MDPI 爬取 'title_link', 'author_list', 'cited_by', 'viewed_by' Demo 数据保存至CSV文件
URL :
https://www.mdpi.com/search?sort=article_citedby&page_no=0&page_count=50&year_from=1996&year_to=2020&journal=cells&view=default
Page :
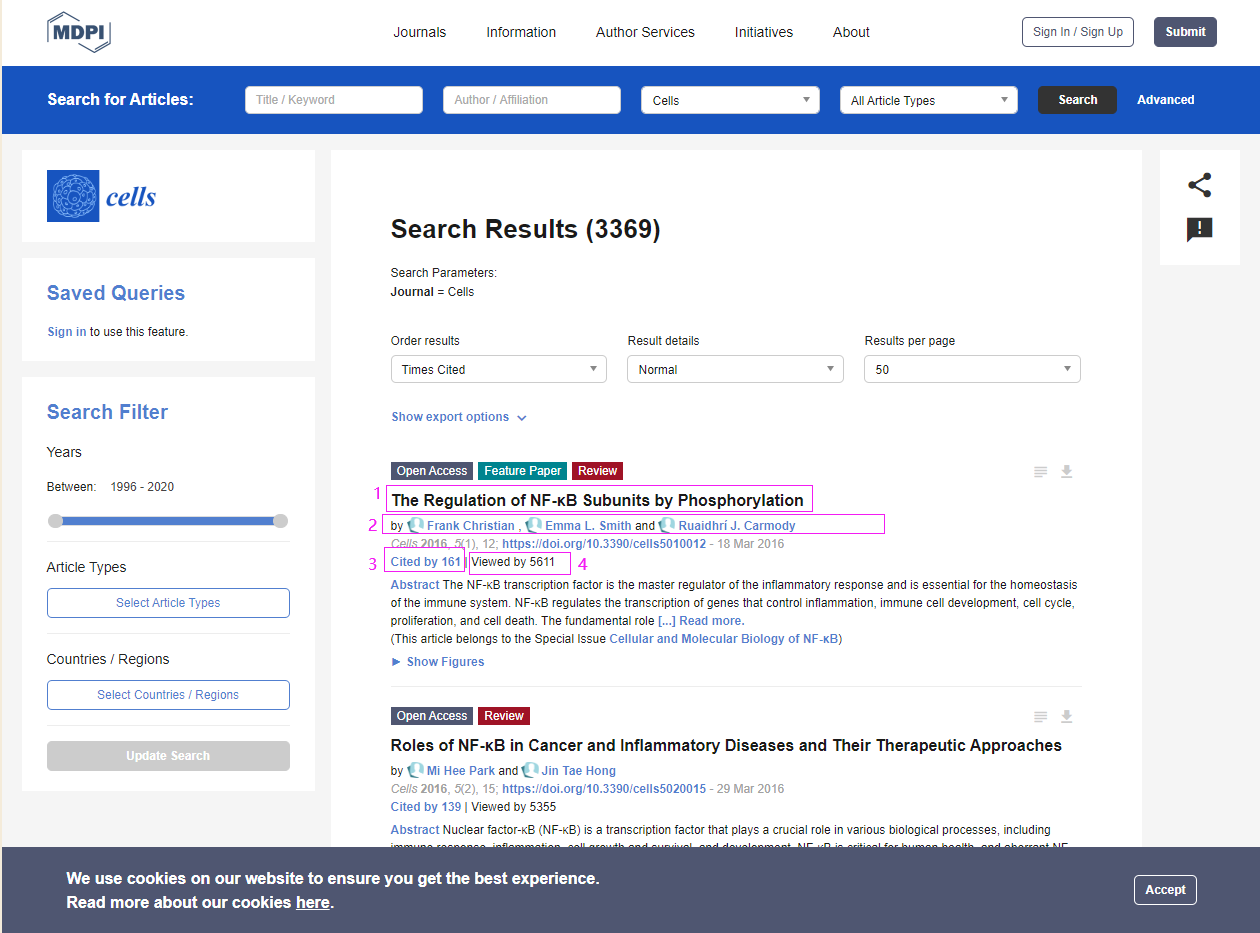
Demo :
# encoding: utf-8
"""
@author: lanxiaofang
@contact: fang@lanxf.cn
@software: PyCharm
@file: only_for_test.py
@time: 2020/5/2 17:19
"""
import random
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
class Cell(object):
def __init__(self):
self.header = {
'Accept': 'application / json, text / plain, * / *',
'Accept - Encoding': 'gzip, deflate, br',
"Accept - Language": "zh - CN, zh;q=0.9",
'Connection': "keep - alive",
'Referer': 'https://www.mdpi.com/search?sort=article_citedby&page_no=0&page_count=50&year_from=1996&year_to=2020&journal=cells&view=default',
'User-Agent': "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; de) Opera 11.01",
}
self.path = 'cell_info.csv'
with open(self.path, 'w', encoding='utf-8') as f: # 清空文件,如果该path文件打开的请记得关闭,否则会报错拒绝访问
f.truncate()
self.df = pd.DataFrame(columns=['title_link', 'author_list', 'cited_by', 'viewed_by'])
def save_data(self):
self.df.to_csv(self.path, index=False, mode='a', encoding='utf-8')
print('----------save success')
def get_data(self, start, end):
for i in range(start, end):
time.sleep(random.uniform(1, 5))
url = 'https://www.mdpi.com/search?sort=article_citedby&page_no={}&page_count=50&year_from=1996&year_to=2020&journal=cells&view=default'.format(i)
html = requests.get(url, headers=self.header)
html.encoding = 'utf-8'
soups = BeautifulSoup(html.text, 'html.parser')
try:
article_content = soups.find_all('div', class_='article-content')
title_link = article_content[i].find_all('a', class_='title-link')[0].string
authors = article_content[i].select('div.authors span.inlineblock a')
author_list = []
for item in authors:
author_list.append(item.string)
cited = article_content[i].find_all('a')
cited_by = 0
for c in cited:
if 'Cited by' in c.contents[0]:
cited_by = int(c.contents[0][9:]) # [9:] 表示从第9位开始截取到最后
break
viewed_by = 0
for a in article_content[i]:
if 'Viewed by' in a:
viewed_by = int(a[13:])
print(i, '-cited_by-', cited_by, '-viewed_by-', viewed_by, '-title_link-', title_link, '-author_list-', author_list)
self.df = self.df.append(pd.DataFrame.from_dict({'title_link': title_link, 'author_list': author_list, 'cited_by': cited_by, 'viewed_by': viewed_by}, orient='index').T, ignore_index=True)
except Exception as e:
print('INFO *** ', e)
self.save_data()
cell = Cell()
cell.get_data(0, 10) # fill the number for page_no is 0 to another number
① 字符串内容从第i位开始截取到最后:str [i: ]
② 保存数据前先清空文件:f.truncate(8)会截取从文件开头到8字节大小的长度,为空或0size表示清空文件
仅供学习参考使用,性能方面未达最优
 懒笑翻
懒笑翻
 原创文章 151获赞 117访问量 58万+
关注
私信
展开阅读全文
原创文章 151获赞 117访问量 58万+
关注
私信
展开阅读全文
作者:懒笑翻
相关文章
Odessa
2020-11-28
Cybill
2020-10-23
Maha
2020-11-26
Xenia
2020-03-15
Damara
2020-08-12
Daphne
2020-05-13
Wenda
2020-04-16
Madeline
2023-07-20
Grizelda
2023-07-20
Qamar
2023-07-20
Rose
2023-07-20
Janna
2023-07-20
Ophelia
2023-07-21
Crystal
2023-07-21
Laila
2023-07-21
Aine
2023-07-21
Bliss
2023-07-21
Lillian
2023-07-21