爬虫系列(一):某瓣250部经典高分电影信息爬取
声明:本博客只是简单的爬虫示范,并不涉及任何商业用途。
前言为什么选取豆瓣电影Top 250来进行爬取呢?原因是它的网页结构相当规整,比较适合爬虫新手练习。下面我将详细展示爬虫的整个过程。
爬虫过程 网页链接分析爬虫起点网页为豆瓣电影 Top 250,整个250部电影一共分10页,每页对应的链接如下:
https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=
https://movie.douban.com/top250?start=75&filter=
...
https://movie.douban.com/top250?start=225&filter=
上述链接的结构都一致,唯一的区别是在查询字符串start = number的位置,因此,要想爬取网站的10页,可以用一个变量page来进行迭代。
请求网页我使用的是requests库,最开始我试探性的直接使用get函数请求网页内容,请求代码如下:
import requests
url = 'https://movie.douban.com/top250?start=0&filter='
reponse = requests.get(url)
print(reponse.status_code)
#418
结果服务器响应的代码是418,说明请求未成功,于是我又将User-Agent传递给了get函数的headers参数,结果返回200,说明请求成功,实验代码为:
import requests
url = 'https://movie.douban.com/top250?start=0&filter='
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}
reponse = requests.get(url,headers = headers)
print(reponse.status_code)
#200
若读者想要复现代码,需要获取浏览器的User-Agent参数,对于Chrome浏览器,可以直接在浏览器中输入about:version,会出现如下界面:
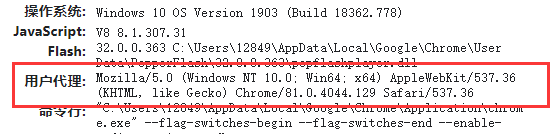
从其中就可以获取到User-Agent参数。在这些都搞定了以后,爬虫程序的请求部分就已经基本上完成了,下面是完整的请求代码:
def HTMLDownloader(page):
url = 'https://movie.douban.com/top250?start='+ str(page*25) +'&filter='
#print(url)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}
try:
reponse = requests.get(url,headers = headers)
if reponse.status_code == 200:#响应成功
return reponse.text
except requests.RequestException as e:
return None
解析网页
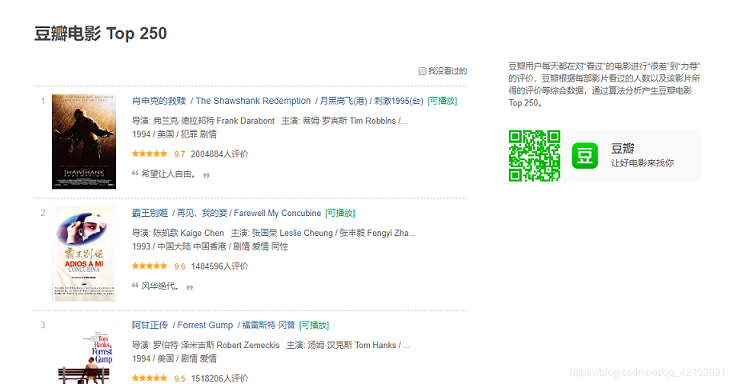
对于网页的解析使用的是BeautifulSoup,我准备爬取的各部电影的数据有:
电影名 豆瓣评分 电影简介 电影评论以Top 250的第一页为例,该网页部分内容如下:
 原创文章 29获赞 95访问量 1万+
关注
私信
展开阅读全文
原创文章 29获赞 95访问量 1万+
关注
私信
展开阅读全文
作者:斯曦巍峨