Pandas分析某眼TOP100电影都来自于谁?
2018年有一段时间稍微看了一段时间数据分析,稀里糊涂地做过一些demo,后来忙于创业项目的开发,风风火火地搞了10个月,就把数据分析及挖掘的事情给搁置了。
鼠年春节发生了新冠病毒的疫情,被逼在家,除了看娃,还是要找些事情做,来充实一下自己(其实,来自内心的恐惧,强制自己好好梳理一下),于是,又开始重新学习数据挖掘及分析,准备通过一系列的案例,来系统地学完实操,不能再半途而废了。
下面就是做某眼TOP100电源分析的过程,以作记录:
准备数据对于Python开发者来说,获取数据最简单的方式,就是盘它~,通过requests进行数据抓取,因为这只是一个简单的数据抓取,所以,没必要动用scrapy框架来做。
import re
import time
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 设置显示中文所需字体
plt.rcParams['font.family'] = 'Songti SC'
# 设置负号的正常显示
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline
# 设置清晰度
%config InlineBackend.figure_format = 'retina'
# 更改设计风格,使用自带的形式进行美化,这是一个r语言的风格
plt.style.use('ggplot')
导入爬取数据及分析数据常用的第三方库,requests、numpy、pandas相信所有数据工程师都不陌生,最后,引入简单的数据可视化库matplotlib,通过图标显示更加直观。
网页抓取数据抓取前,需要根据需求进行网页分析,都哪里获取所需的字段。
分析排行榜网页构造 根据规则抓取TOP榜10页 根据电源ID构造URL抓取详情页# 猫眼榜单Url
base_url = 'https://maoyan.com/board/4?offset=%d'
# 存储抓取数据
# film = [fid, rank, title, cover, roles, realease_time, score,
# genres, country, duration]
movies = []
# 反爬取设置
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
'Host': 'maoyan.com',
'Referer': 'https://maoyan.com/board'
}
# 解析电影数据
def parse_movie(html):
soup = BeautifulSoup(html, 'lxml')
dd_list = soup.find_all('dd')
for item in dd_list:
# 通过链接地址,正则匹配出ID
fids = re.findall('\d+$', item.select_one('.image-link')['href'])
movie = {
'rank': item.select_one('.board-index').text, # 影片排名
'fid': fids[0] if len(fids) > 0 else 0, # 影片ID, 通过正则匹配
'title': item.select_one('.image-link')['title'], # 影片名称
'cover': item.select_one('.poster-default')['src'], # 封面图
'roles': item.select_one('.star').text.strip(), # 演员信息
'realease_time': item.select_one('.releasetime').text.strip(), # 上映时间
'score': item.select_one('.integer').text + item.select_one('.fraction').text # 影片得分
}
movies.append(movie)
def crawl_film(fid):
"""抓取电源详情信息"""
film_url = 'https://maoyan.com/films/%d' % int(fid) # 构造电源详情页url
headers = {
'User-Agent': UserAgent().random,
'Host': 'maoyan.com',
'Referer': 'https://maoyan.com/board/4'
}
req = requests.get(film_url, headers=headers)
req.encoding = 'utf-8'
if req.status_code == 200:
# 解析电影信息
soup = BeautifulSoup(req.text, 'lxml')
lis = soup.find_all('li', class_='ellipsis')
print(lis)
if len(lis) > 0:
# 题材
genres = []
for a in lis[0].select('a'):
genres.append(a.text)
# 国家地区 时长
country, duration = lis[1].text.strip().split('\n')
duration = duration.replace('/', '').lstrip()
# 附加信息
movies_extra.append((fid, genres, country, duration))
准备工作完毕,开始执行~
# 构造10个页面url
for page in range(10):
page_url = base_url % int(page*10)
if page > 0:
header['Referer'] = 'https://maoyan.com/board/4?offset=%d' % int((page-1)*10)
# 发起请求
req = requests.get(page_url, headers=header)
print('request url[%s], page[%d], status code[%d]' % (page_url, page, req.status_code))
if req.status_code == 200:
# print(req.text)
parse_movie(req.text)
# 强制等待5秒
time.sleep(5)
自定义构造榜单10页,抓取电影的基本信息,暂时存入movies列表里,然后,遍历movies获取电影的详情页内容,国家地区、电影题材、时长等。
# 详情页获取附加信息
movies_extra = []
for movie in movies:
print('Request film[%d]...' % int(movie['fid']))
crawl_film(movie['fid'])
# 强制等待5秒
time.sleep(5)
OK,至此数据准备完毕~
不得不说,猫眼电影在反爬方面,做的还是相当全面的,以下是遇到的问题:
反爬1:页面跳转安全中心,解决方法:添加headers的Referer 爬取中文乱码问题, 解决方法:req.encoding为utf-8 反爬2:页面不存在问题, 解决方法:添加cookie信息 反爬3:页面字体加密问题,解决方法:woff2otf 数据分析数据导入pandas的DataFrame,并进行基本信息及扩展信息的合并。
df_movie = pd.DataFrame(movies)
df_movie_extra = pd.DataFrame(movies_extra, columns=['fid', 'genres', 'country', 'duration'])
# 合并DataFrame
df_movie_all = pd.merge(df_movie, df_movie_extra, on='fid')
再次,数据合并完整,对于原始数据我们最好保存下来,供以后再做学习与实践~
# 保存文件
df_movie_all.to_excel('./datas/maoyan_films_top100.xlsx', index=False)
数据清洗和处理
# 对字符串进行替换处理
df_movie_all.loc[:, 'duration'] = df_movie_all['duration'].str.replace('分钟', '')
df_movie_all.loc[:, 'roles'] = df_movie_all['roles'].str.replace('主演:', '')
# 1、通过替换,截取,日期转化等提取出年份
def repair_date(df_x):
"""分割出日期"""
r = re.match(r'(\d{4})[\-(\d{2})]?[\-(\d{2})]?', df_x['realease_time'])
if len(r.groups()) == 1:
# 此次分析对月份及日数值关系不大,固定补全
return '%s-06-01' % r.groups()[0]
else:
return '-'.join(r.groups())
# 对固定字符串进行替换处理
df_movie_all.loc[:, 'realease_time'] = df_movie_all['realease_time'].str.replace('上映时间:', '')
# 上映时间里含国家等字符串,通过Series.str.slice_replace替换处理
df_movie_all.loc[:, 'realease_time'] = df_movie_all['realease_time'].str.slice_replace(start=10, repl='')
# 补全日期
df_movie_all.loc[:, 'realease_time'] = df_movie_all.apply(repair_date, axis=1)
# datetime转化
df_movie_all.loc[:, 'realease_time'] = pd.to_datetime(df_movie_all['realease_time'])
# 提取出年份
df_movie_all.loc[:, 'year'] = df_movie_all['realease_time'].dt.year
# 2、其实,如果仅分析数据年份的需求,直接通过数据字符串中截取出年份,更为简单方法;
字符串及日期处理后,需要对国家、题材、主演等字段进行拆分,便于接下来的聚类统计。
# 拆分角色列
df_movie_all = df_movie_all.drop('roles', axis=1).join(
df_movie_all['roles'].str.split(',', expand=True).stack()
.reset_index(level=1, drop=True).rename('roles'))
# 拆分国家列
df_movie_all = df_movie_all.drop('country', axis=1).join(
df_movie_all['country'].str.split(',', expand=True).stack()
.reset_index(level=1, drop=True).rename('country'))
# 拆分题材列
df_movie_all.loc[:, 'genres'] = df_movie_all['genres'].str.strip("[\'\n\t\s\]")
df_movie_all = df_movie_all.drop('genres', axis=1).join(
df_movie_all['genres'].str.split(',', expand=True).stack()
.reset_index(level=1, drop=True).rename('genres'))
df_movie_all.loc[:, 'genres'] = df_movie_all['genres'].str.strip("\s\'")
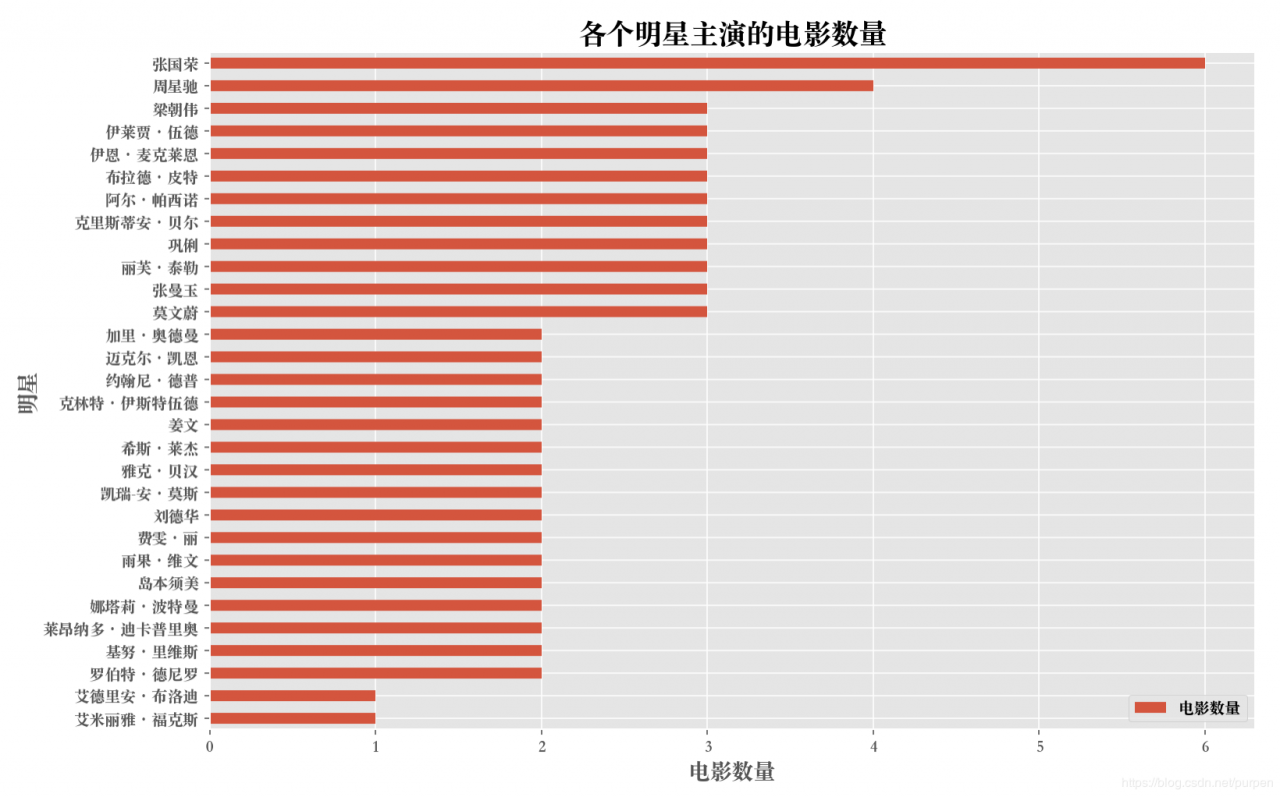
分析1:最耀眼的明星排行
stars_data = df_movie_all.groupby('roles').agg({ 'fid': 'nunique' }).sort_values(by='fid', ascending=False)
stars_data.columns = ['电影数量']
# 主演太多,这里仅取前30个进行展示
stars_data = stars_data[:30]
stars_data = stars_data.sort_values(by='电影数量', ascending=True)
# 绘制柱状图
stars_data.plot.barh(figsize=(12, 8))
plt.xlabel('电影数量', fontsize=14)
plt.ylabel('明星', fontsize=14)
plt.title('各个明星主演的电影数量', fontsize=18)
year_data = df_movie_all.groupby('year').agg({ 'fid': 'nunique' })
year_data.columns = ['电影数量']
# 绘制柱状图
year_data.plot.bar(figsize=(12, 8))
plt.xticks(range(len(year_data.index.to_list())), year_data.index.to_list(), rotation=45)
plt.xlabel('年份', fontsize=14)
plt.ylabel('数量', fontsize=14)
plt.title('各个年份诞生电影的数量', fontsize=18)

df_movie_all.loc[:, 'genres'] = df_movie_all['genres'].str.strip()
genres_data = df_movie_all.groupby('genres').agg({ 'fid': 'nunique' }).sort_values(by='fid', ascending=False)
freqs = genres_data['fid'].to_list()
print(freqs)
labels = ['%s / %d个' % (l, v) for l, v in zip(genres_data.index.to_list(), freqs)]
explode = []
for i in range(len(genres_data.index.to_list())):
if i > 3:
explode.append(0.01)
else:
explode.append(0.05)
# 绘制饼图
plt.figure(figsize=(12, 8))
plt.axis('equal') # 饼图长宽相等
plt.pie(freqs,
labels=labels,
explode=explode,
autopct='%1.1f%%',
shadow=False,
startangle=150)
plt.legend(loc='upper right',
fontsize=12,
bbox_to_anchor=(1.15, 1.0),
borderaxespad=1.5)
plt.title('最受欢迎的电影题材分布', fontsize=18)

country_data = df_movie_all.groupby('country').agg({ 'fid': 'nunique' }).sort_values(by='fid', ascending=False)
分析5:TOP100 评分分布
score_data = df_movie_all.groupby('score').agg({ 'fid': 'nunique' })
# 绘制折线图
plt.figure(figsize=(12, 8))
plt.plot(score_data)
plt.xlabel('评分', fontsize=14)
plt.ylabel('数量', fontsize=14)
plt.title('评分与数量的变化', fontsize=18)
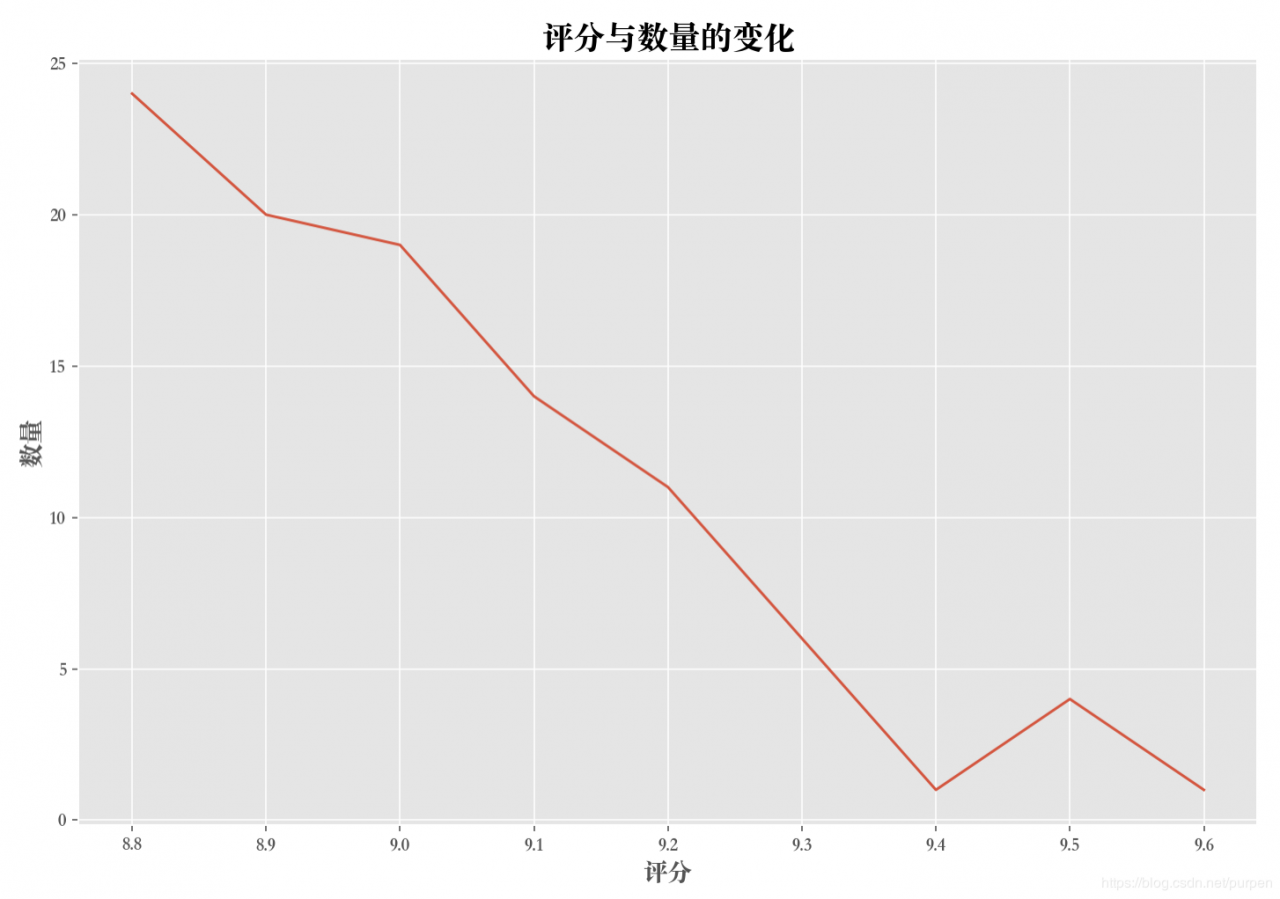
从图可以看出TOP100质量之高,最低评分8.8,更有甚者最高分9.6,特别的好奇,到底是哪个大师之作,能这么受欢迎?
# 查看第一条
top1_data = df_movie_all.loc[df_movie_all.score == 9.6][:1]

没错,就是星爷最经典大话西游之月光宝盒,这部让很多人爱情共鸣的大作。
至此,对电影从数据抓取、清洗、处理及分析全过程,全部结束,当然,还有很多好玩的点,有机会继续玩起来~
作者:叶小乙研习社