pytorch学习笔记(十五)————动量与学习率衰减
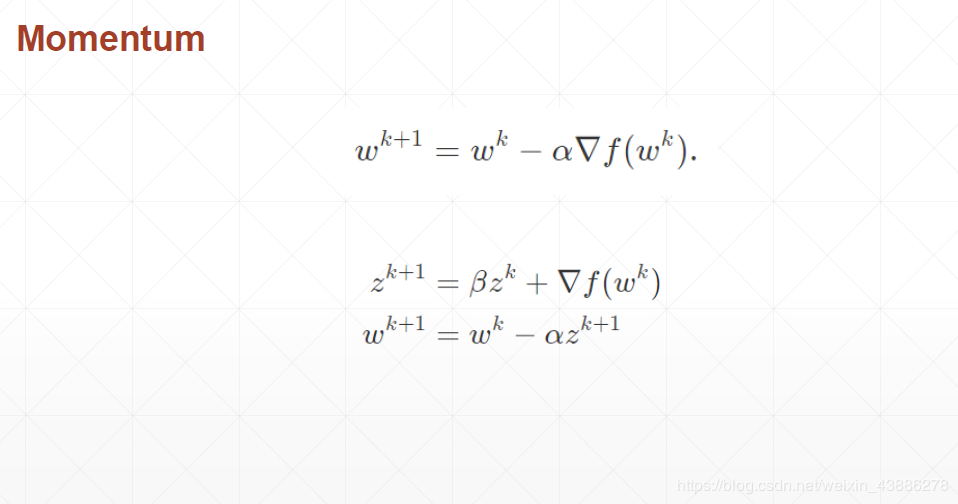
从形式上看, 动量算法引入了变量 z充当速度角色——它代表参数在参数空间移动的方向和速率。速度被设为负梯度的指数衰减平均。名称 动量(momentum),相当于引入动量前的梯度概念,指示着loss在参数空间下一步要下降的方向和大小。
其中wk+1w^{k+1}wk+1表示更新后权重;wkw^{k}wk表示更新前权重;zk+1z^{k+1}zk+1代表动量,,α表示学习率
从公式zk+1=βzk+▽f(wk)z^{k+1}=βz^{k}+▽f(w^{k})zk+1=βzk+▽f(wk)可以看出,zk+1z^{k+1}zk+1由两部分组成,其中zkz^{k}zk表示上一次动量,▽f(wk)▽f(w^{k})▽f(wk)表示函数梯度,新一轮的动量为两者的矢量和。
通过梯度加上上一次动量乘以一定比例系数β,loss进行下一步梯度下降不仅要考虑到函数现在的梯度方向,还要考虑到函数之前的下降方向,相当于引入了物理中的惯性。有效避免了loss训练过程中抖动太大,受困于局部极小值点等问题。
(1)没有引入动量

(2)引入动量后
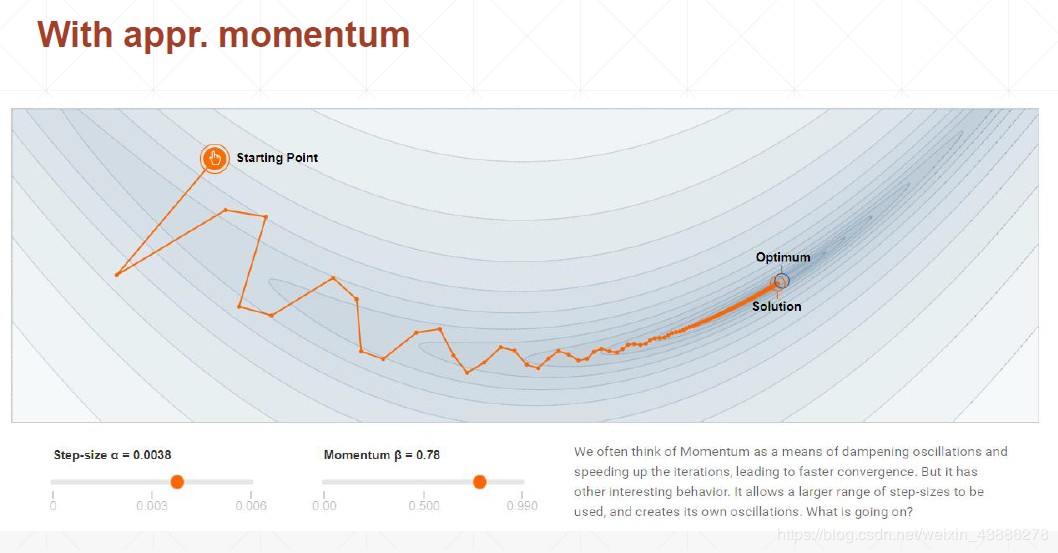
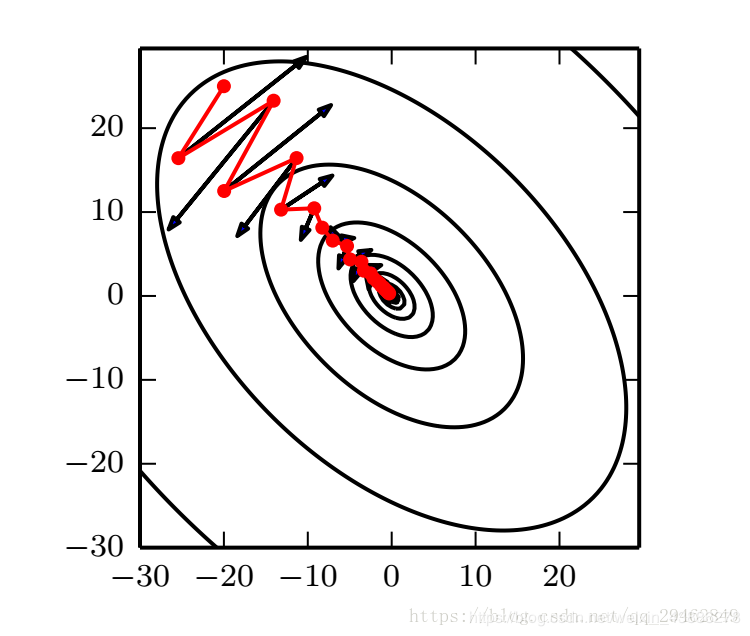
从图中可以看到,引入动量后loss函数更新的幅度减小,同时找到了全局最优解
(3)两种情况对比
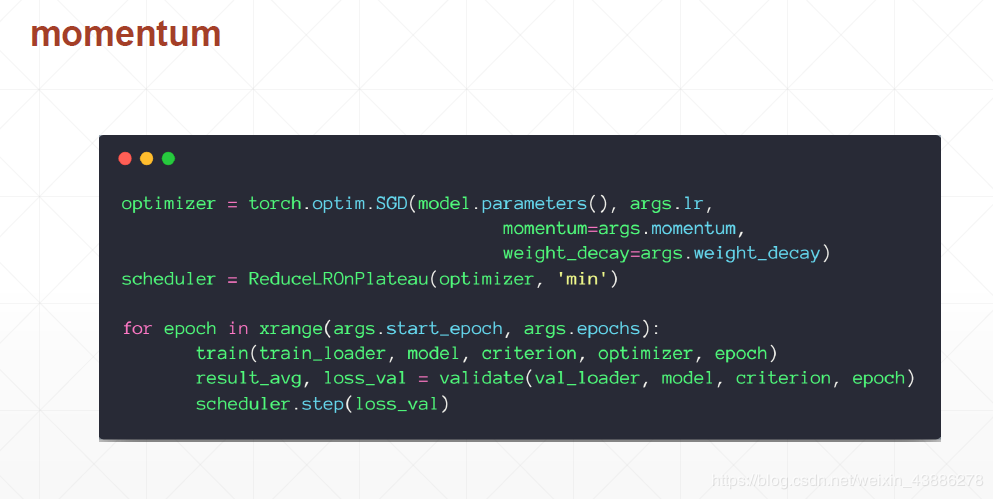
(4)引入动量代码
(1)三种情况下学习率对训练的影响
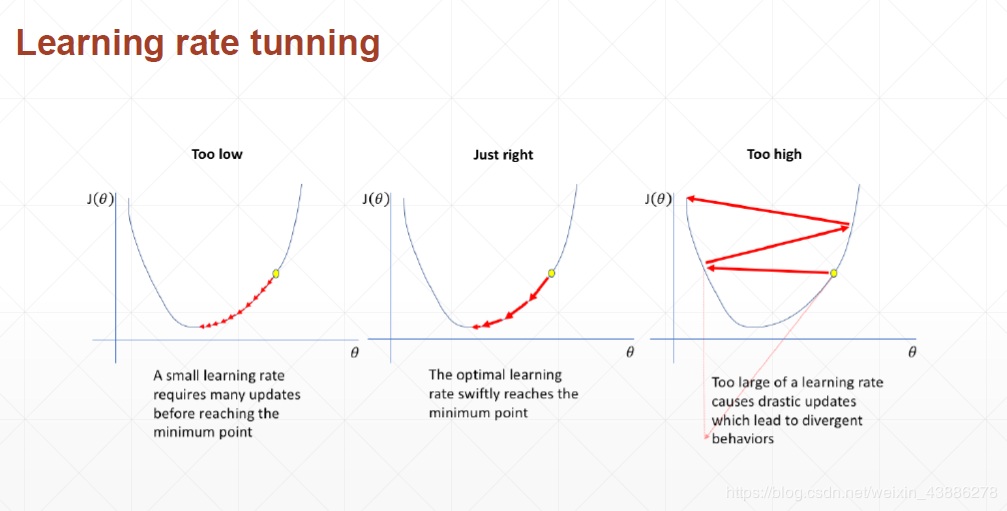
学习率过小,会使得收敛太慢,但是却可以收敛到极小值点
学习率过大,会使得目标函数甚至越来越大,或者始终在极小值点旁边徘徊,无法收敛到极小值点。,但是前期收敛很快。
结合这两点我们引入了动态学习率
(2)动态学习率
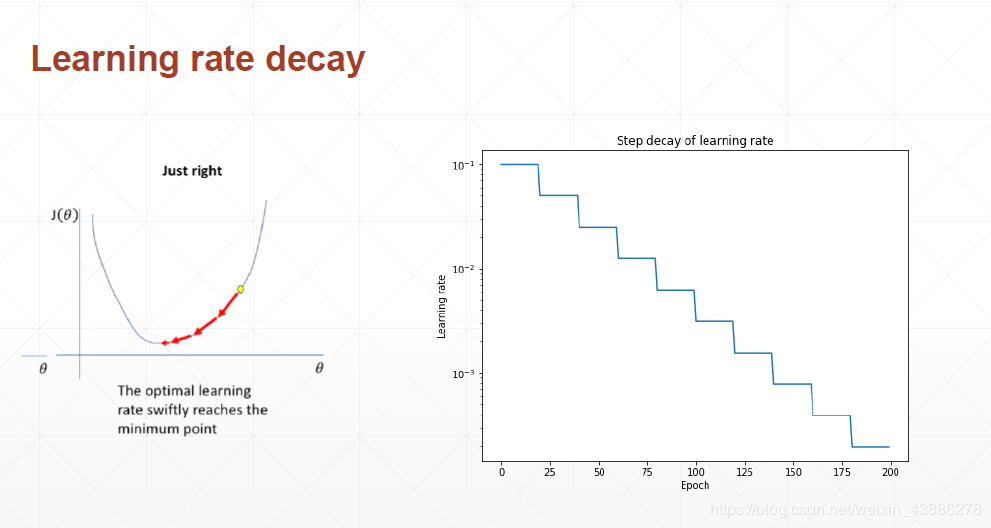
在前期可以设置稍微大一点的学习率如0.1,再经过一定时间后学习率不断下降,这样既保持了下降速度,同时又保证可以收敛到极小值点。
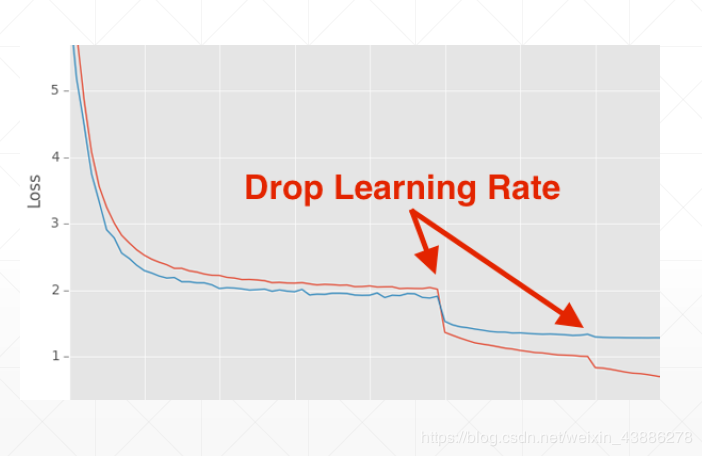
从图中可以看出,红色曲线在突变点出学习率下降成原来的一半后,loss显著降低。
(3)代码实现
实现方法一:
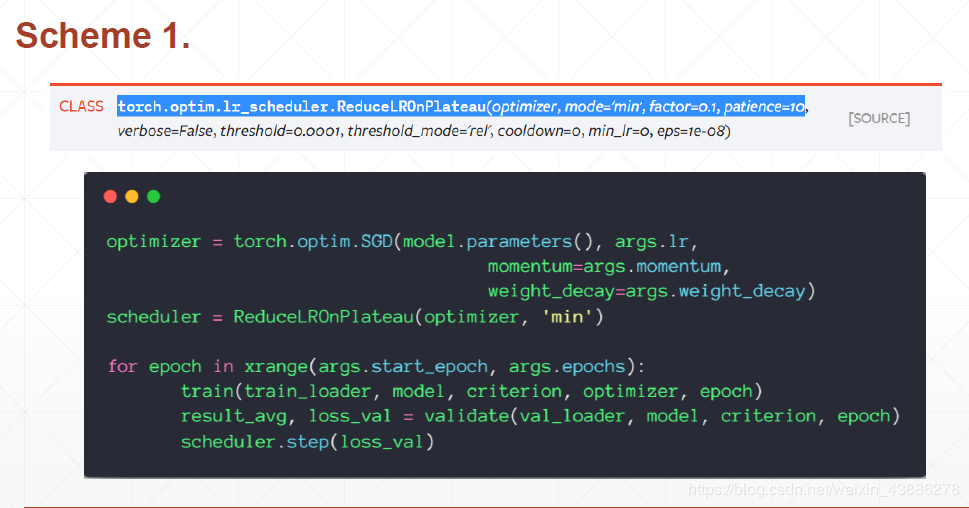
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode=‘min’, factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode=‘rel’, cooldown=0, min_lr=0, eps=1e-08):
该方法提供了一些基于训练过程中的某些测量值对学习率进行动态的下降.
参数详解:
optimer指的是网络的优化器
mode (str) ,可选择‘min’或者‘max’,min表示当监控量停止下降的时候,学习率将减小,max表示当监控量停止上升的时候,学习率将减小。默认值为‘min’
factor 学习率每次降低多少,new_lr = old_lr * factor
patience=10,容忍网路的性能不提升的次数,高于这个次数就降低学习率
verbose(bool) - 如果为True,则为每次更新向stdout输出一条消息。 默认值:False
threshold(float) - 测量新最佳值的阈值,仅关注重大变化。 默认值:1e-4
cooldown: 减少lr后恢复正常操作之前要等待的时期数。 默认值:0。
min_lr,学习率的下限
eps ,适用于lr的最小衰减。 如果新旧lr之间的差异小于eps,则忽略更新。 默认值:1e-8。
括号中传入的是要进行监测的loss,如果loss在一定设置的次数内没有显著变化,则减少学习率。
实现方法二:
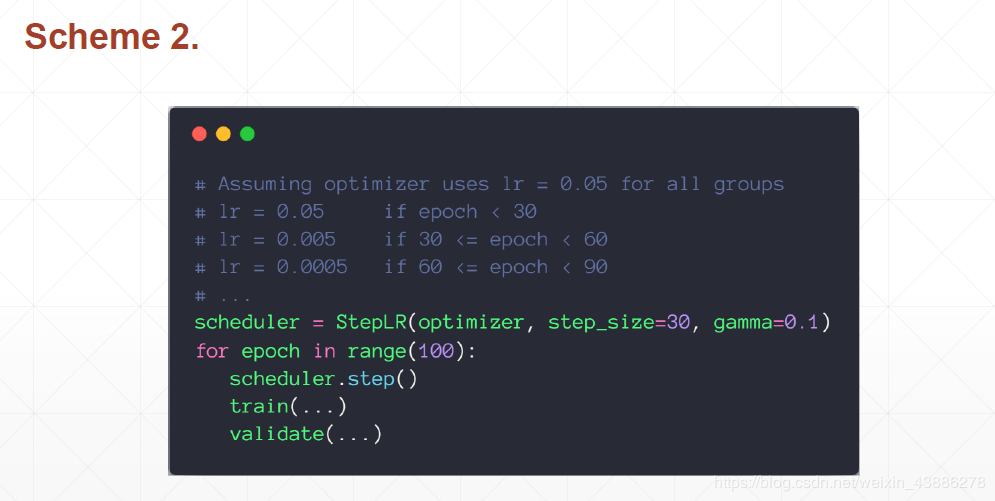
作者:南风渐起