【Spark编程基础(1)】大数据技术概述
文章目录大数据时代大数据概念大数据的影响大数据关键技术大数据计算模式代表性大数据技术
大数据时代
运营式系统阶段(沃尔玛商超管理系统)、用户原创内容阶段(自媒体)、感知式系统阶段(传感器、摄像头、RFID 大数据概念
大数据摩尔定律(每年50%增长,两年一倍) 2020年总数据量将达到35ZB 多样化(Variety)
数据类型繁多,其中结构化数据占10%,非结构化NoSQL占90% 快速化(Velocity)
1秒定律:数据从生成到决策1秒内响应,才具备商业价值。 价值密度低(Value)
有价值数据占比很少、单点价值高 大数据的影响 科学研究
四种研究范式:实验->理论->计算->数据
以计算为中心研究,知道具体的问题;以数据为中心的时代,从大量的数据中发现问题,解决问题。 思维层面
全样而非抽样、效率而非精确、相关而非因果 大数据关键技术 数据采集
ETL工具、爬虫工具 数据存储与管理
文件系统、数据库系统(分布式存储)
GFS->HDFS
非关系型数据库(NoSQL数据库) 数据处理和分析
高效计算(分布式处理)
MapReduce->Spark 数据隐私和安全
隐私数据、数据安全 Hadoop
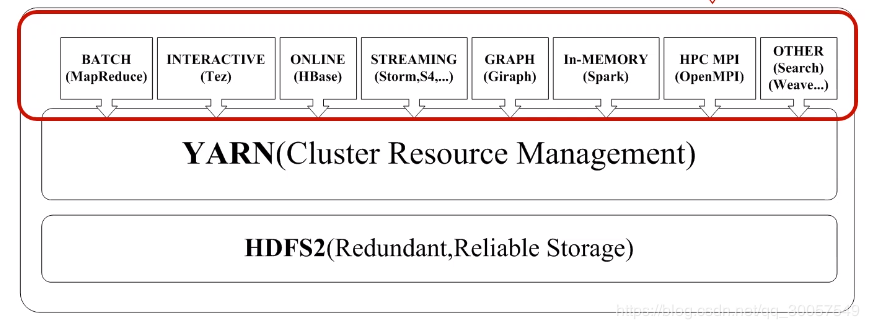
核心是HDFS和MapReduce 大数据计算模式
针对大规模数据批量处理;无法实时响应
工具:MapReduce(分钟级)、Spark(内存计算->准实时性、秒级响应) 流计算
针对流数据的实时计算,如大型应用系统的故障分析检测
工具:Storm(毫秒级响应)、S4、Flume、DStream 图计算
针对社交网络、路径计算等
工具:Pregel、Hama、PowerGraph 查询分析计算
针对数据仓库的应用,查询销量趋势
工具:Hadoop生态圈的Hive、Dremel 代表性大数据技术 Hadoop(05~15时期大数据的代名词)
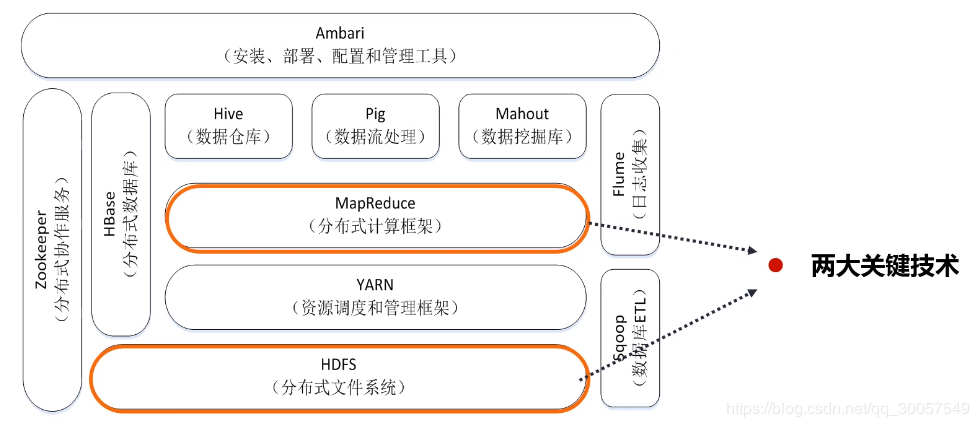
HDFS:底层,海量分布式文件存储
YARN:为MapReduce提供资源调度和管理服务,使得其他框架共享底层存储HDFS。
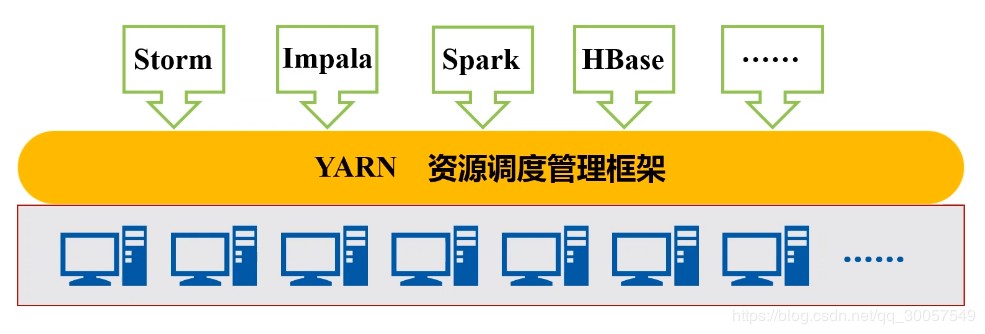
MapReduce:计算任务
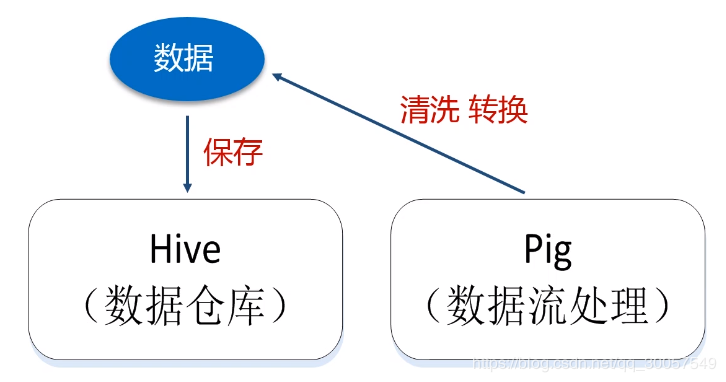
Hive:底层为HDFS的数据仓库,将SQL语句自动转换为对HDFS查询分析的编程接口。(数据库只能保存某一时刻状态数据,数据仓库保存时间快照上的信息)
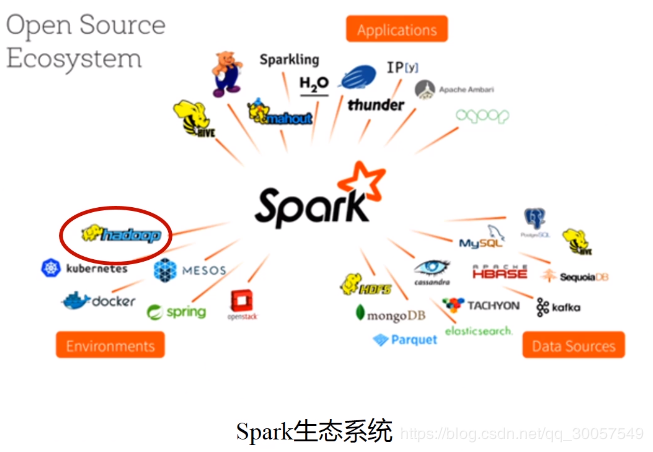
Spark架构图

Spark生态系统

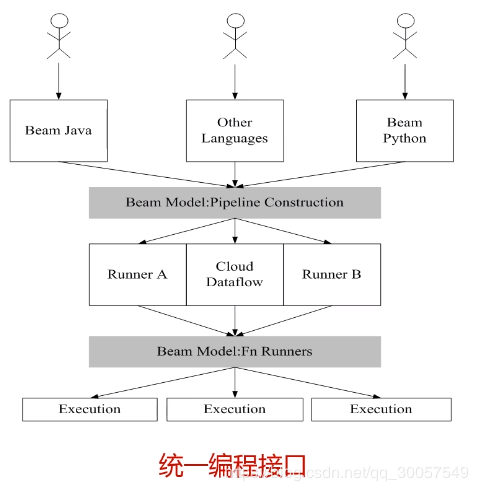
 Beam
Beam
作者:LotusQ
第一次信息化浪潮(80年代):PC普及、自动化处理
第二次信息化浪潮(95年):互联网普及
第三次信息化浪潮(2010,2013中国兴起):云计算、大数据、物联网
为什么大数据时代会到来?
技术支撑:存储设备、CPU计算能力、网络带宽 数据产生方式的变革:运营式系统阶段(沃尔玛商超管理系统)、用户原创内容阶段(自媒体)、感知式系统阶段(传感器、摄像头、RFID 大数据概念
4V特性
大量化(Volume)大数据摩尔定律(每年50%增长,两年一倍) 2020年总数据量将达到35ZB 多样化(Variety)
数据类型繁多,其中结构化数据占10%,非结构化NoSQL占90% 快速化(Velocity)
1秒定律:数据从生成到决策1秒内响应,才具备商业价值。 价值密度低(Value)
有价值数据占比很少、单点价值高 大数据的影响 科学研究
四种研究范式:实验->理论->计算->数据
以计算为中心研究,知道具体的问题;以数据为中心的时代,从大量的数据中发现问题,解决问题。 思维层面
全样而非抽样、效率而非精确、相关而非因果 大数据关键技术 数据采集
ETL工具、爬虫工具 数据存储与管理
文件系统、数据库系统(分布式存储)
GFS->HDFS
非关系型数据库(NoSQL数据库) 数据处理和分析
高效计算(分布式处理)
MapReduce->Spark 数据隐私和安全
隐私数据、数据安全 Hadoop
核心是HDFS和MapReduce 大数据计算模式
每一种技术都有局限性
批处理计算针对大规模数据批量处理;无法实时响应
工具:MapReduce(分钟级)、Spark(内存计算->准实时性、秒级响应) 流计算
针对流数据的实时计算,如大型应用系统的故障分析检测
工具:Storm(毫秒级响应)、S4、Flume、DStream 图计算
针对社交网络、路径计算等
工具:Pregel、Hama、PowerGraph 查询分析计算
针对数据仓库的应用,查询销量趋势
工具:Hadoop生态圈的Hive、Dremel 代表性大数据技术 Hadoop(05~15时期大数据的代名词)
HDFS:底层,海量分布式文件存储
YARN:为MapReduce提供资源调度和管理服务,使得其他框架共享底层存储HDFS。
MapReduce:计算任务
Hive:底层为HDFS的数据仓库,将SQL语句自动转换为对HDFS查询分析的编程接口。(数据库只能保存某一时刻状态数据,数据仓库保存时间快照上的信息)
OLAP分析:用数据仓库进行多维分析,如商品销量走势和变化原因
Pig:Pig Latin语言≈SQL语句,对数据清洗转换。
Mahout:实现常用数据挖掘算法,分类、聚类,回归等。其实现已经全面转向了Spark,不再使用MapReduce。
HBase:HDFS基础上的分布式数据库。
ZooKeeper:分布式协作服务。
Flume:日志采集分析。
Sqoop:数据库ETL,关系型数据库HDFS之间互相转换,Hadoop系统组件之间的互通。
MapReduce
核心是Map函数和Reduce函数,屏蔽底层分布式并行编程细节。采用“分而治之”策略。
Spark架构图
Spark生态系统
Hadoop——MapReduce缺点:表达能力有限、磁盘IO开销较大、延迟高
Spark优点:多种数据集操作类型、编程模型更加灵活(表达能力更强)、提供了内存计算、基于DAG的任务调度执行机制
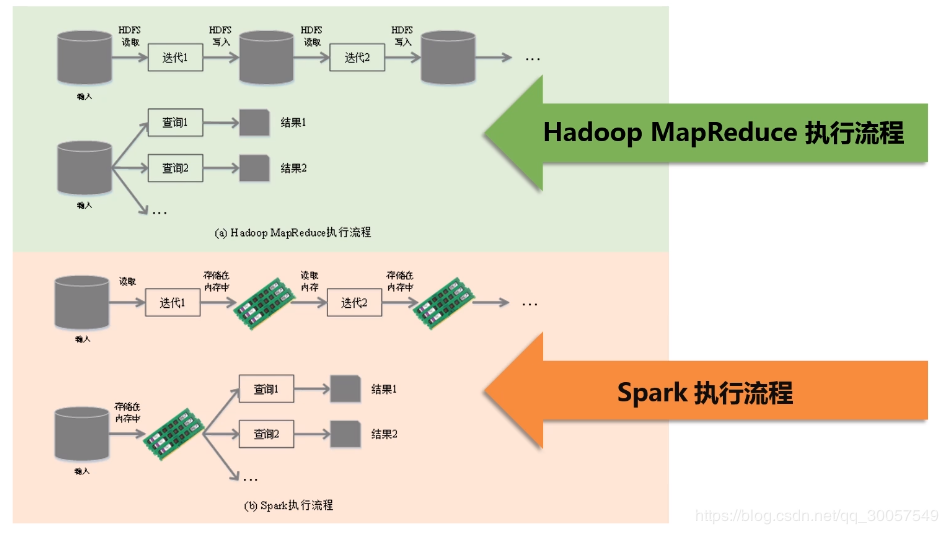
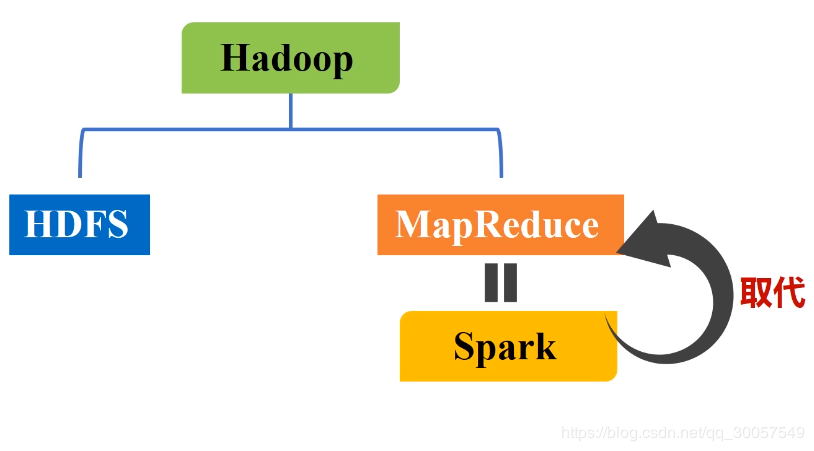
Spark会取代Hadoop么?
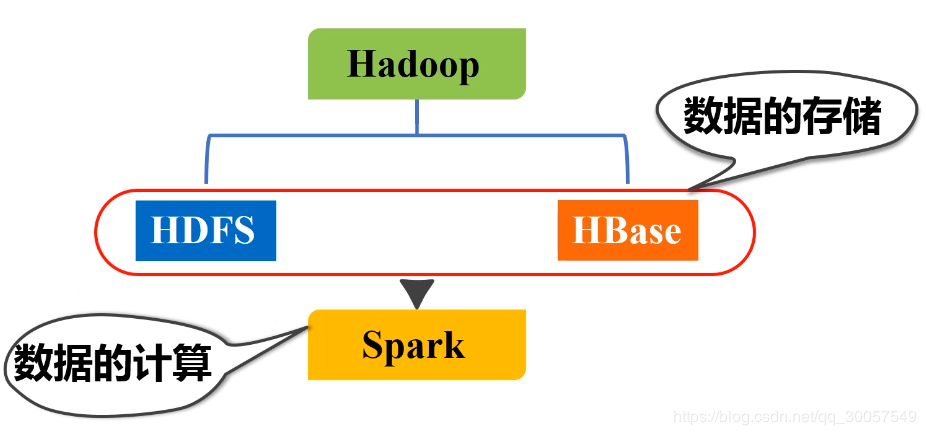
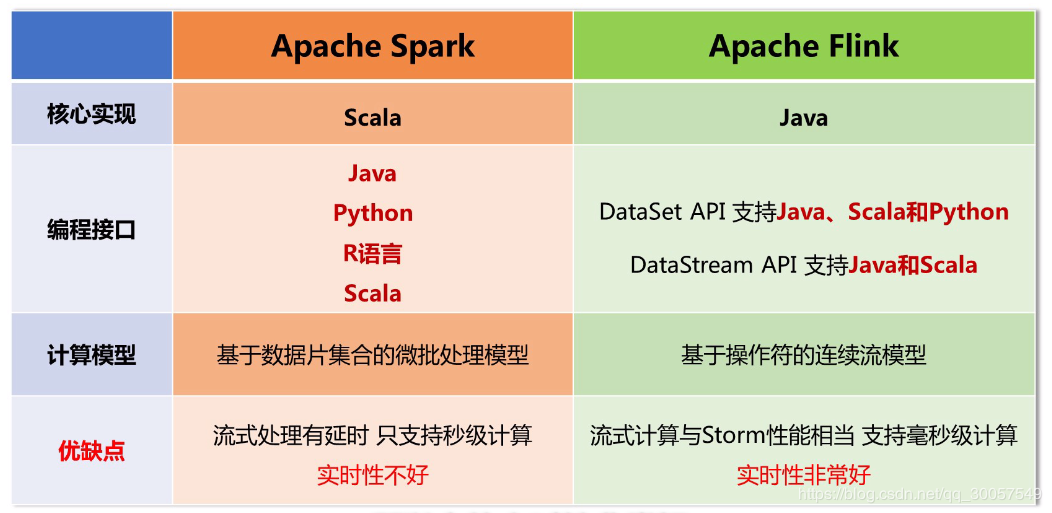
开发Spark程序用什么编程语言?
首选Scala,最高效,支持交互式执行。Java代码太繁琐,Python语言并发性能不好。
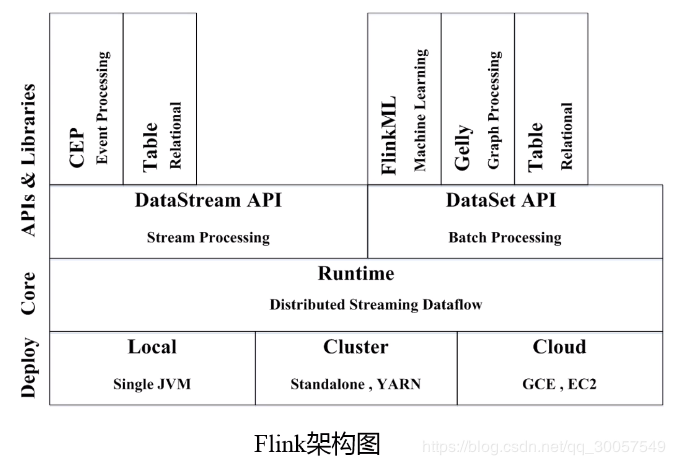
Flink
Beam
作者:LotusQ
相关文章
Petra
2020-05-22
Rachel
2023-07-20
Psyche
2023-07-20
Winola
2023-07-20
Gella
2023-07-20
Grizelda
2023-07-20
Janna
2023-07-20
Ophelia
2023-07-21
Crystal
2023-07-21
Laila
2023-07-21
Aine
2023-07-21
Bliss
2023-07-21
Lillian
2023-07-21
Tertia
2023-07-21
Olive
2023-07-21
Angie
2023-07-21
Nora
2023-07-24