PyTorch学习笔记(5)Dataloader与Dataset(2)
人民币识别
split_dataset
作者:qq_33357094
import os
import random
import shutil
def makedir(new_dir):
if not os.path.exists(new_dir):
os.makedirs(new_dir)
if __name__ == '__main__':
random.seed(1)
dataset_dir = os.path.join("data", "RMB_data")
split_dir = os.path.join("data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
test_dir = os.path.join(split_dir, "test")
# 训练集 和 测试集 比例 8:1:1
train_pct = 0.8
valid_pct = 0.1
test_pct = 0.1
for root, dirs, files in os.walk(dataset_dir):
for sub_dir in dirs:
imgs = os.listdir(os.path.join(root, sub_dir))
imgs = list(filter(lambda x: x.endswith('.jpg'), imgs))
random.shuffle(imgs)
img_count = len(imgs)
train_point = int(img_count * train_pct)
valid_point = int(img_count * (train_pct + valid_pct))
for i in range(img_count):
if i < train_point:
out_dir = os.path.join(train_dir, sub_dir)
elif i < valid_point:
out_dir = os.path.join(valid_dir, sub_dir)
else:
out_dir = os.path.join(test_dir, sub_dir)
makedir(out_dir)
target_path = os.path.join(out_dir, imgs[i])
src_path = os.path.join(dataset_dir, sub_dir, imgs[i])
shutil.copy(src_path, target_path)
print('Class:{}, train:{}, valid:{}, test:{}'.format(sub_dir, train_point, valid_point-train_point,
train_lenet
import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed() # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
# 读取硬盘中的数据
split_dir = os.path.join("data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
# 数据标准化的均值 和标准差
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
# 对数据进行预处理
# Compose 将一系列transforms方法进行有序的组合
# 将依次对图像进行操作
train_transform = transforms.Compose([
# resize 缩放
transforms.Resize((32, 32)),
# 裁剪
transforms.RandomCrop(32, padding=4),
# ToTensor 把图像转成张量数据 归一化的操作 把0-255归一化为0-1
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
# Dataset必须由用户自己构建 数据的路径 和 数据预处理
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
# 初始化卷积神经网络
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
# 以epoch 为主周期 进行循环
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
# 反向传播 获取梯度
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
# 更新权值
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss_val/valid_loader.__len__())
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val, correct_val / total_val))
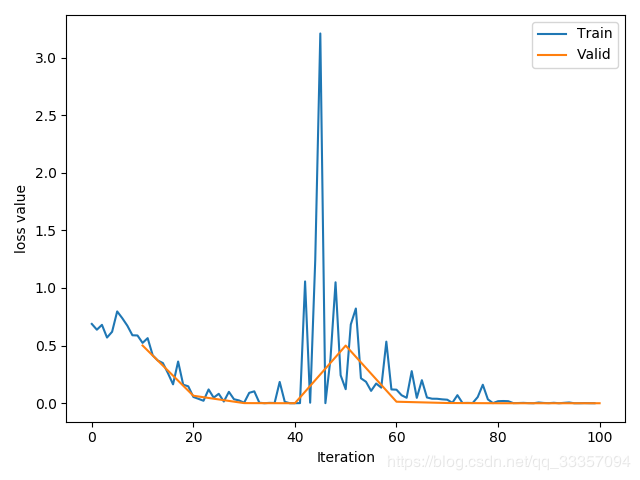
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
# ============================ inference ============================
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
test_dir = os.path.join(BASE_DIR, "test_data")
test_data = RMBDataset(data_dir=test_dir, transform=valid_transform)
valid_loader = DataLoader(dataset=test_data, batch_size=1)
for i, data in enumerate(valid_loader):
# forward
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
rmb = 1 if predicted.numpy()[0] == 0 else 100
print("模型获得{}元".format(rmb))
训练结果
Training:Epoch[000/010] Iteration[010/010] Loss: 0.6582 Acc:56.88%
Valid: Epoch[000/010] Iteration[002/002] Loss: 1.0019 Acc:70.00%
Training:Epoch[001/010] Iteration[010/010] Loss: 0.3317 Acc:89.38%
Valid: Epoch[001/010] Iteration[002/002] Loss: 0.1299 Acc:100.00%
Training:Epoch[002/010] Iteration[010/010] Loss: 0.0537 Acc:99.38%
Valid: Epoch[002/010] Iteration[002/002] Loss: 0.0022 Acc:100.00%
Training:Epoch[003/010] Iteration[010/010] Loss: 0.0406 Acc:97.50%
Valid: Epoch[003/010] Iteration[002/002] Loss: 0.0002 Acc:100.00%
Training:Epoch[004/010] Iteration[010/010] Loss: 0.7189 Acc:88.12%
Valid: Epoch[004/010] Iteration[002/002] Loss: 1.0007 Acc:95.00%
Training:Epoch[005/010] Iteration[010/010] Loss: 0.3098 Acc:87.50%
Valid: Epoch[005/010] Iteration[002/002] Loss: 0.0263 Acc:100.00%
Training:Epoch[006/010] Iteration[010/010] Loss: 0.0921 Acc:96.88%
Valid: Epoch[006/010] Iteration[002/002] Loss: 0.0040 Acc:100.00%
Training:Epoch[007/010] Iteration[010/010] Loss: 0.0360 Acc:98.75%
Valid: Epoch[007/010] Iteration[002/002] Loss: 0.0000 Acc:100.00%
Training:Epoch[008/010] Iteration[010/010] Loss: 0.0071 Acc:100.00%
Valid: Epoch[008/010] Iteration[002/002] Loss: 0.0000 Acc:100.00%
Training:Epoch[009/010] Iteration[010/010] Loss: 0.0016 Acc:100.00%
Valid: Epoch[009/010] Iteration[002/002] Loss: 0.0000 Acc:100.00%
作者:qq_33357094