大数据技术基础与应用
大数据时代

大数据是由结构化和非结构化数据组成
结构化类型数据:10%(存储在关系型数据库里面的结构化数据)
非结构化数据:90% (图形、图像、文本、视频…) 多样化:非结构化数据多样化 快速化:所有软件要求1秒级 价值密度低,商业价值高 二、 大数据的影响
 效率而非精确:之前是抽样,若精度不高则放到全样上误差会放大。而现在是全样分析,故误差不会改变太多。
相关而非因果
效率而非精确:之前是抽样,若精度不高则放到全样上误差会放大。而现在是全样分析,故误差不会改变太多。
相关而非因果
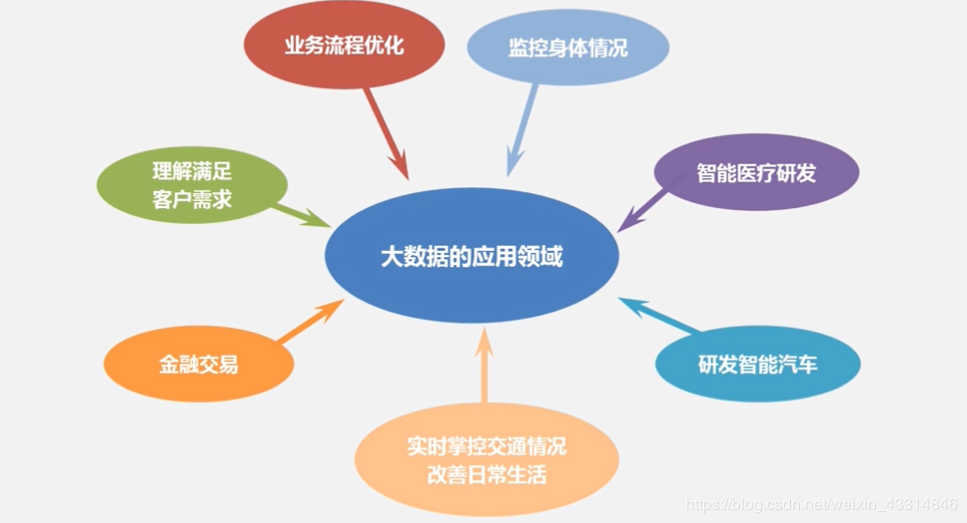
 大数据应用
大数据应用
 图计算:eg:Google Pregel
查询分析计算:有非常高的实时性
图计算:eg:Google Pregel
查询分析计算:有非常高的实时性
 不同的产品服务于不同的计算问题的
不同的产品服务于不同的计算问题的
作者:Lemon
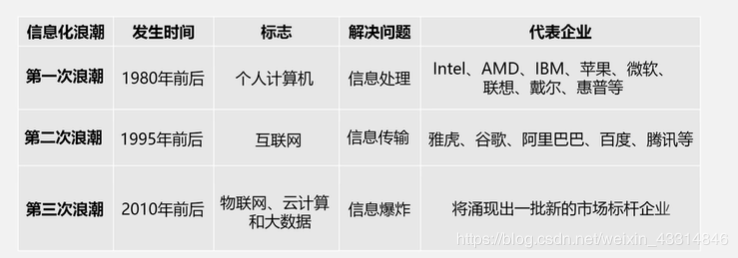
第三次信息化浪潮 :大数据+云计算+物联网
大数据时代:
一、 技术支撑
二、 数据产生方式的变革 (重要因素)
运营式系统阶段 -> 用户原创内容阶段-> 感知式系统阶段(物联网的兴起(重要因素):摄像头、传感器、气象温、湿度传感器都在时时刻刻在记录数据)
4V:大量化、多样化、快速化、价值密度低
数据量大:人类在最近两年产生的数据量相当于之前产生的全部数据量大数据是由结构化和非结构化数据组成
结构化类型数据:10%(存储在关系型数据库里面的结构化数据)
非结构化数据:90% (图形、图像、文本、视频…) 多样化:非结构化数据多样化 快速化:所有软件要求1秒级 价值密度低,商业价值高 二、 大数据的影响
科学研究的四种范式:
实验-> 理论->计算->数据
在思维方式方面:大数据完全颠覆了传统的思维方式
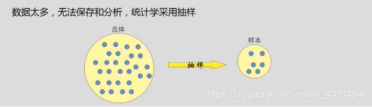
全样而非抽样:可存储数据内容增加
效率而非精确:之前是抽样,若精度不高则放到全样上误差会放大。而现在是全样分析,故误差不会改变太多。
相关而非因果
大数据应用
大数据技术的层次->两大核心技术(分布式存储+分布式处理 )
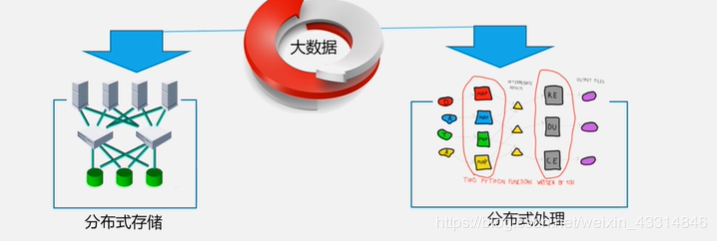
分布式存储:解决海量数据的存储问题
借助集群网络存储
分布式处理:解决海量数据的处理问题
借助集群网络处理
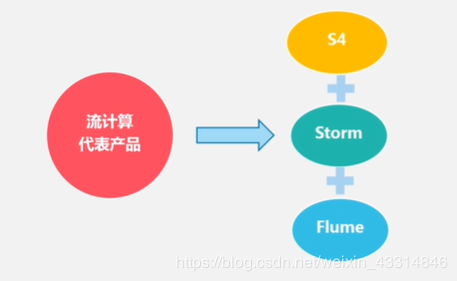
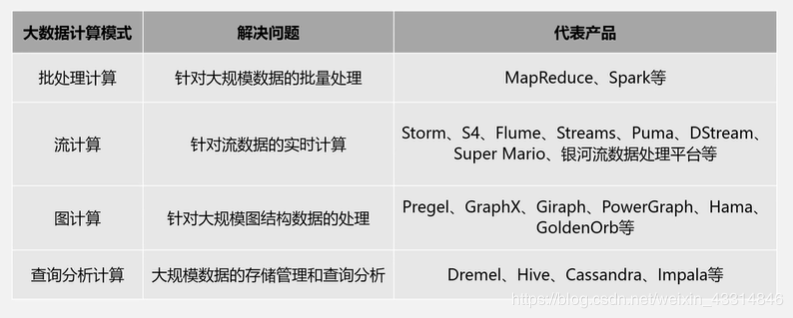
不同的大数据产品服务的方向是不同的:批处理、交互式计算、实时计算等。每个产品的计算领域是不同,故需要对计算模式进行区分。
图计算:eg:Google Pregel
查询分析计算:有非常高的实时性
不同的产品服务于不同的计算问题的
两大核心问题:① 解决了海量数据的分布式存储和分布式处理问题 ② 云计算代行特征:虚拟化+多用户
概念:云计算通过网络以服务的方式为用户提供非常廉价的IT资源。
优势:企业不需要自建IT基础设置,可以租用云端资源。
云计算的三种模式公有云、混合云、私有云
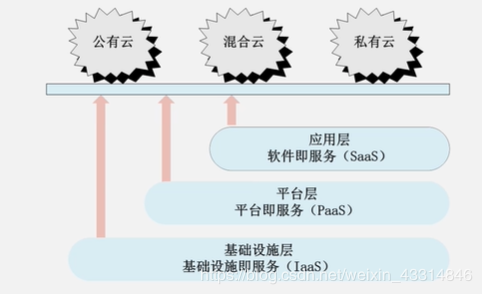
公有云:面对所有公众使用
私有云:给内部使用
混合云:公有云+私有云
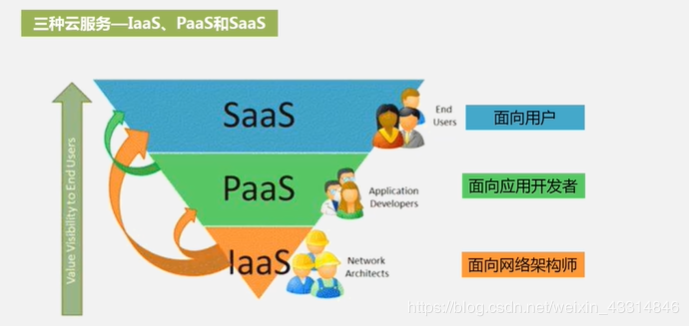
IaaS —— 基础设施即服务
将基础设施(计算资源和存储)作为服务出租。eg:购买环境,可以在该环境下安装各种软件,所有设施都提供好了
PaaS——平台即服务
在别人搭建的云平台开发环境下开发云计算产品,开发出来的产品也部署在别人的云平台开发环境下,可卖给其他人
SaaS——软件即服务
将软件作为一种服务卖给用户
云计算的关键技术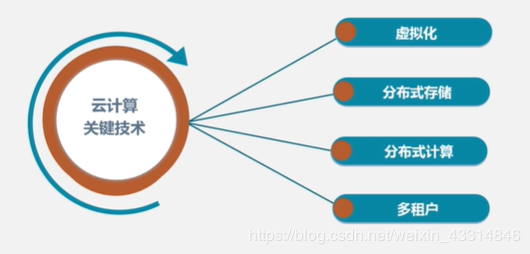


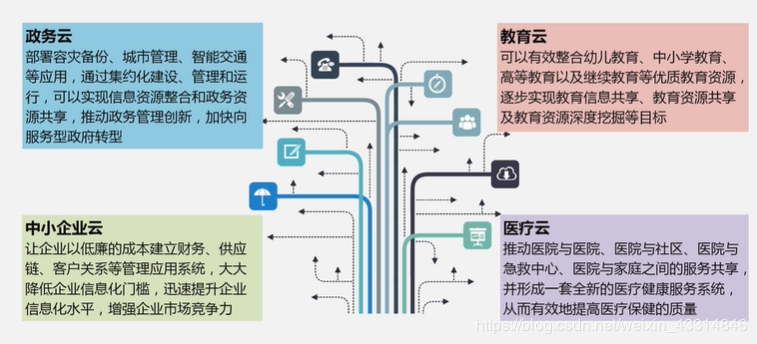
作者:Lemon