将CSV文件中的每一列(除ID)分别做归一化处理的函数实现
在机器学习过程中,对数据的处理过程中,常常需要对数据进行归一化处理,下面介绍(0, 1)标准化的方式,简单的说,其功能就是将预处理的数据的数值范围按一定关系“压缩”到(0,1)的范围类。
通常(0, 1)标注化处理的公式为:
xnormalization=x−MinMax−Min{x}_{normalization}=\frac{x-Min}{Max-Min}
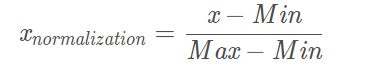
即将样本点的数值减去最小值,再除以样本点数值最大与最小的差,原理公式就是这么基础。
下面看看使用python语言来编程实现吧
import numpy as np
coman = pd.read_csv('xxxxx.csv')
# print(coman.info())
coman.replace([np.inf, -np.inf], np.nan,inplace=True)
coman = coman.fillna(0)
def regularit(df):
newDataFrame = pd.DataFrame(index=df.index)
columns = df.columns.tolist()
for c in columns:
if (c == 'ID'):
newDataFrame[c] = df[c].tolist()
else:
d = df[c]
MAX = d.max()
MIN = d.min()
newDataFrame[c] = ((d - MIN) / (MAX - MIN)).tolist()
return newDataFrame
data = regularit(coman)
所有巧合的是要么是上天注定要么是一个人偷偷的在努力。
个人微信公众号,专注于学习资源、笔记分享,欢迎关注。我们一起成长,一起学习。一直纯真着,善良着,温情地热爱生活,,如果觉得有点用的话,请不要吝啬你手中点赞的权力,谢谢我亲爱的读者朋友。

Life moves pretty fast. If you don’t stop and look around once in a while, you could miss it.
人生匆匆,若不偶尔停下来看看周围,便会错过许多风景。
作者:五角钱的程序员