混合模型:基于VGG-16+PCA+Meanshift/DBSCAN的图像分类
博主上次做的VGG16训练宝可梦多分类图像识别,5个每类,每个类别250张左右,训练数量并不多,但如果我的训练数量更少呢?因为在现实生活中,没办法穷尽所有的数据。我们期望更多的高质量数据:正常数据,穷尽类别,标注正确;但是现实大部分为普通数据:夹杂异常数据,包含部分类别,标注标准不一致。为了考虑这个问题,我们可以综合许多模型的优点。于是混合模型就出现了。
混合模型一般有是监督学习、无监督学习、机器学习和深度学习这四种混搭。本文采取的是监督+无监督学习,即半监督学习。
本文仅有10张原始数据集!仅有10张如何识别普通雷伊和其余形态雷伊?看看混合模型如何发挥它的强大之处。
环境是python3.6+keras,后端是tensorflow-gpu1.12.0,怎么配环境可以参考博主的博客哦。文末附预测结果及完整代码。
首先附上数据集
链接:https://pan.baidu.com/s/12y8YCbyldLW61wmDcC0fEw
提取码:d18p
训练集元旦期间兴致来了想玩玩赛尔号,回忆童年。发现赛尔号变得很坑啊,各种rmb,界面都不认识了。雷伊居然有10种形态!咳咳,好了回归正题。博主想去爬取雷伊各种形态图片,但是无奈游戏不火,没有大量的数据,恰好本文的模型就适合数据集极少情况的识别分类,于是到4399赛尔号上下载10种雷伊形态图片各一张。其中一张为原始雷伊,其余为各种形态的进化。原始训练集如下。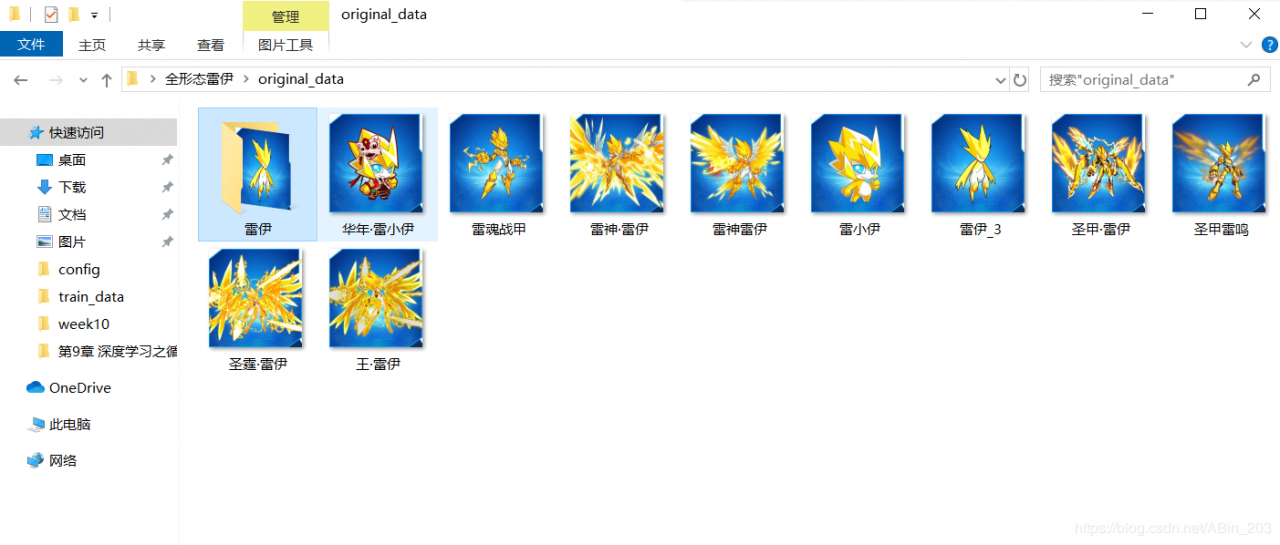
没错,就10张。其中有个雷伊文件夹,那个文件夹只有一张普通雷伊,博主下面会对这个文件夹作用进行介绍。
首先我们的模型要可以识别原来这10张图片,这是起码的要求。注意到4399都是蓝色背景的精灵,那为了检验模型,博主又找了3张白底的普通雷伊。如下所示。
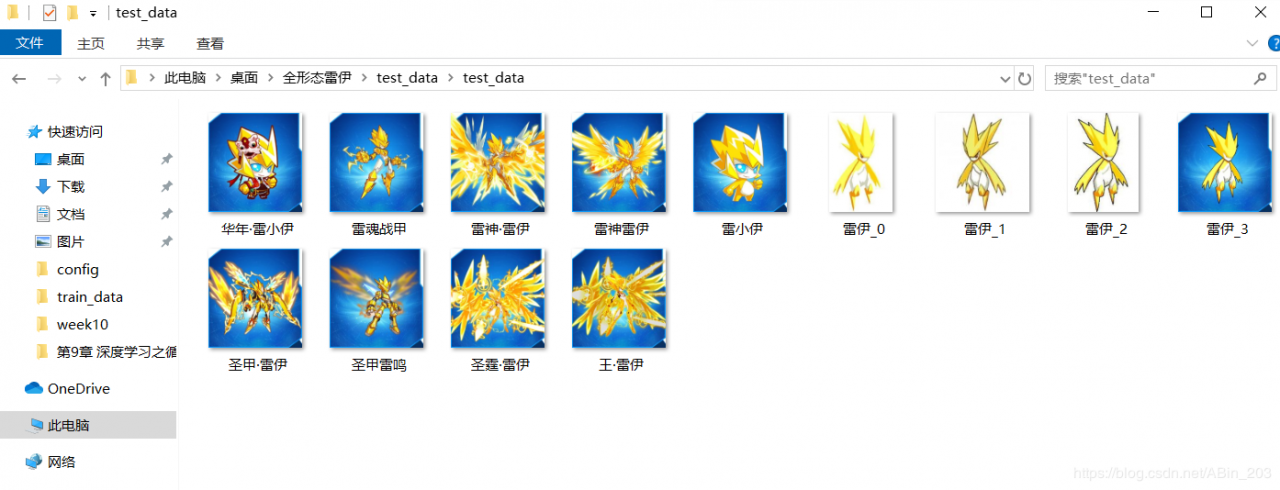
首先就是对那个只含有一张普通雷伊的文件夹功能进行解释,这是因为我们要进行数据增强,keras自带的数据增强函数非常强大,rotation_range=20表示 20°范围内的旋转,width_shift_range=0.2,表示水平移动的范围的百分比,height_shift_range=0.02,表示竖直移动的范围的百分比,horizontal_flip=True,水平翻转,vertical_flip=True表示竖直翻转。
增强数据集的方法必须是要把待增强的图片放入文件夹,从方法名(flow_from_directory)就可以很直观看出,这也是为什么前文训练集要另外一个文件夹放普通雷伊的原因。
#数据增强
from keras.preprocessing.image import ImageDataGenerator
path = 'D:/桌面/全形态雷伊/original_data'#图片加强的文件路径
dst_path = 'D:/桌面/全形态雷伊/gen_data'
datagen = ImageDataGenerator(rotation_range=20,width_shift_range=0.2,height_shift_range=0.02,horizontal_flip=True,
vertical_flip=True)
gen = datagen.flow_from_directory(path,target_size=(224,224),
batch_size=3, save_to_dir=dst_path,
save_prefix='gen',save_format='png')
for i in range(200):
gen.next()

结果是自动寻找到一个文件夹也就是一类,输入产生增强数据的路径后,这样我们就产生了一张图片增强后的大量数据集。
对图片进行分类一般是卷积神经网络的强项,但是我们细分卷积神经网络,实际上它粗分可以分为2个阶段,一个是对数据特征的提取,一个是全连接层。卷积神经网络在图像分类上占一席之地的原因很大程度上是因为其提取数据特征十分到位。经过卷积把背景等无关因素淡化,突出待分类对象的主要特征。假如我们通过vgg16这一模型提取所有图像的特征数组,然后进行聚类分析。是不是就可以准确又快速呢?
下面就是vgg16对训练集的特征提取。如果有小伙伴看不太明白的话,博主的上一篇博客把每段功能都拿出来了,有更具体的分析。
# load image and preprocess it with vgg16 structure
from keras.preprocessing.image import img_to_array, load_img
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
import numpy as np
import os
from sklearn.preprocessing import LabelBinarizer
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import recall_score
import matplotlib as mlp
import matplotlib.pyplot as plt
from matplotlib.image import imread
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
from keras.models import load_model
from PIL import Image
# 载入VGG16结构(去除全连接层)
model_vgg = VGG16(weights='imagenet', include_top=False)
# imagenet表示加载提取图片特征的结构,然后Flase表示去除全连接层
# define a method to load and preprocess the image
def modelProcess(img_path, model):
img = load_img(img_path, target_size=(224, 224)) # 读取图片途径,裁成224,224
img = img_to_array(img) # 转换成图像数组
x = np.expand_dims(img, axis=0) # 加一个维度这样能载入VGG
x = preprocess_input(x) # 预处理
x_vgg = model.predict(x) # 特征提取,这是全连接层之前的shape
# shape(1,7,7,512)
x_vgg = x_vgg.reshape(1, 25088) # 摊开来进行和全连接层的对接
return x_vgg
# list file names of the training datasets
def transform_format(path): # 转换格式
folders = os.listdir(path) # 读取爷爷路径下的所有文件名,也就是5个分类标签
for j in range(len(folders)):
dirName = path + '//' + folders[j] + '//' # 每一个爸爸路径
li = os.listdir(dirName) # 每个爸爸路径,也就是那个类别文件夹下的全部图片名字
for filename in li:
newname = filename
newname = newname.split(".") # 文件名以'.'为分隔,
if newname[-1] != "png": # 这里转换格式用的是简单的重命名
newname[-1] = "png"
newname = str.join(".", newname) # 这里要用str.join
filename = dirName + filename
newname = dirName + newname
os.rename(filename, newname) # 重命名
print('reading the images:%s' % (newname)) # 这步前期我是用来调试哪张图的读取出问题了,现在可删可不删
a = np.array(Image.open(newname)) # 读取图片数组
if ((len(a.shape) != 3) or (a.shape[2] != 3)): # 有些图片非RGB,这里进行判断处理
a = np.array(Image.open(newname).convert('RGB')) # 换成RGB
img = Image.fromarray(a.astype('uint8')) # 形成图片
img.save(newname) # 替换原来的图片
print(a.shape) # 用来测试的print
print("全部图片已成功转换为PNG格式")
print("全部图片已成功转换为RGB通道")
def read_data(path):
folders = os.listdir(path) # 读取爷爷路径下的所有文件名,也就是5个分类标签
for j in range(len(folders)): # 5个种类嘛,一共循环5次
folder = path + '//' + folders[j] # 这个就是爸爸路径了
dirs = os.listdir(folder) # 读取爸爸路径下的所有文件名,就是各个图片名字了
# 产生图片的路径
img_path = []
for i in dirs:
if os.path.splitext(i)[1] == ".png": # 已经转换过png了
img_path.append(i)
img_path = [folder + "//" + i for i in img_path]
# 这里就是真正的儿子路径了,也就是每个图片的完整路径
# 开始处理
features1 = np.zeros([len(img_path), 25088]) # 弄好每个图片的数组框架
for i in range(len(img_path)):
feature_i = modelProcess(img_path[i], model_vgg) # 这就运用上面函数进行每张图片处理
print('preprocessed:', img_path[i])
features1[i] = feature_i
if j == 0: # 这边判断的目的是把5个分类的图片数组全部加到一起
X = features1 # 第一次循环,那就只有一个,注意j在最上面
else:
X = np.concatenate((X, features1), axis=0)
# 之后的每次循环把上一个种类的图片数组和这个种类的所有图片数组加到一起
return X # 最后就全部加到一起了,此时X是5个分类都在了,也就是全部训练集
path = 'D:/桌面/全形态雷伊/train_data' # 这个就是训练集的爷爷路径
test_path = 'D:/桌面/全形态雷伊/test_data' # 这个就是测试集的爷爷路径
transform_format(path)
transform_format(test_path)
X = read_data(path) # 读取训练数据
test_X = read_data(test_path) # 读取测试数据
print(X.shape)
print(test_X.shape)
正在读取数据中…
vgg16模型的特征提取固然强大,但是其维度实在太高,如果我们直接进行聚类分析,很有可能因为数据维度过高导致聚类时间过长,这和混合模型又准又快的特点不符,我们进行主成分分析,即PCA对其进行降维。
#PCA训练集降维
from sklearn.preprocessing import StandardScaler
stds = StandardScaler()
X_norm = stds.fit_transform(X) # 数据标准化
#PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=200) # 降到200维
X_pca = pca.fit_transform(X_norm)
#判定降维后能否保留大部分特征的得分
var_ratio = pca.explained_variance_ratio_
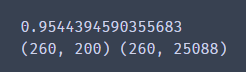
print(np.sum(var_ratio))
print(X_pca.shape,X.shape) # 前后维度
我们降到200维的时候,发现这个时候降维的得分是95分,这表明我们的PCA在尽可能保留数据原有特征的情况下,又能够降低数据的维度,减小后面聚类的运行时间。看评分的效果还是不错的。输出一下降维前后的shape,对比一下。从25088降到了200.
同理我们对测试集也进行降维,方便我们后面模型测试。
#PCA测试集降维
X_norm_test = stds.transform(test_X)
X_pca_test = pca.transform(X_norm_test)
var_ratio = pca.explained_variance_ratio_
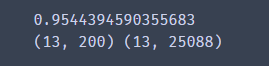
print(np.sum(var_ratio))
print(X_pca_test.shape,test_X.shape)
这里博主尝试过主流的一些聚类方法,发现meanshift和dbscan效果还算不错,如k-means就表现得不太好。博主过段时间做相关聚类的文章再进行分析,这里就先说结果了。
meanshift有个很重要的参数是带宽,可以理解为圆的半径,实际上很想一个圆一直往外拓展,看看有没有新的点被包含,如果有就继续以这个带宽拓展,若无则结束。这个带宽的定义不太好确定。但幸好sklearn有自带的确定带宽的方法。也就是下面代码的bw。
# meanshift训练集预测
from sklearn.cluster import MeanShift, estimate_bandwidth
# 自动获取meanshift带宽
bw = estimate_bandwidth(X_pca,n_samples=140)
print(bw)
# 设置模型
cnn_pca_ms = MeanShift(bandwidth=bw)
cnn_pca_ms.fit(X_pca)
# 预测
y_predict_pca_ms = cnn_pca_ms.predict(X_pca)
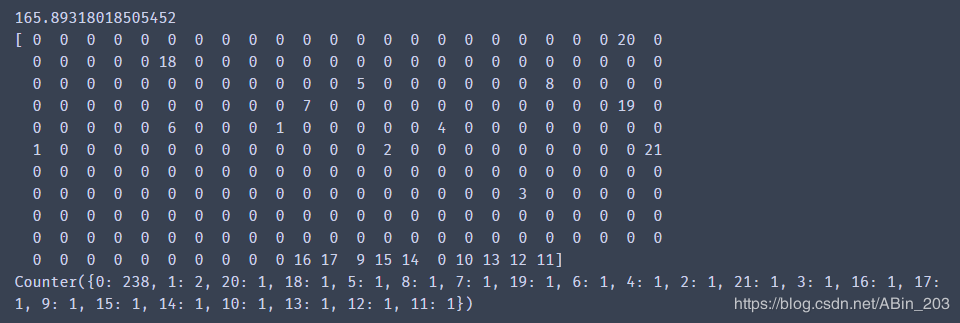
print(y_predict_pca_ms)
from collections import Counter
print(Counter(y_predict_pca_ms)) # 预测结果统计
#11
我们来对这个结果进行分析,我们发现,我们的训练集是前面一堆都是普通雷伊,后面才开始是10种形态。meanshift在后面10种形态成功识别出了一种普通雷伊,但是在前面的普通雷伊中,有的普通雷伊被识别成了其他雷伊。数了数有11个,但这11个都是前面普通雷伊错的,后面10种形态是全对的。
# meanshift测试集预测
y_predict_pca_ms_test = cnn_pca_ms.predict(X_pca_test)
print(y_predict_pca_ms_test)
对测试集进行预测,对比前文的测试集图片,我们发现meanshift很准,全对,连博主特意换成白色背景的普通雷伊都识别出来了。测试集100%识别。

这里是dbscan的聚类,dbscan有2个非常头疼的超参数,一个是eps,一个是min_samples,这两个参数就没办法通过sklearn自带的方法进行计算了,博主暂时不太精通也只能一直试错,发对于这个训练集,在eps=200, min_samples=4的时候效果挺好。
# DBSCAN训练集预测
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=200, min_samples=4) # 超参数设置
label_pred = dbscan.fit_predict(X_pca)
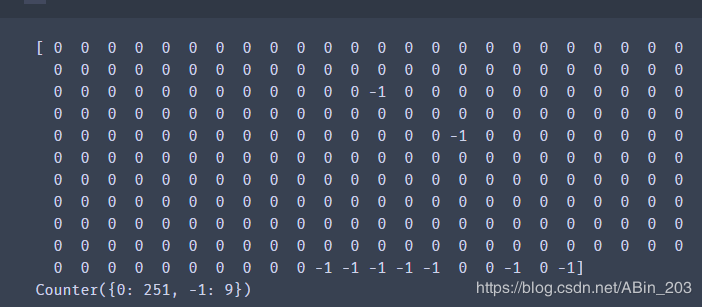
print(label_pred)
from collections import Counter
print(Counter(label_pred)) # 预测结果统计
#5
此时我们发现,dbscan相比于meanshift来说在前面一堆普通雷伊中犯错误的频率更小,但是在后面10种形态种错了2,而meanshift在后面10种形态的识别是全对的。总的来说,各有千秋。
dbscan的训练结果进行可视化
# DBSCAN_train
# 画出预测图及标签 要对中文进行设置 不然显示不出中文
font2 = {'family': 'SimHei', 'weight': 'normal', 'size': 20}
mlp.rcParams['font.family'] = 'SimHei'
mlp.rcParams['axes.unicode_minus'] = False
train_path = 'D:/桌面/全形态雷伊/train_data/train_data'
folders = os.listdir(train_path) # 传入训练集
num = len(folders)
fig = plt.figure(figsize=(10, 10 * (int(num / 9) + int(num % 9 / 3) + 1 * (num % 9 % 3))))
# 这一步的意思是,根据前期测试,10*10大小的图片放3*3,9张图片最佳
# 那就可以根据所有测试图片的数量来确定最后画出的图的大小
for j in range(num):
# 这些步骤其实都和前面差不多,就是对图片进行预处理,这样能够输入进网络
img_name = train_path + '/' + folders[j]
img_ori = load_img(img_name, target_size=(250, 250))
plt.subplot(int(num / 3) + 1, 3, j + 1)
# subplot就是一张大图里面有多少小图的意思,也是根据总共测试图的数量来确定的
plt.imshow(img_ori) # 展示
if label_pred[j]==0:
plt.title('预测为:雷伊') # 每个预测图题目写上预测结果
else:
plt.title('预测为:其余形态雷伊')
plt.subplots_adjust(top=0.99, bottom=0.003, left=0.1, right=0.9, wspace=0.18, hspace=0.15)
# 控制每个子图间距
plt.savefig('D://桌面//dbscan_train.png') # 保存咯,路径自己改下
图片太大无法上传就只能给大家看看部分的,这是截取训练集最后的十几种雷伊,我们发现dbscan如上文所说,在这里面错了2种。
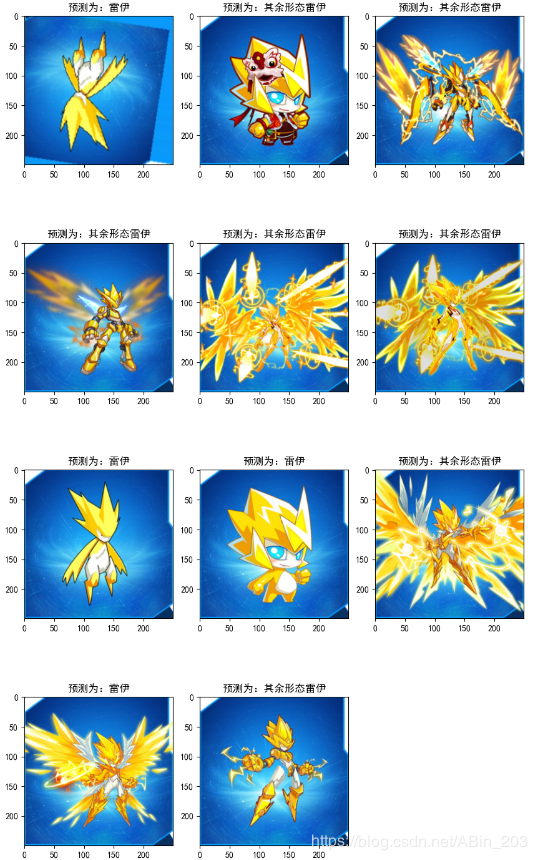
很遗憾的是dbscan没办法基于训练的模型来对测试集进行预测,所以没办法进行测试。
接下来我们对meanshift的训练结果可视化。
#ms_train
# 画出预测图及标签 要对中文进行设置 不然显示不出中文
font2 = {'family': 'SimHei', 'weight': 'normal', 'size': 20}
mlp.rcParams['font.family'] = 'SimHei'
mlp.rcParams['axes.unicode_minus'] = False
train_path = 'D:/桌面/全形态雷伊/train_data/train_data'
folders = os.listdir(train_path) # 传入训练集
num = len(folders)
fig = plt.figure(figsize=(10, 10 * (int(num / 9) + int(num % 9 / 3) + 1 * (num % 9 % 3))))
# 这一步的意思是,根据前期测试,10*10大小的图片放3*3,9张图片最佳
# 那就可以根据所有测试图片的数量来确定最后画出的图的大小
for j in range(num):
# 这些步骤其实都和前面差不多,就是对图片进行预处理,这样能够输入进网络
img_name = train_path + '/' + folders[j]
img_ori = load_img(img_name, target_size=(250, 250))
plt.subplot(int(num / 3) + 1, 3, j + 1)
# subplot就是一张大图里面有多少小图的意思,也是根据总共测试图的数量来确定的
plt.imshow(img_ori) # 展示
if y_predict_pca_ms[j]==0:
plt.title('预测为:雷伊') # 每个预测图题目写上预测结果
else:
plt.title('预测为:其余形态雷伊')
plt.subplots_adjust(top=0.99, bottom=0.003, left=0.1, right=0.9, wspace=0.18, hspace=0.15)
# 控制每个子图间距
plt.savefig('D://桌面//ms_train.png') # 保存咯,路径自己改下
一样的截取最后的部分,如上文所说,在最后的十几个图片种meanshift表现极佳,全对。
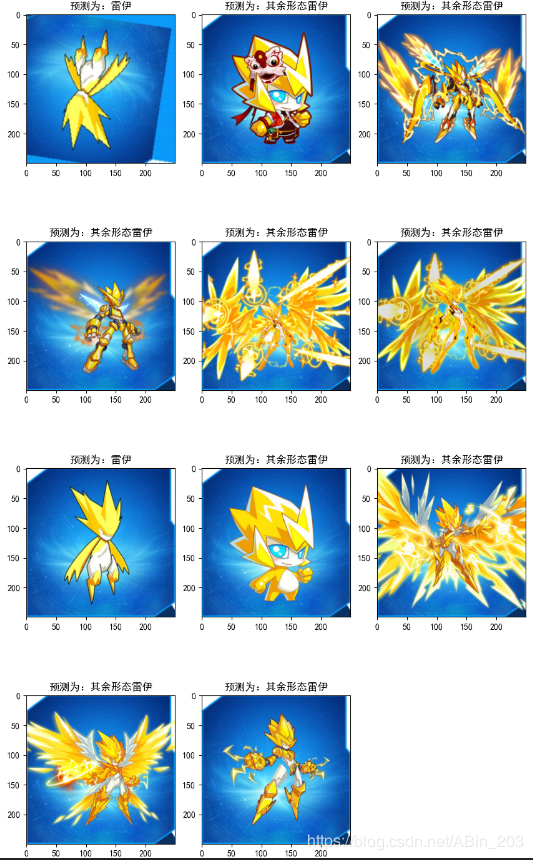
meanshift模型进行测试集的预测
#ms_test
# 画出预测图及标签 要对中文进行设置 不然显示不出中文
font2 = {'family': 'SimHei', 'weight': 'normal', 'size': 20}
mlp.rcParams['font.family'] = 'SimHei'
mlp.rcParams['axes.unicode_minus'] = False
train_path = 'D:/桌面/全形态雷伊/test_data/test_data'
folders = os.listdir(train_path) # 传入测试集
num = len(folders)
fig = plt.figure(figsize=(10, 10 * (int(num / 9) + 1)))
# 这一步的意思是,根据前期测试,10*10大小的图片放3*3,9张图片最佳
# 那就可以根据所有测试图片的数量来确定最后画出的图的大小
for j in range(num):
# 这些步骤其实都和前面差不多,就是对图片进行预处理,这样能够输入进网络
img_name = train_path + '/' + folders[j]
img_ori = load_img(img_name, target_size=(250, 250))
plt.subplot(int(num / 3) + 1, 3, j + 1)
# subplot就是一张大图里面有多少小图的意思,也是根据总共测试图的数量来确定的
plt.imshow(img_ori) # 展示
if y_predict_pca_ms_test[j]==0:
plt.title('预测为:雷伊') # 每个预测图题目写上预测结果
else:
plt.title('预测为:其余形态雷伊')
plt.savefig('D://桌面//ms_test.png') # 保存咯,路径自己改下
我们可以很清晰地观察出,meanshift模型对我们的测试集的预测达到了全对。连博主特地转换的白底雷伊也识别出来了。效果不错。
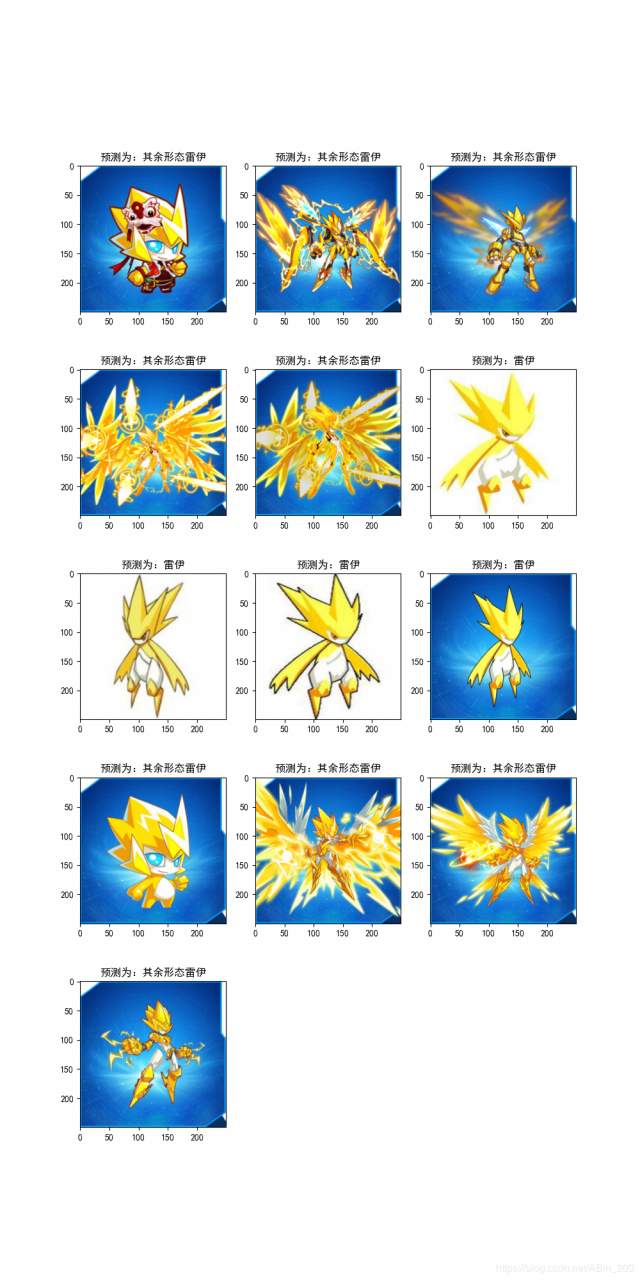
总的来说,混合模型具有的被混合的模型的优点,可以达到又快又准的效果。当然了,博主的分类过于简单,仅仅只是普通雷伊和其余形态雷伊的识别,但对于混合模型来说,最后的结果也有一定的参考性。
最后附上完整代码。
#数据增强
from keras.preprocessing.image import ImageDataGenerator
path = 'D:/桌面/全形态雷伊/original_data'#图片加强的文件路径
dst_path = 'D:/桌面/全形态雷伊/gen_data'
datagen = ImageDataGenerator(rotation_range=20,width_shift_range=0.2,height_shift_range=0.02,horizontal_flip=True,
vertical_flip=True)
gen = datagen.flow_from_directory(path,target_size=(224,224),
batch_size=3, save_to_dir=dst_path,
save_prefix='gen',save_format='png')
for i in range(200):
gen.next()
# load image and preprocess it with vgg16 structure
from keras.preprocessing.image import img_to_array, load_img
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
import numpy as np
import os
from sklearn.preprocessing import LabelBinarizer
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import recall_score
import matplotlib as mlp
import matplotlib.pyplot as plt
from matplotlib.image import imread
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
from keras.models import load_model
from PIL import Image
# 载入VGG16结构(去除全连接层)
model_vgg = VGG16(weights='imagenet', include_top=False)
# imagenet表示加载提取图片特征的结构,然后Flase表示去除全连接层
# define a method to load and preprocess the image
def modelProcess(img_path, model):
img = load_img(img_path, target_size=(224, 224)) # 读取图片途径,裁成224,224
img = img_to_array(img) # 转换成图像数组
x = np.expand_dims(img, axis=0) # 加一个维度这样能载入VGG
x = preprocess_input(x) # 预处理
x_vgg = model.predict(x) # 特征提取,这是全连接层之前的shape
# shape(1,7,7,512)
x_vgg = x_vgg.reshape(1, 25088) # 摊开来进行和全连接层的对接
return x_vgg
# list file names of the training datasets
def transform_format(path): # 转换格式
folders = os.listdir(path) # 读取爷爷路径下的所有文件名,也就是5个分类标签
for j in range(len(folders)):
dirName = path + '//' + folders[j] + '//' # 每一个爸爸路径
li = os.listdir(dirName) # 每个爸爸路径,也就是那个类别文件夹下的全部图片名字
for filename in li:
newname = filename
newname = newname.split(".") # 文件名以'.'为分隔,
if newname[-1] != "png": # 这里转换格式用的是简单的重命名
newname[-1] = "png"
newname = str.join(".", newname) # 这里要用str.join
filename = dirName + filename
newname = dirName + newname
os.rename(filename, newname) # 重命名
print('reading the images:%s' % (newname)) # 这步前期我是用来调试哪张图的读取出问题了,现在可删可不删
a = np.array(Image.open(newname)) # 读取图片数组
if ((len(a.shape) != 3) or (a.shape[2] != 3)): # 有些图片非RGB,这里进行判断处理
a = np.array(Image.open(newname).convert('RGB')) # 换成RGB
img = Image.fromarray(a.astype('uint8')) # 形成图片
img.save(newname) # 替换原来的图片
print(a.shape) # 用来测试的print
print("全部图片已成功转换为PNG格式")
print("全部图片已成功转换为RGB通道")
def read_data(path):
folders = os.listdir(path) # 读取爷爷路径下的所有文件名,也就是5个分类标签
for j in range(len(folders)): # 5个种类嘛,一共循环5次
folder = path + '//' + folders[j] # 这个就是爸爸路径了
dirs = os.listdir(folder) # 读取爸爸路径下的所有文件名,就是各个图片名字了
# 产生图片的路径
img_path = []
for i in dirs:
if os.path.splitext(i)[1] == ".png": # 已经转换过png了
img_path.append(i)
img_path = [folder + "//" + i for i in img_path]
# 这里就是真正的儿子路径了,也就是每个图片的完整路径
# 开始处理
features1 = np.zeros([len(img_path), 25088]) # 弄好每个图片的数组框架
for i in range(len(img_path)):
feature_i = modelProcess(img_path[i], model_vgg) # 这就运用上面函数进行每张图片处理
print('preprocessed:', img_path[i])
features1[i] = feature_i
if j == 0: # 这边判断的目的是把5个分类的图片数组全部加到一起
X = features1 # 第一次循环,那就只有一个,注意j在最上面
else:
X = np.concatenate((X, features1), axis=0)
# 之后的每次循环把上一个种类的图片数组和这个种类的所有图片数组加到一起
return X # 最后就全部加到一起了,此时X是5个分类都在了,也就是全部训练集
path = 'D:/桌面/全形态雷伊/train_data' # 这个就是训练集的爷爷路径
test_path = 'D:/桌面/全形态雷伊/test_data' # 这个就是测试集的爷爷路径
transform_format(path)
transform_format(test_path)
X = read_data(path) # 读取训练数据
test_X = read_data(test_path) # 读取测试数据
print(X.shape)
print(test_X.shape)
#PCA训练集降维
from sklearn.preprocessing import StandardScaler
stds = StandardScaler()
X_norm = stds.fit_transform(X) # 数据标准化
#PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=200) # 降到200维
X_pca = pca.fit_transform(X_norm)
#判定降维后能否保留大部分特征的得分
var_ratio = pca.explained_variance_ratio_
print(np.sum(var_ratio))
print(X_pca.shape,X.shape) # 前后维度
#PCA测试集降维
X_norm_test = stds.transform(test_X)
X_pca_test = pca.transform(X_norm_test)
var_ratio = pca.explained_variance_ratio_
print(np.sum(var_ratio))
print(X_pca_test.shape,test_X.shape)
# meanshift训练集预测
from sklearn.cluster import MeanShift, estimate_bandwidth
# 自动获取meanshift带宽
bw = estimate_bandwidth(X_pca,n_samples=140)
print(bw)
# 设置模型
cnn_pca_ms = MeanShift(bandwidth=bw)
cnn_pca_ms.fit(X_pca)
# 预测
y_predict_pca_ms = cnn_pca_ms.predict(X_pca)
print(y_predict_pca_ms)
from collections import Counter
print(Counter(y_predict_pca_ms)) # 预测结果统计
#11
# meanshift测试集预测
y_predict_pca_ms_test = cnn_pca_ms.predict(X_pca_test)
print(y_predict_pca_ms_test)
# DBSCAN训练集预测
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=200, min_samples=4) # 超参数设置
label_pred = dbscan.fit_predict(X_pca)
print(label_pred)
from collections import Counter
print(Counter(label_pred)) # 预测结果统计
#5
# DBSCAN_train
# 画出预测图及标签 要对中文进行设置 不然显示不出中文
font2 = {'family': 'SimHei', 'weight': 'normal', 'size': 20}
mlp.rcParams['font.family'] = 'SimHei'
mlp.rcParams['axes.unicode_minus'] = False
train_path = 'D:/桌面/全形态雷伊/train_data/train_data'
folders = os.listdir(train_path) # 传入训练集
num = len(folders)
fig = plt.figure(figsize=(10, 10 * (int(num / 9) + int(num % 9 / 3) + 1 * (num % 9 % 3))))
# 这一步的意思是,根据前期测试,10*10大小的图片放3*3,9张图片最佳
# 那就可以根据所有测试图片的数量来确定最后画出的图的大小
for j in range(num):
# 这些步骤其实都和前面差不多,就是对图片进行预处理,这样能够输入进网络
img_name = train_path + '/' + folders[j]
img_ori = load_img(img_name, target_size=(250, 250))
plt.subplot(int(num / 3) + 1, 3, j + 1)
# subplot就是一张大图里面有多少小图的意思,也是根据总共测试图的数量来确定的
plt.imshow(img_ori) # 展示
if label_pred[j]==0:
plt.title('预测为:雷伊') # 每个预测图题目写上预测结果
else:
plt.title('预测为:其余形态雷伊')
plt.subplots_adjust(top=0.99, bottom=0.003, left=0.1, right=0.9, wspace=0.18, hspace=0.15)
# 控制每个子图间距
plt.savefig('D://桌面//dbscan_train.png') # 保存咯,路径自己改下
#ms_train
# 画出预测图及标签 要对中文进行设置 不然显示不出中文
font2 = {'family': 'SimHei', 'weight': 'normal', 'size': 20}
mlp.rcParams['font.family'] = 'SimHei'
mlp.rcParams['axes.unicode_minus'] = False
train_path = 'D:/桌面/全形态雷伊/train_data/train_data'
folders = os.listdir(train_path) # 传入训练集
num = len(folders)
fig = plt.figure(figsize=(10, 10 * (int(num / 9) + int(num % 9 / 3) + 1 * (num % 9 % 3))))
# 这一步的意思是,根据前期测试,10*10大小的图片放3*3,9张图片最佳
# 那就可以根据所有测试图片的数量来确定最后画出的图的大小
for j in range(num):
# 这些步骤其实都和前面差不多,就是对图片进行预处理,这样能够输入进网络
img_name = train_path + '/' + folders[j]
img_ori = load_img(img_name, target_size=(250, 250))
plt.subplot(int(num / 3) + 1, 3, j + 1)
# subplot就是一张大图里面有多少小图的意思,也是根据总共测试图的数量来确定的
plt.imshow(img_ori) # 展示
if y_predict_pca_ms[j]==0:
plt.title('预测为:雷伊') # 每个预测图题目写上预测结果
else:
plt.title('预测为:其余形态雷伊')
plt.subplots_adjust(top=0.99, bottom=0.003, left=0.1, right=0.9, wspace=0.18, hspace=0.15)
# 控制每个子图间距
plt.savefig('D://桌面//ms_train.png') # 保存咯,路径自己改下
#ms_test
# 画出预测图及标签 要对中文进行设置 不然显示不出中文
font2 = {'family': 'SimHei', 'weight': 'normal', 'size': 20}
mlp.rcParams['font.family'] = 'SimHei'
mlp.rcParams['axes.unicode_minus'] = False
train_path = 'D:/桌面/全形态雷伊/test_data/test_data'
folders = os.listdir(train_path) # 传入测试集
num = len(folders)
fig = plt.figure(figsize=(10, 10 * (int(num / 9) + 1)))
# 这一步的意思是,根据前期测试,10*10大小的图片放3*3,9张图片最佳
# 那就可以根据所有测试图片的数量来确定最后画出的图的大小
for j in range(num):
# 这些步骤其实都和前面差不多,就是对图片进行预处理,这样能够输入进网络
img_name = train_path + '/' + folders[j]
img_ori = load_img(img_name, target_size=(250, 250))
plt.subplot(int(num / 3) + 1, 3, j + 1)
# subplot就是一张大图里面有多少小图的意思,也是根据总共测试图的数量来确定的
plt.imshow(img_ori) # 展示
if y_predict_pca_ms_test[j]==0:
plt.title('预测为:雷伊') # 每个预测图题目写上预测结果
else:
plt.title('预测为:其余形态雷伊')
plt.savefig('D://桌面//ms_test.png') # 保存咯,路径自己改下
作者:ABin_203