby
test_modin.csv 大小为70M
观察服务器CPU的使用情况,服务器背景 4核
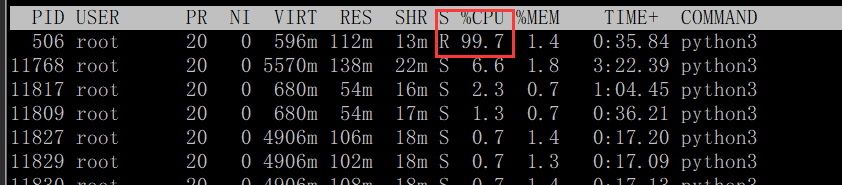
1、pandas
2、modin.pandas
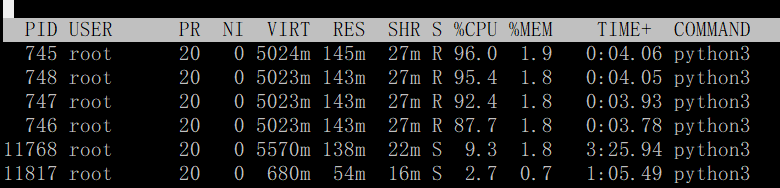
从cpu的使用情况确实可以看到modin.pandas比普通的pandas使用了多核cpu进行计算。
而且modin.pandas 会自动使用所有核进行计算,也就是cpu会一下子满负荷。。
OK,我们直接看代码的执行结果.

可以看到在apply跟read_csv方面确实是比原来的pandas快了,只是快的没有想象中的那么多。
但是在groupby方面却没有比原来快,反而比较慢了。
思考了一下原因:
groupby使用多核cpu进行计算有点像我们开多进程去进行并行计算,最好的切割方式就是以groupby的字段类别去切割对应的进程数,然后再对数据进行汇总。
在上面的测试例子中只有2个类别,并且还要对数据进行汇总计算,因此可能在效率上并没有最优运用到多核的特点,反而增加了汇总时间。
如果有大佬知道什么原因的可以告诉我一下嘛~
至此我们的初步测试就结束了。
从结果上来看modin对pandas的加速还是很明显的,特别是对数据量比较大的时候,我上面测试的数据量相对于真正的大数据来说,只是一个demo。因此如果大家在处理大数据然后对pandas效率不是很满意的时候可以考虑用的一下modin.pandas 加速加速。
但是有部分函数modin.pandas还没完全实现。使用的时候要注意哦。
我是一只前进的蚂蚁,希望能一起前行。
如果对您有一点帮助,一个赞就够了,感谢!
注:如果本篇博客有任何错误和建议,欢迎各位指出,不胜感激!!!
 一只前进的蚂蚁
一只前进的蚂蚁
 原创文章 13获赞 15访问量 1237
关注
私信
展开阅读全文
原创文章 13获赞 15访问量 1237
关注
私信
展开阅读全文
作者:一只前进的蚂蚁