大数据面试复习(一)之HDFS概况
目录
HDFS特点概况
HDFS核心组件的职责
HDFS数据流程
HDFS写数据流程
HDFS读数据流程
HDFS高可用
HDFS小文件问题
HDFS特点概况特点:
廉价 流数据读取(流数据是一组顺序、大量、快速、连续到达的数据序列) 大数据集 跨平台 高延迟:换言之不适合低延迟平台 一次写入,多次读取的文件模型 无法高效存储大量小文件。(每个文件都需要一个元数据) 不支持多用户写入及任意修改文件。 HDFS核心组件的职责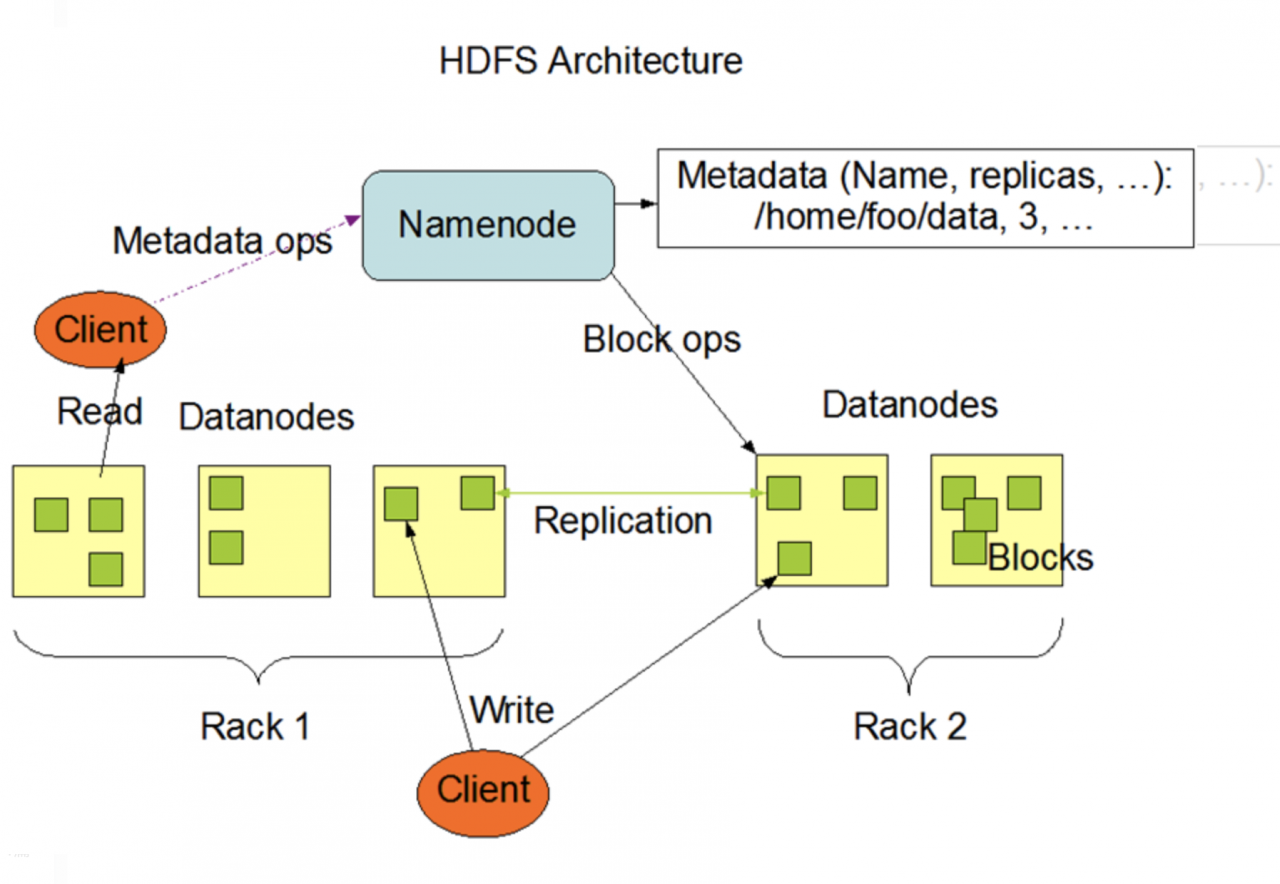

总的步骤简单说分为8步:
客户端向NN申请写数据 NN响应 客户端请求写数据DN路径 NN发挥DN路径 客户端请求与DN建立传输通道 DN应答 传输数据 传输完成。注意:
在hadoop2.x版本中block的默认大小是128M,老版本中是64M。 HDFS的块比磁盘的块大,目的是为了最小化寻址开销。减小磁盘寻址占比,提高效率。 块的大小,副本数量都可通过参数配置改变。 客户端完成将数据分成block的工作。 HDFS读数据流程

读数据类似写数据。
HDFS高可用 HA准备两个NN,一个active,一个standby(备用NN会同步active NN的状态,作为备用),数据同步。 当Active NN执行了修改命名空间的操作时,它会定期将执行的操作记录在editlog中,并写入JNS(JournalNodes)的多数节点中。而Standby NN会一直监听JNS上editlog的变化,如果发现editlog有改动,Standby Namenode就会读取editlog并与当前的命名空间合并。 发生故障时,Standby节点会保证已经从JNS上读取了所有editlog并与命名空间合并,然后才会从Standby状态切换为Active状态。 Datanode会同时向这两个Namenode发送心跳以及块汇报信息。这样就实现了Active NN 和standby NN 的元数据就完全一致,一旦发生故障,就可以马上切换,也就是热备。 HDFS小文件问题小文件:明显小于blocksize的文件 ,可能站80%
为什么会有小文件:HDFS上每个文件都要在NN上建立一个索引,这个索引的大小约为150byte,这样当小文件比较多的时候,就会产生很多的索引文件,一方面会大量占用namenode的内存空间,另一方面就是索引文件过大是的索引速度变慢。所以要想办法去规避更多小文件。
解决思路
1)Hadoop Archive:是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样就减少了NN的内存使用。
2)Sequence file: sequence file由一系列的二进制key/value组成,如果key为文件名,value为文件内容,则可以将大批小文件合并成一个大文件。
3)CombineFileInputFormat:CombineFileInputFormat是一种新的inputformat,用于将多个文件合并成一个单独的split,另外,它会考虑数据的存储位置。
4)开启JVM重用:对于大量小文件Job,可以开启JVM重用会减少45%运行时间。
JVM重用理解:对一个job开启jvm重用,这样多个task可以只用一个jvm解决,不需要频繁开启jvm。
如果task属于不同的job,那么JVM重用机制无效,不同job的task需要不同的JVM来运行。
具体设置:mapreduce.job.jvm.numtasks值在10-20之间。
作者:StephenYYYou
相关文章
Serafina
2020-03-27
Jayne
2020-12-19
Bliss
2023-07-21
Lillian
2023-07-21
Tertia
2023-07-21
Olive
2023-07-21
Rabia
2023-07-21
Linnea
2023-07-21
Angie
2023-07-21
Jennifer
2023-07-21
Jayne
2023-07-21
Maleah
2023-07-21
Bella
2023-07-21
Coral
2023-07-21
Talia
2023-07-21
Valora
2023-07-21
Summer
2023-07-21