论文 基于度量学习的小样本学习研究 阅读心得
本文提出带间隔的小样本学习, 提升了所学习嵌入表示的质量。 为引入间隔, 本文根据小样本场景特点提出了多路对比损失, 使得小样本学习模型可以学习到一个更加具有判别性的度量空间,同时泛化误差可以减小。带间隔的小样本学习是一个通用的框架,可以同各种基于度量的小样本学习模型结合。 本文将带间隔的小样本学习引入到两种已有模型中,分别是原型网络和匹配网络。 另外, 数据的分布往往都有内在结构,现有的基于度量的小样本学习算法在分类时没有考虑数据分布的特性, 阻碍了算法的效果。 本文使用基于图正则的关系传播框架, 通过结合样本分布的流形和已知的样本间关系,推断出未知的样本间关系。 该框架的目标函数是一个凸优化问题,可以求得全局最优解。 利用该框架,本文提出了基于图正则的小样本学习算法,将图正则融入到小样本学习的任务中。 由于图正则的存在,使得算法可以充分考虑每个类别数据分布的特点, 从而提升分类的准确率。
提出了一种带间隔的小样本学习方法,具体做法是引入多路对比损失(可以学习到一个更加具有判别性的度量空间,同时减小泛化误差),并将该方法引入到两种已有模型(原型网络和匹配网络)。
另外,这篇文章使用基于图正则的关系传播框架,通过结合样本分布的流形和已知的样本间关系,推断出未知的样本间关系。(考虑数据分布)
这篇论文在梳理小样本学习的发展历程方面写的真的很好。
根据方法特点,本文将小样本学习的发展分为三个阶段:早期阶段、贝叶斯学习阶段和神经网络阶段。上世纪 90 年代开始陆续出现一些小样本学习相关的论文[9,10,11],当时采用的方法有稀疏表示[9]等,这个时期称之为早期阶段。 早期阶段的工作主要是一些探索性的工作,产生的影响力较为有限。
[9] YIP K, SUSSMAN G J. Sparse representations for fast, one-shot learning[C]. NationalConference on Artificial Intelligence. Rhode Island, USA, 1997.
[10] KOHONEN T. The self-organizing map[J]. Proceedings of the IEEE ICNN, 1990, 78(9):1464-1480.
[11] TAASAN S. One shot methods for optimal control of distributed parameter systems 1:
Finite dimensional control[J]. ICASE Report, 1991, 91(2): 1-20.
贝叶斯学习阶段是 2003 年到 2015 年这个时期,这个时期出现了一些代表性工作如贝叶斯规划学习[6]等[12-16],这些工作产生了很大的影响力。 贝叶斯学习阶段的主要特点是模型所采用的方法往往都是基于贝叶斯理论,可以处理小样本问题并很好地融合先验知识。但是该阶段的工作也存在一个问题,即模型的通用性往往不够。换句话说,该阶段的模型往往是为具体问题所设计的,当问题发生一些改变时,模型将不再有效。
贝叶斯方法在小样本问题上的应用起源于李飞飞等人的工作[12,13],该工作通过贝叶斯方法实现小样本物体识别。具体地说,该工作使用变分贝叶斯框架,将物体的类别表示为概率模型,而模型的参数以概率密度函数的形式作为先验知识,物体类别的后验概率是通过学习类别样本调整先验得到的。该算法首先在背景数据集上进行学习,然后算法利用测试类别的 1~5 个样本进行学习,实现小样本条件下的精准分类,注意到背景数据集中没有测试类别的样本。在 2012 年, Salakhutdinov等人提出使用层次无参贝叶斯模型实现小样本学习[14]。该模型将类别表示为树状的层次结构,比如动物类有绵羊、马等,机动车类有小汽车、卡车等,而动物类和机动车类又同属于一个超类。每个类别通过均值和方差这两个参数表示,不同类别之间通过迁移参数实现知识的迁移。
2015年以来,有诸多的深度学习方法先后被应用到小样本问题之上。 Koch 等人于 2015年提出将孪生网络用于小样本问题[17],掀开了神经网络处理小样本问题的序幕。 孪生网络最早由 LeCun 等人于 1990 年代提出[31],用于判别两个签名是否来自同一个人。 Koch 等人将孪生网络用于判断两个样本是否属于相同的类别。孪生网络在小样本学习任务中取得了较好的效果,但和 Lake 等人[6]相比仍有差距。
2016 年, Vinyals 等人提出匹配网络( Matching Networks) [18], 该网络利用注意力机制来推断样本的类别。同时,该网络修改模型训练的模式,实现训练过程和测试过程相匹配。
2017 年, Snell 等人提出原型网络( Prototypical Networks) [19], 该网络在匹配网络的基础上进一步改进。 相比匹配网络,原型网络使用了簇中心点表示簇的方法,并且使用欧氏距离替换了匹配网络中使用的余弦距离。 诸多改进使得原型网络在收敛速度等方面优于匹配网络, 也提高了其小样本学习任务上的表现。
这篇文章在解决小样本问题上的主要理论创新是提出了一种带间隔的损失损失函数,即从损失函数的角度做了工作。
一系列度量学习的相关工作[39,52]显示带间隔的损失函数可以学习得到更加清晰的簇结构。 另一方面,间隔可以提升分类器的泛化能力。基于这些想法,本文提出带间隔的小样本学习。通过在小样本学习中引入间隔这一概念,使得小样本学习模型可以学习得到一个更加具有判别性的度量空间,同时泛化误差可以减小。带间隔的小样本学习是一个通用的框架,可以同各种基于度量的小样本学习模型结合,有效提升这些模型的表现。本文提出多路对比损失,该损失是一个基于间隔的损失函数。其特点是能够同时挖掘一个样本和多个样本之间的关系,最小化同类样本之间的距离,同时最大化非同类样本之间的距离。本文还将该损失函数整合到两种代表性的小样本学习模型中。实验的结果显示本文提出的间隔损失可以有效提升小样本学习模型的性能。
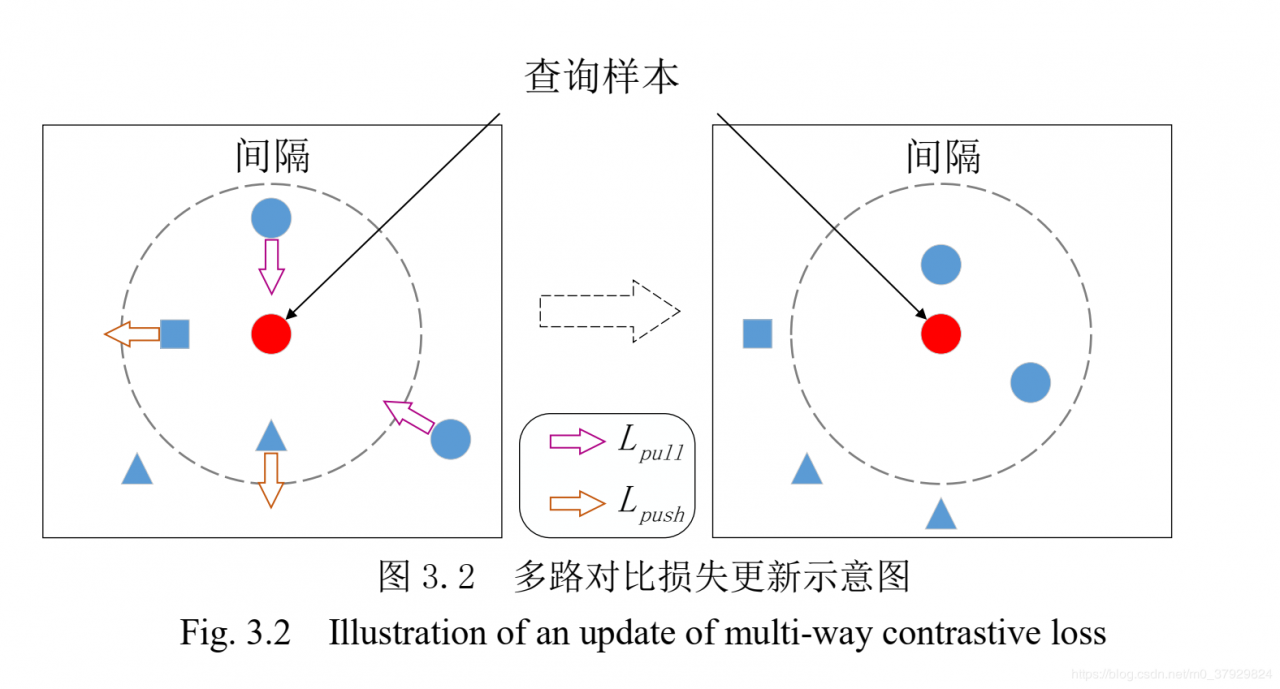
这篇文章的核心是提出的特殊的损失函数,这个损失函数有两部分组成,一个是推力、另一个是拉力,使相同的类之间尽可能产生拉力,而不同的类之间给定固定阈值而产生推力。作者宣称,推力部分的损失函数,可以产生前文所言的间隔,进而优化整个模型。
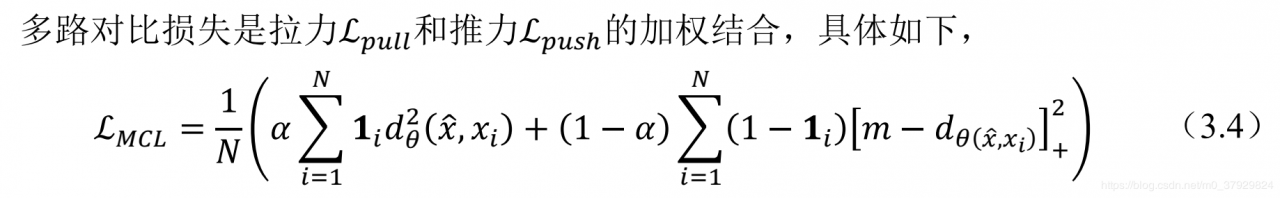
实验目的:验证本损失函数在各个模型上的表现
实验平台:为了评估算法的性能,本文在两个数据集上展开了小样本验,这两个数据集分别是 Omniglot[6]和 miniImageNet[18]。实验比较了多个模型,包括 Siamese Networks[17]、 Neura Statistician[55]、 MAML[30]、 meta-learner LSTM[24]、匹配网络( MN) [18]、带间隔的匹配网络(MN-M) 、原型网络( PN) [19]和带间隔的原型网络( PN-M)。
实验流程:本文采用的嵌入网络架构和 Vinyals 等人的工作[18]相同。该嵌入网络架构包含四个卷积单元,每个卷积单元由一个 64 核的 3 3 卷积层、一个衰减率为 0.99 的批归一化( Batch Normalization)层、 一个 ReLU 激活层和一个 2 2 的最大池化( Max-pooling)层构成。当该嵌入网络架构应用于 28 28 的 Omniglot 图片,会产生 64 维的输出作为嵌入结果。模型采用的优化算法为 Adam[56]。初始学习率设为 0.001,并且每经过 2000
episode 的训练会将学习率调整为之前的一半。除了批归一化,模型没有采用其他的正则化方法。 为了测试模型在 5-way 任务和 20-way 任务上的表现,模型分别在 20-way1-shot 任务和 60-way 5-shot 任务上进行训练。 Omniglot 数据集被随机划分为三部分, 1000种字符用于训练, 200 种字符用于验证,剩余的字符用于评估。
实验结果:
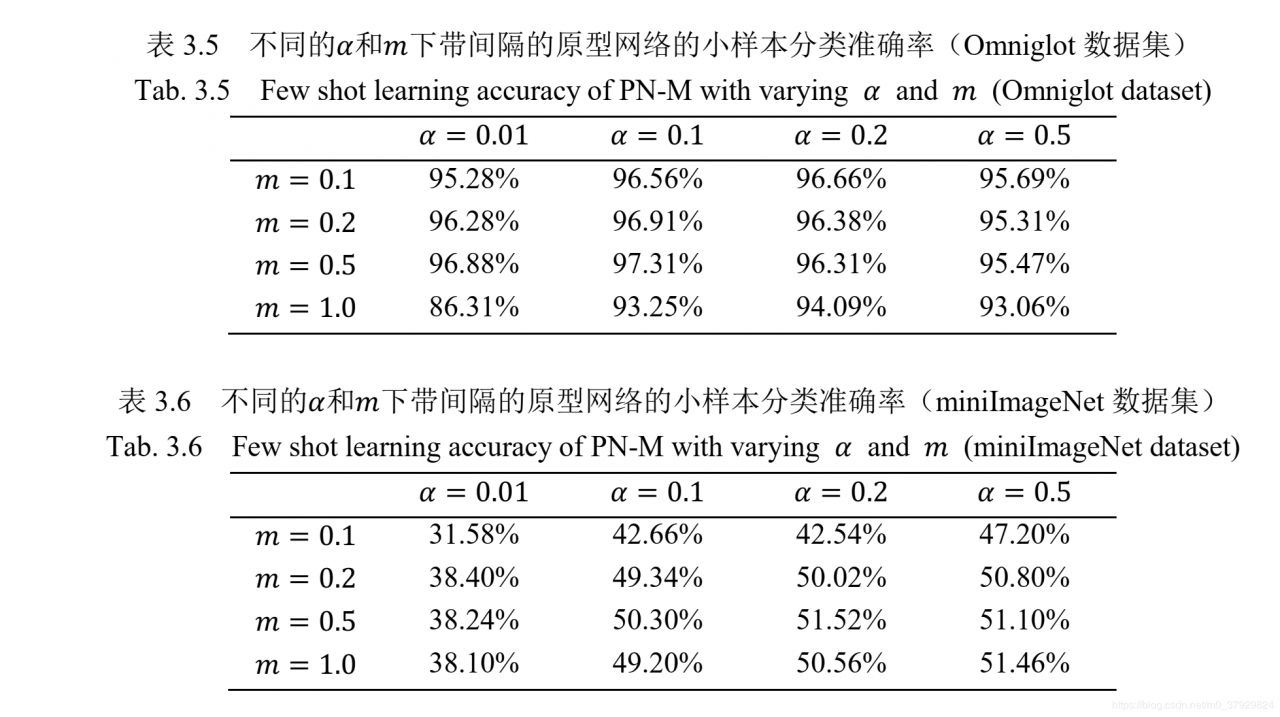
Omniglot 上的实验结果见表 3.3。可以看出在所有的条件下,不管是 5-way 还是20-way 的任务,带间隔的原型网络都取得了最好的实验结果。表中可以看到带间隔的匹配网络优于原始匹配网络,带间隔的原型网络优于原始原型网络,这说明在小样本学习中引入间隔的有效性,间隔能够明显提升这些模型的泛化能力。 值得一提的是,带间隔的原型网络在 5-way 任务和 20-way 5-shot 任务上取得了接近完美的表现。
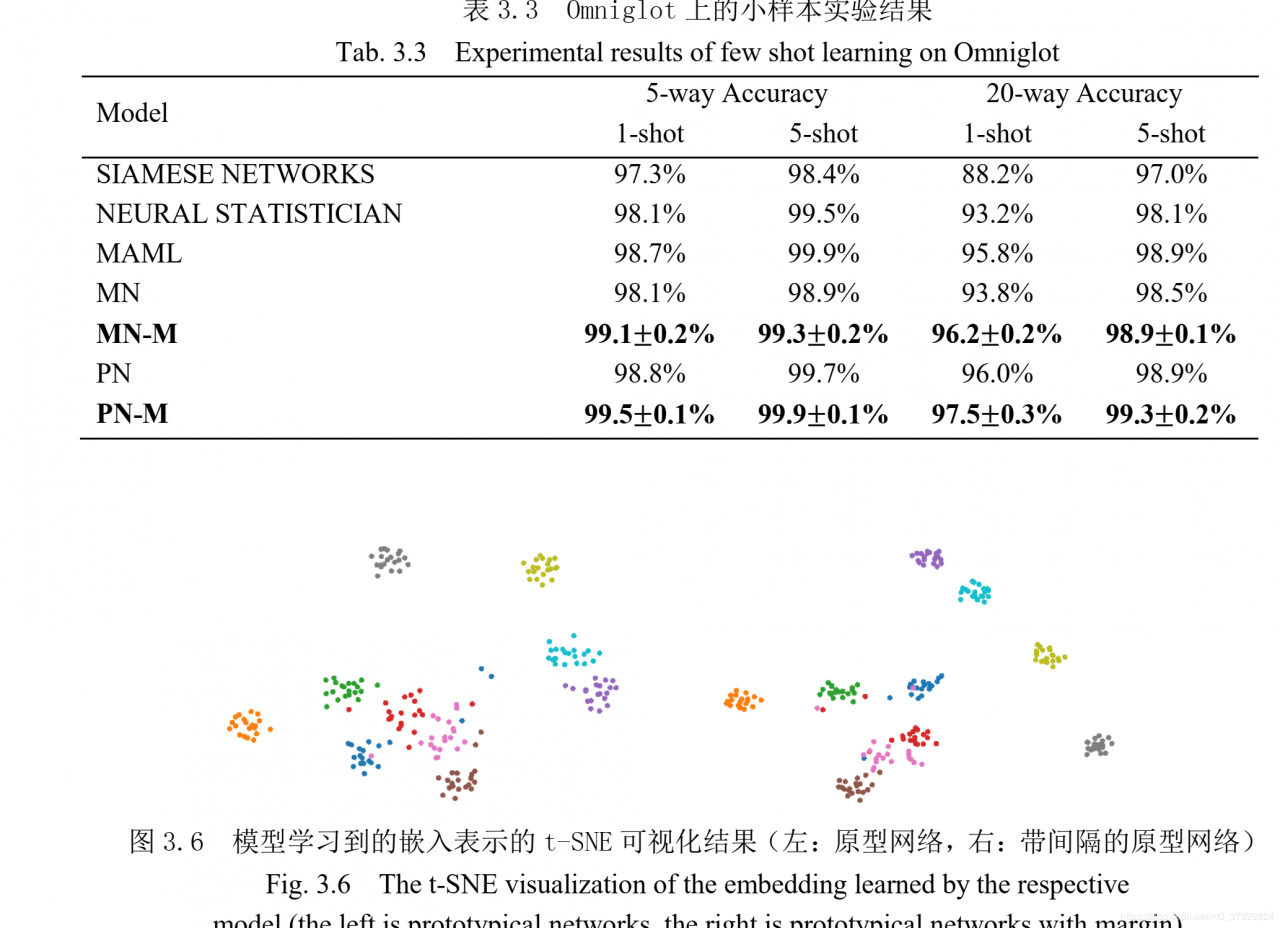
另外,本文还比较了原型网络和带间隔的原型网络所学习到的嵌入表示的质量。本文选择了 Omniglot 的评估数据集中的一个字符子集作为对象,共 10 个类别,每个类别20 个样本,将其嵌入到 64 维空间中。然后使用 t-SNE 算法对其进行可视化,可视化的结果在图 3.6 中。可以看出带间隔的原型网络所产生的嵌入表示具有更加清晰的簇结构,即满足簇内样本的紧密性和簇间样本的可分性。尽管学习到的样本分布规律很相似,但是可以明显看出原始原型网络所学习到的嵌入表示分布的结构比较松散,一些不同类的样本分布的位置很接近,这些位置的样本是阻碍分类器正确率提高的因素。反观带间隔的原型网络,不同类的样本间都有比较清晰的分界,即使仍存在少量的误分类样本,但清晰的簇结构体现了嵌入表示的优良。
实验流程:miniImagenet
在 miniImageNet 数据集上,本文采用了 Omniglot 数据集上相同的嵌入网络,但由于此数据集的图片更大,所以生成的嵌入表示是 1600 维。 此处没有采用学习率衰减策略。本文的数据集切分方式采用了 Ravi 和Larochelle 的划分[24],该切分方式使用 64 个类别用于训练, 16 个类别用于验证, 20 个类别用于评估。 为了评估模型在 5-way 1-shot任务和 5-way 5-shot 任务上的表现,本文使用 20-way 5-shot 任务对模型进行训练。
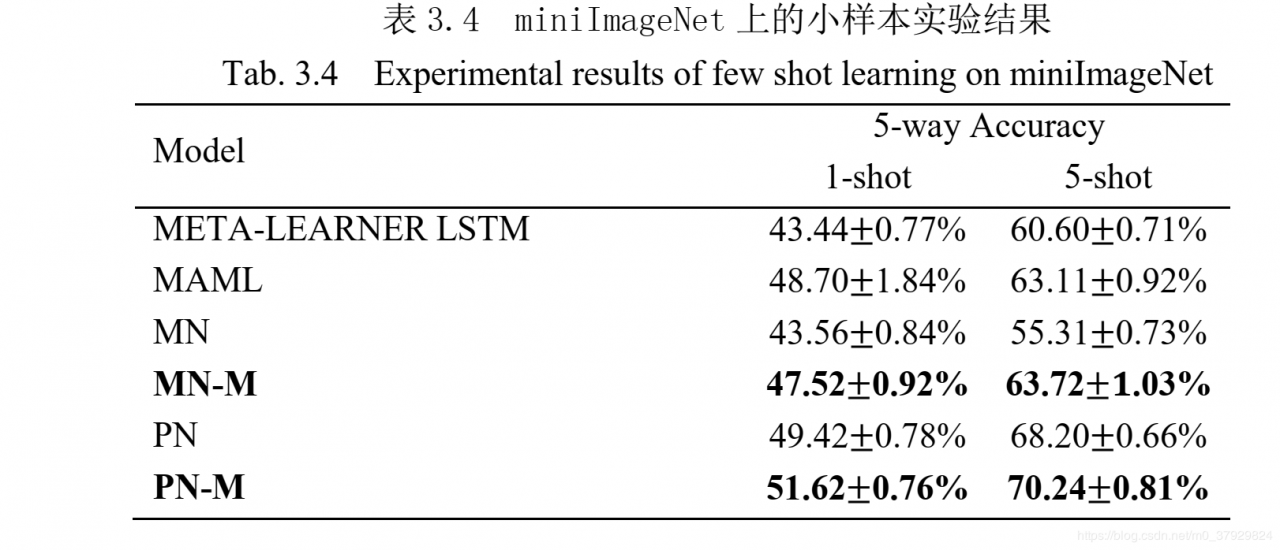
miniImageNet 数据集上的实验结果见表 3.4。总体上而言,带间隔的原型网络仍然取得最优的表现。具体来说,带间隔的原型网络相比原始原型网络,其准确率提升了 2%有余。 而带间隔的匹配网络相比原始匹配网络,准确率提升超过 4%。 这些实验结果说明带间隔的小样本模型表现出了更好的泛化能力。
实验结果:MiniImageNet
Omniglot 数据集由 Lake 等人[6]于 2015 年提出。 Omniglot 包含了来自 50 个字母系统的 1623 个字符, 每个字符包含 20 张由不同人手写的字符图片。每个字符图片大小105×105,通道数为 1。 该数据集在使用时一般要将其中的图片缩小为 28×28,主要因为缩小后的图片已经完全可以描述原始图片,同时缩小后图片使得数据维度大大下降。图片缩放的过程参照 Vinyals 等人[18]的工作。 图 3.5 有 Omniglot 数据集的示例。 Omniglot
数据集常视为 MNIST 数据集的转置, Omniglot 包含了 1623 个类别,但每个类别只有20 个样本,而 MNIST 则是只有 10 个类,但每个类有 6000 个训练样本和 1000 个测试样本。

Omniglot 数据集诞生之初, 基本可以满足人们对算法泛化能力进行评估的需求,但随着一些深度学习方法应用到小样本问题上,这些算法在Omniglot 上的分类精度常常超过 90%,因此 Vinyals 等人[18]提出 miniImageNet 数据集。顾名思义,该数据集源自著名的 ILSVRC-12 数据集。在构成上, miniImageNet 由 60000 张彩色图片构成,包括 100
类每类 600 张图片。 每张图片的大小为 84 84,通道数为 3。 Vinyals 等人[18]并未在论文中给出具体的数据集,后来 Ravi 和 Larochelle[24]在公开 代码中给出了具体的数据集构成和划分方式。 图 3.7 中是 miniImageNet 数据集的示例。
代码中给出了具体的数据集构成和划分方式。 图 3.7 中是 miniImageNet 数据集的示例。
[1]聂金龙.基于度量学习的小样本学习研究[D].辽宁:大连理工大学,2019.
总结:这篇文章用一种能想到的方式建立了一个非常简单却实用的损失函数,并基于这个损失函数对性能的提升展开了一系列实验,实验亦能证明这个损失函数的优异。
损失函数的建立思路是间隔、间隔将带来分类性能的提升。
另外,这篇文章的作者对于小样本学习在模型、算法方面的梳理非常到位。
作者:Storm__