爬虫入门------从数据看奥斯卡陪跑健将到底是谁?学院派评委都热衷于哪类电影?
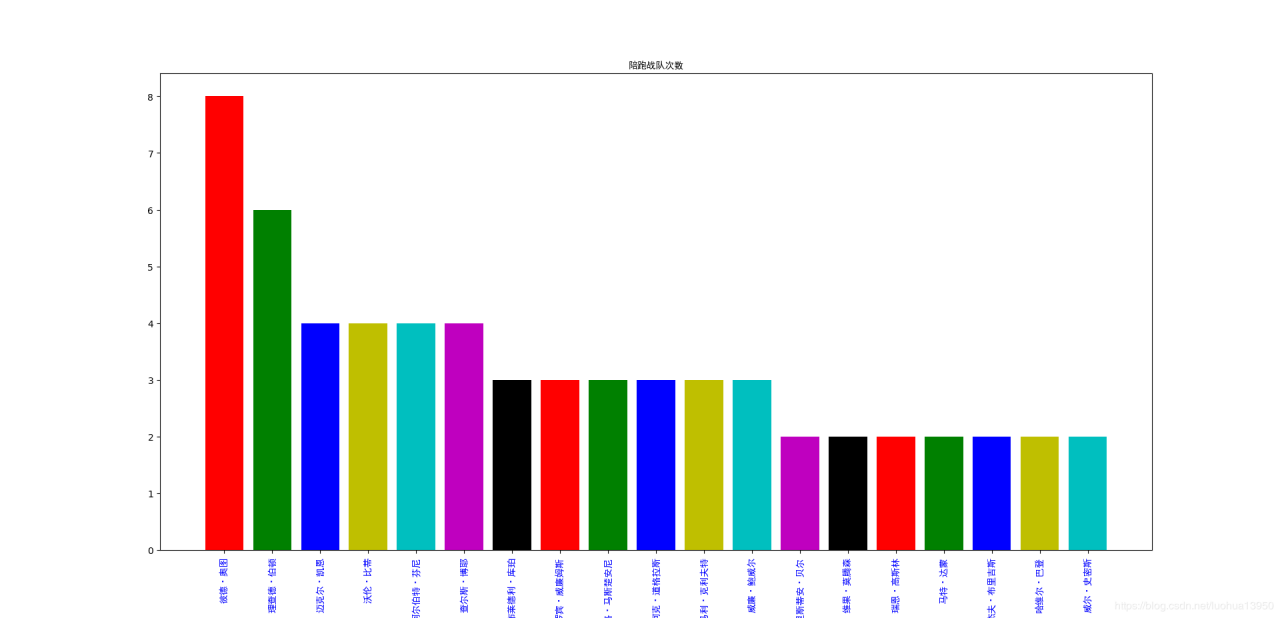
奥斯卡颁奖季虽已过去有些日子,《寄生虫》夺得最佳影片,《1917》也不拉下风,全片的长镜头的确震撼,这都不是今天要蹭的过气热点。作为一个电影死忠,当然还是想通过数据看看谁是奥斯卡男主最优陪跑员,谁又是白给先锋,奥斯卡派评委都热衷于哪类电影,以前总是听说小李子一直在陪跑(不过他在16年就凭借《荒野猎人》中的出色表现夺得最佳男主,还记得大众网友烧香拜佛来保佑他夺冠),今天就通过爬取一些历年数据看看是不是正如影迷们所说那个维密收割机–小李子才是陪跑之王。
准备工作 所用到一些工具 requests lxml pymongo pandas xpath-helperrequests就不用多说了,凭此库可以满足80%的爬虫任务了;
lxml库主要是使用xpath进行提取网页中的一些数据;
pymongo是为了将提取的一些非结构化数据进行存储,前面已有一篇介绍的文章MongoDB快速学习,有兴趣的可以点击看看一下一些基本的安装增删改查等等;
pandas这么无情的库就不用多介绍了吧,本文用它来读取MongoDB中的数据;
xpath-helper是一个直接可以在网页上使用xpath表达式提取信息的工具,需要自己安装,如没有安装包,请私信或留言联系我。
个人认为选取目标首先还是选择那些突破反爬比较容易的网站,这样可以节省很多时间,不过也可以尝试反爬还可以的,这样可以锻炼技巧,各有利弊。本次选择了时光网,因为有几个榜单就是专门提供各大奖的历史信息,不用特意去找,信息比较集中。
确认提取链接首先登录时光网首页,拉到最下面找到特色榜单选项,点击进入:
然后搜索"奥斯卡":
进入搜索结果页面:

上图用箭头标注的即想要的结果,点击奥斯卡历届最佳男主演,进入页面:
按照惯例,按F12打开开发者选项,刷新页面,查看请求,一般数据要么在html页面,要么通过json格式,如果请求列表中数据较多,你可以点击XHR来查看json请求,但是你会发现此选项下面并没有请求,这时就选Doc来查看html请求:
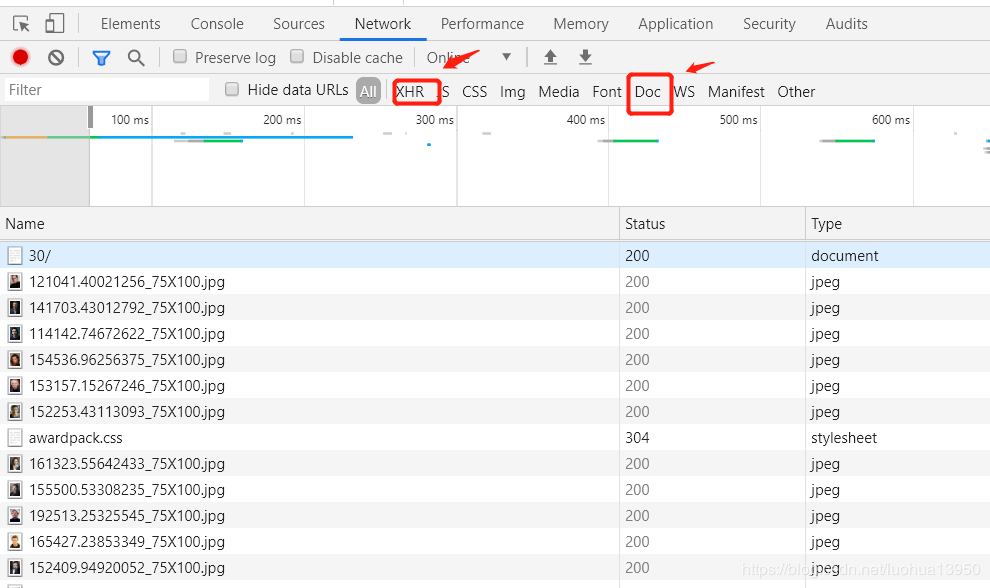
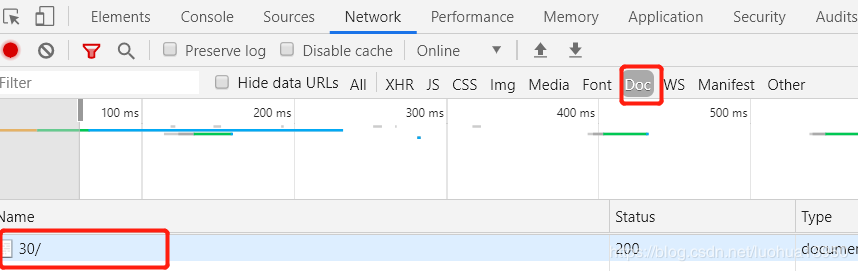
doc下面刚好只有一个请求,直接点进去:
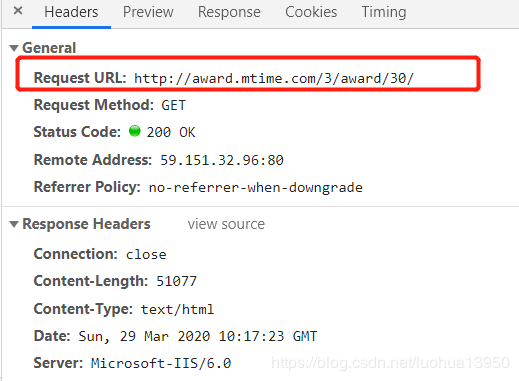
标红的为后面要用的请求url,请求方法是get,get,get重要的东西说三遍~~,这些要记住,然后切换到Response页面,Ctrl+F搜索一个页面上看到的词随便一个就行,以此来确认你找到的这个请求链接是正确的,我这里搜的是华金·菲尼克斯:
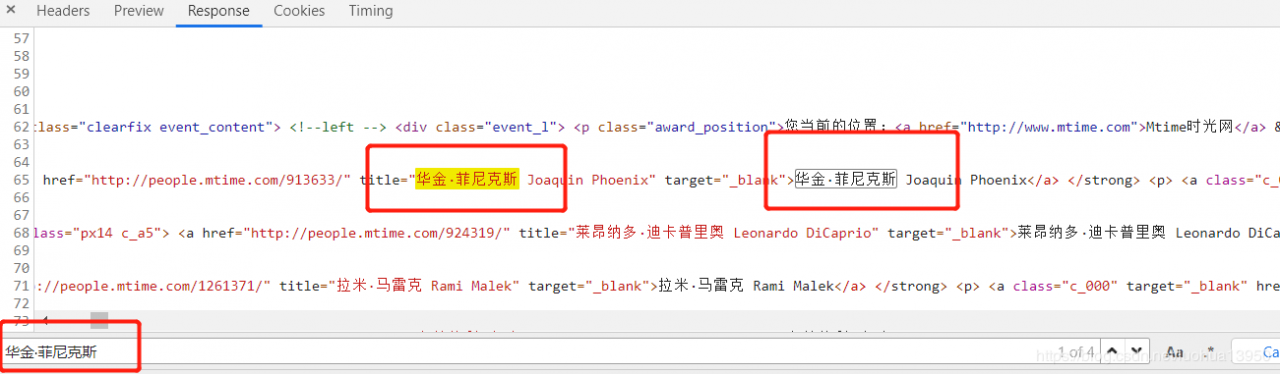
可以看到是有结果的,这说明我们的链接没问题,接下来就开始提取想要的内容了。
将页面切到Element,这里是网页的源代码,我们所需的信息均可以从这里提取,打开xpath-helper,页面介绍如下:
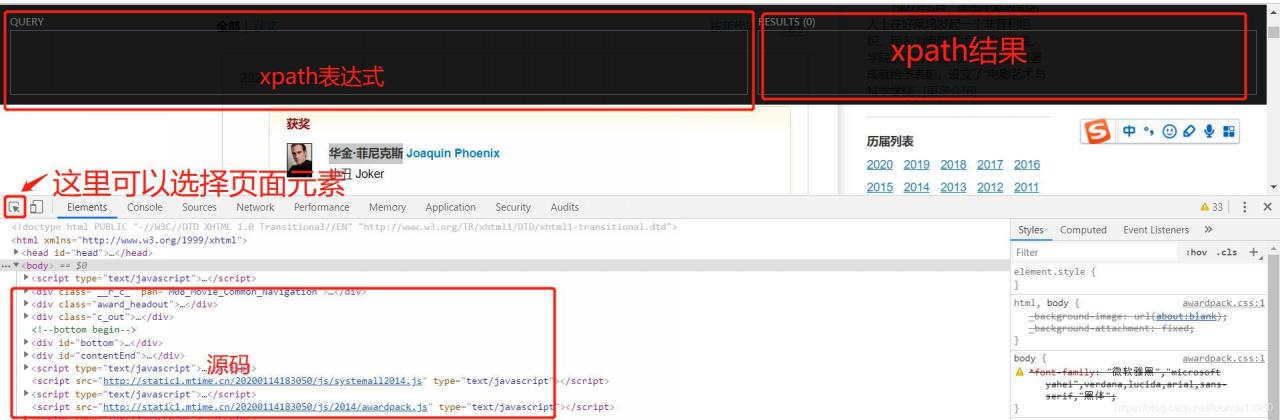
这里就暂时不介绍xpath语法了,直接进行查询使用了,以后会考虑专门出一篇xpath语法博客。
点击箭头选择想要的元素,如最佳男演员获奖者:
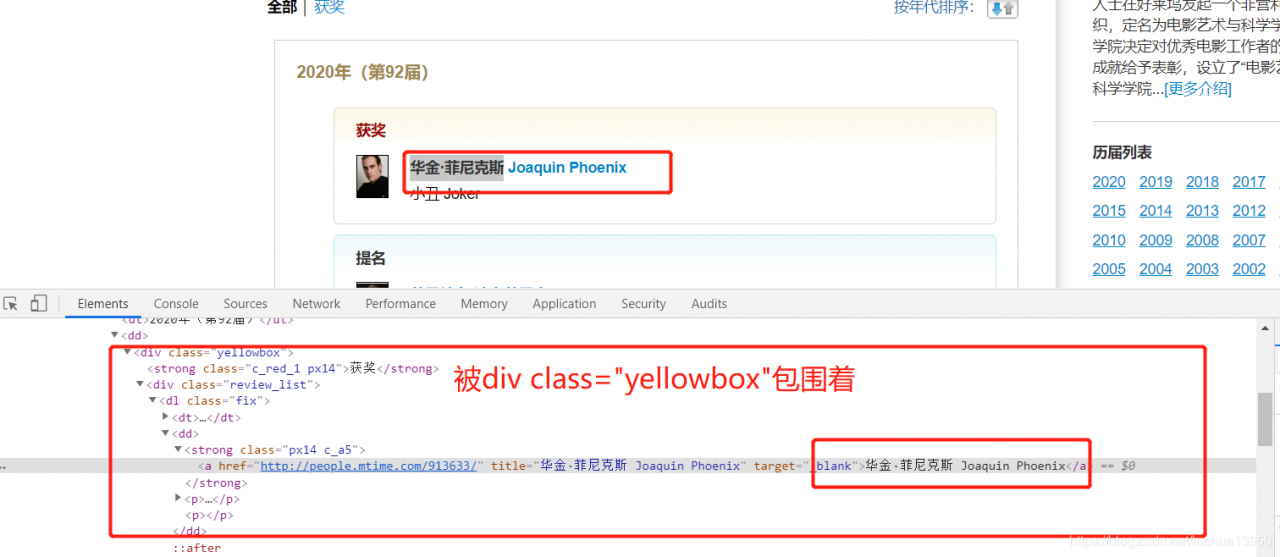

所以获奖者的外层元素为(div class=‘event_awards event_list’)—>(dl)–>(div class=‘yellowbox’)–>(div class=‘review_list’)–>(dl class=‘fix’)---->(dd)–>(strong class='px14 c_a5)–>a,可以编写xpath语句进行测试:


年份可以一次提取到,最后在代码里对应一下即可。
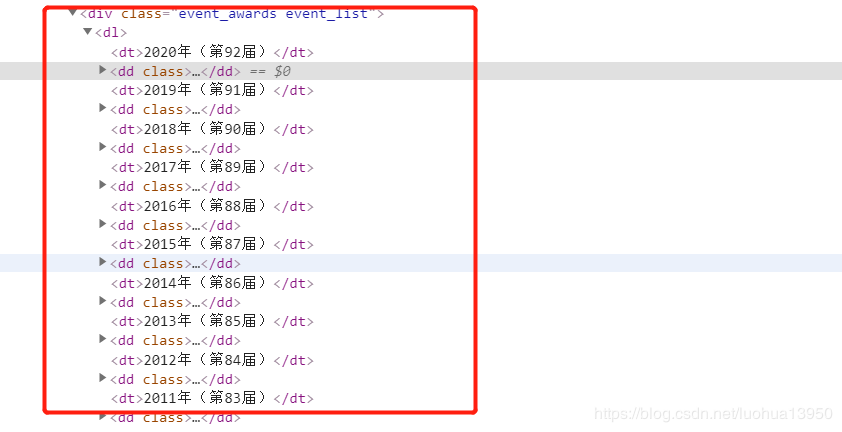
由上所示每一年都在dd标签中,代码中循环读取即能读到所有年份的数据,这里再提一下提名者是在div class='bluebox'下,提取方法与前一个yellowbox一样。
这里使用Python类进行提取,只介绍主要的部分了:
导入库import requests
import random
import json
import re
import time
from lxml import etree
from ua import USER_AGENT #请求头集合
from spider.dbs import StoreData #自己写的一个打开mongdb数据库的类
StoreData
class StoreData():
def __init__(self, host="127.0.0.1", db="douban", port=27017):
self.host = host
self.port = port
self.client = self.connect(host, port)
def connect(self, host, port):
return MongoClient(host, port)
初始化
class Mtime():
def __init__(self):
self.osc_first_url= "http://award.mtime.com/3/award/31/" #第一页链接
self.osc_url = "http://award.mtime.com/3/award/31/index-{}.html"##第二页开始链接
self.db = StoreData().client["movie"] #mongodb
self.session =requests.Session() # 创建session对象,保持cookies
链接在前面已经说过了,有一点忘记提了,第一页链接和第二页链接不太一样,不能用通用的链接方式,具体看上面代码里。
下载函数注意一定要用user-agent,这是基本反反爬。
def download_page(self,url,**headers_kwargs):
user_agent = random.choice(USER_AGENT)
headers = {
"User-Agent": user_agent,
}
if headers_kwargs:
headers.update(headers_kwargs)
#get方法,前面截图里面已经注释过
resp = self.session.get(url, headers=headers)
return resp
解析函数
下面直接上提取解析代码,不太懂的看一下注释。
def parser(self,text):
#将html文本转为etree类型,为了使用xpath
xp_html = etree.HTML(text)
##年份提取
year = xp_html.xpath("//div[@class='event_awards event_list']/dl/dt/text()")
## 所需的信息都在这里面,只需要在后面循环读取
all_movie= xp_html.xpath("//div[@class='event_awards event_list']/dl/dd")
for y,movie in zip(year,all_movie):
try:
## 获奖影片解析规则
#这里是为了防止空,与scrapy的extract_fistrt()一样
_winning_movie = movie.xpath("div[@class='yellowbox']//strong[@class='px14 c_a5']/a/text()")
winning_movie = _winning_movie[0].split()[0] if _winning_movie else ""
## 获奖人的链接
_href = movie.xpath("div[@class='yellowbox']//strong[@class='px14 c_a5']/a/@href")
href = _href[0] if _href else ""
## 提名人员
_nominated_movie = movie.xpath("div[@class='bluebox']//strong[@class='px14c_a5']//a/text()")
nominated_movie = _nominated_movie if _nominated_movie else ""
nominated_movie = [nm.split()[0] for nm in nominated_movie]
## 提名人员链接
_nominated_href = movie.xpath("div[@class='bluebox']//strong[@class='px14c_a5']//a/@href")
nominated_href = _nominated_href if _nominated_href else ""
# 提取四位年份,这里是因为解析结果是类似于2020年(第92届)这样的,所以要稍微处理一下
_yy = re.findall("\d{4}",y)
yy = _yy[0] if _yy else ""
## 提取届次
_sessions = re.findall("第(\d{2,3})届",y)
sessions = _sessions[0] if _sessions else ""
award_info = {
"年份":yy,
"届次":sessions,
"获奖":winning_movie,
"获奖影片链接":href,
"提名":nominated_movie,
}
#award_info .update(inner_context)
print(award_info)
#存储到mongdb中
#actor为我MongoDB movie数据库里的一个集合名
ret = self.db["actor"].insert(award_info)
print(ret)
except Exception as e:
print(e)
主函数
def main(self):
for i in range(1,10):
#判断是否是第一页,以此控制url
if i == 1:
url = self.osc_first_url
else:
url = self.osc_top100.format(i)
resp =self.download_page(url)
#解决中文乱码
resp.encoding = "utf-8"
self.parser(resp.text)
#一共就10页,慢慢爬无所谓,不要影响人家的性能
rd = random.randint(5,15)
print("睡眠{}秒".format(rd))
time.sleep(rd)
爬取结果
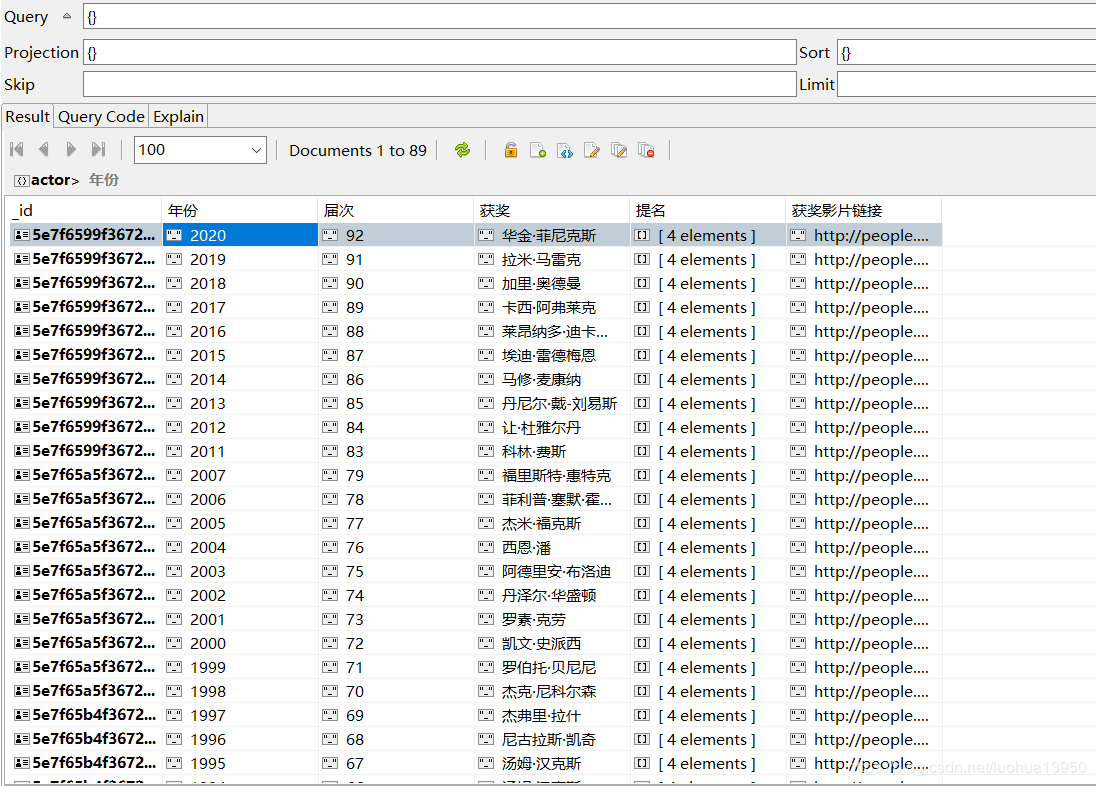
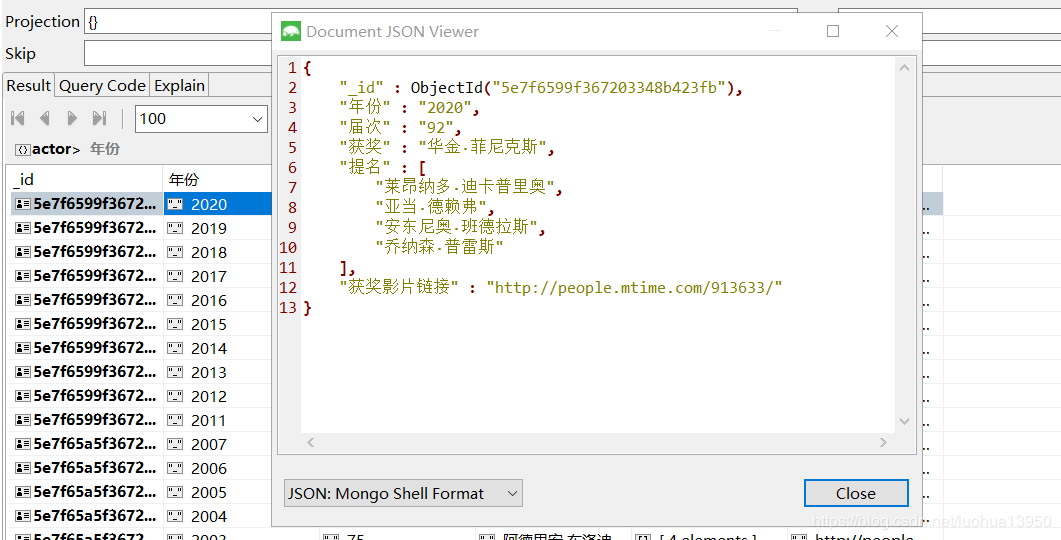
这是MongoDB的展示结果,顺便一提这个MongoDB可视化软件还不错,有需要的可以私信、留言,老外的产品,不是打广告哦。
至此就爬取完了最佳男演员的数据,因为这几个榜单前端模板都一样,最佳影片也是同理,修改一下url链接即可。
数据可视化 读取数据只需从MongoDB中读取数据,这里使用的是pandas库,下面是链接数据库和读取过程:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from spider.dbs import StoreData
import collections
#如果要显示中文则需要设置字体
font = FontProperties(fname='C:\Windows\Fonts\simhei.ttf', size=10)
client = StoreData().client
mv = client["movie"]
act = mv["actor"]
oscar = mv["oscar"]
data = pd.DataFrame(list(act.find()))
osc = pd.DataFrame(list(oscar.find()))
matplotlib如果要显示中文则需要设置字体,参考上面,本文可视化相对简单,就只贴获奖次数前20的代码了:
#统计获奖次数
data["获奖"].value_counts()[:20].plot.bar()
#设置X轴样式
plt.xticks(color='blue',rotation=90,fontproperties=font)
plt.title("获奖次数前20",fontproperties=font)
plt.show()
获奖次数前20
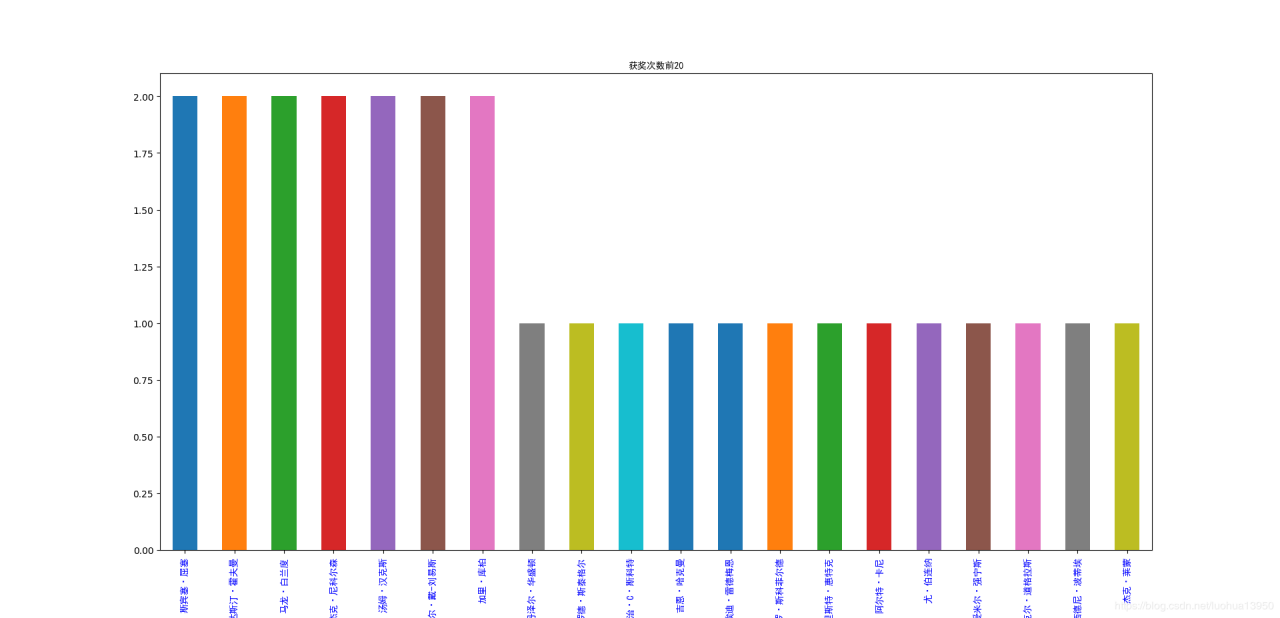
这里有点纳闷了,印象中丹尼尔·戴-刘易斯明明获奖获了3次,这里只显示了两次,经过我一番查看,发现时光上的丢失了2008-2010的数据(大家多包涵,懒得补充了,就用现在的数据了,大家就当做没看见,手动狗头保命)。
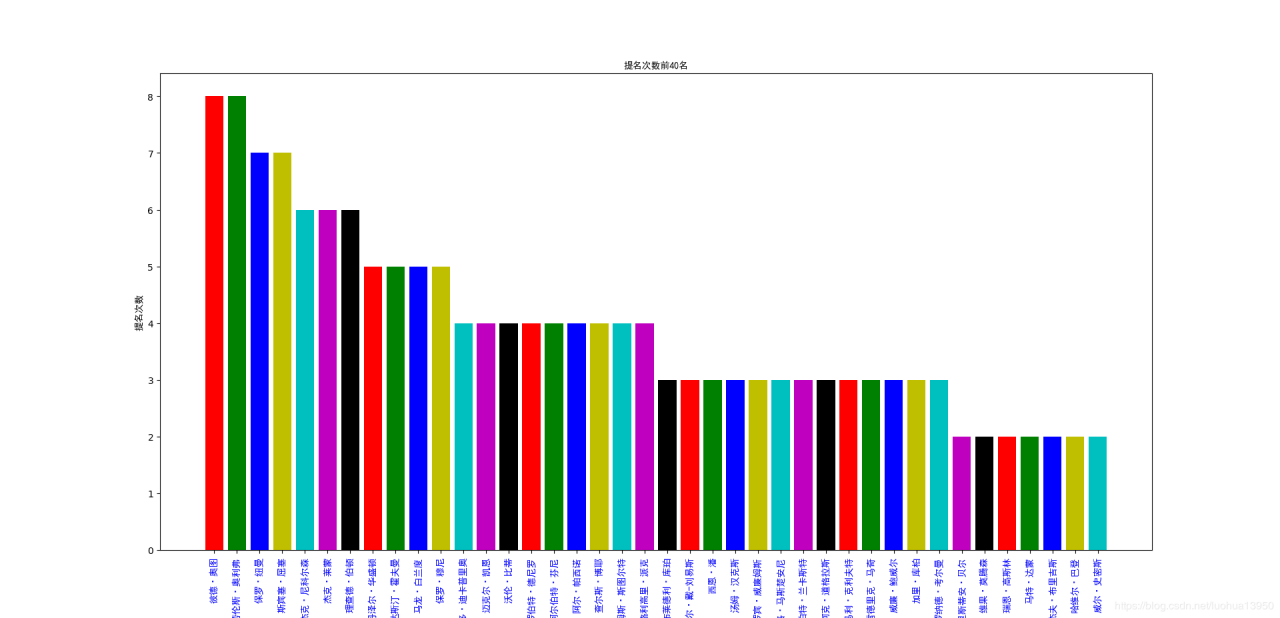
纳尼,小李子的提名居然才4次,高居榜首的是拍过《阿拉伯的劳伦斯》和《特洛伊》的彼得奥图和拍过《呼啸山庄》和《傲慢与偏见》的劳伦斯·奥利弗。
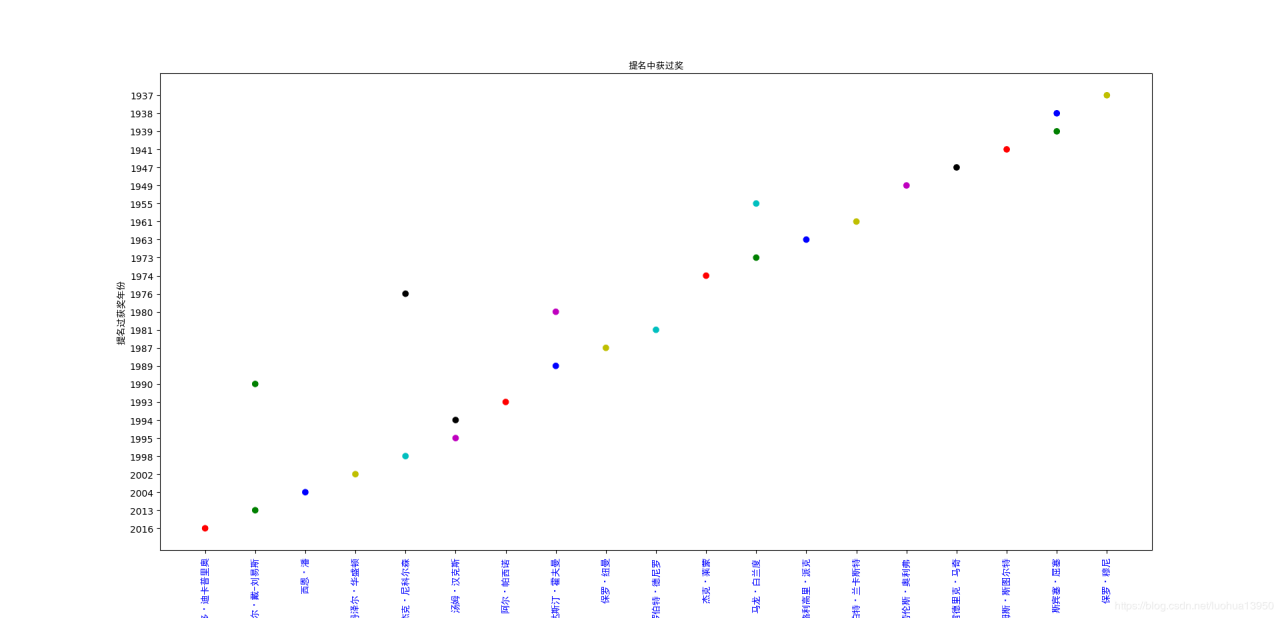
这次通过时间魔法把小李子强行排到第一位,哈哈。
心疼彼得奥图。
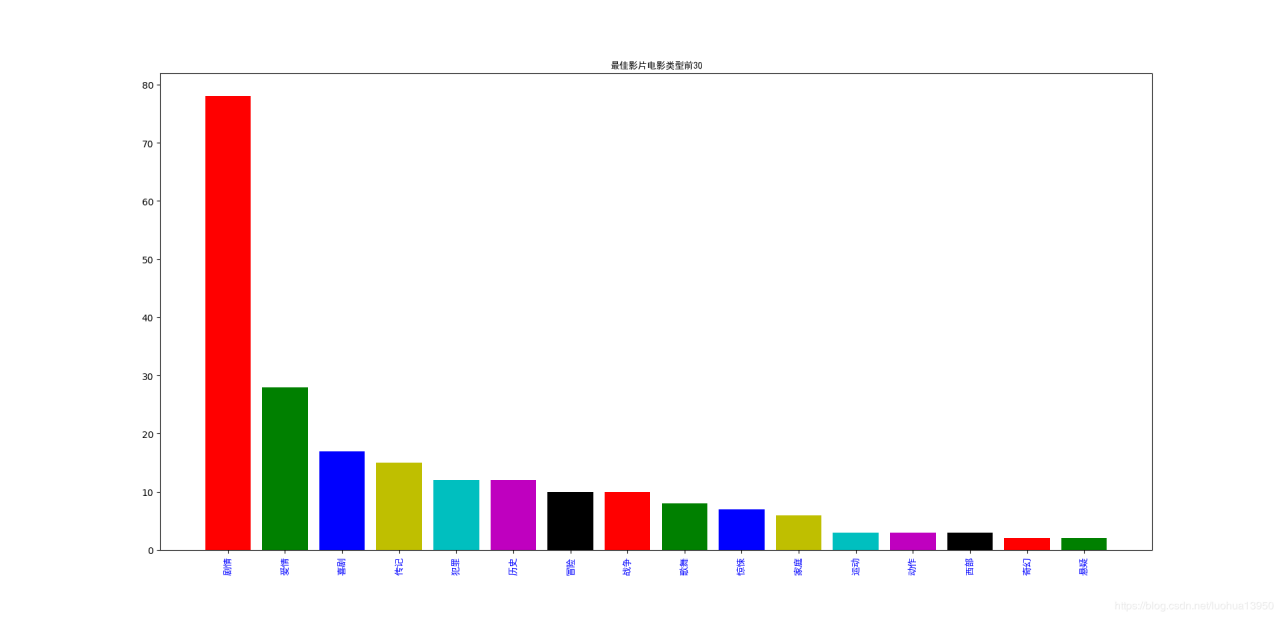
可以看到奥斯卡这些学院派评委还是相对喜欢剧情、爱情、喜剧、人物传记、犯罪、历史、战争两两组合或三三组合的电影,怪不得《盗梦空间》和《蝙蝠侠》没获奖。
本文简要的介绍了如何通过网页获取数据并进行一些数据可视化展示。
更多内容请关注从今天开始种树
关注知识图谱与大数据公众号,获取更多内容。

作者:luohua13950