Python批量将csv文件编码方式转换为UTF-8的实战记录
当我们用pandas是操作CSV文件的时候,常常会因为编码问题出现报错。
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader.read()
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._read_low_memory()
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._read_rows()
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._convert_column_data()
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._convert_tokens()
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._convert_with_dtype()
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._string_convert()
pandas_libs\parsers.pyx in pandas._libs.parsers._string_box_utf8()
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xca in position 0: invalid continuation byte
如果只是一两个文件,我们可以用系统自带记事本的方法进行解决:
1、右键csv文件,打开方式选择“记事本”打开;
2、ctrl+shift+s另存为,将编码方式由ansi给改为UTF-8,点击确定并替换原文件。

嫌麻烦的也可以在每次用pandas读取csv前加入以下代码。
import pandas as pd
filename='222.csv'
try:
df = pd.read_csv(filename, encoding='utf-8')
except BaseException:
df = pd.read_csv(filename, encoding='cp950')
df.to_csv(filename, encoding='utf-8', index=False)
如果很多类似的ASCII的CSV文件就会非常头痛,下面我们用Python编写一个程序,用来检测并批量转换csv文件的编码方式。
需要指出的是,这个程序并不完善,运行速度没有进行优化,并且仍然有部分文件未能转换成功,但足以应对日常的分析需要。经过尝试,有几种csv文件无法转换:
1、包含图片或者图表的csv文件
2、原先的csv文件内容就是乱码的
觉得有帮助,那请给这篇文章点个赞吧❤️
演示效果:
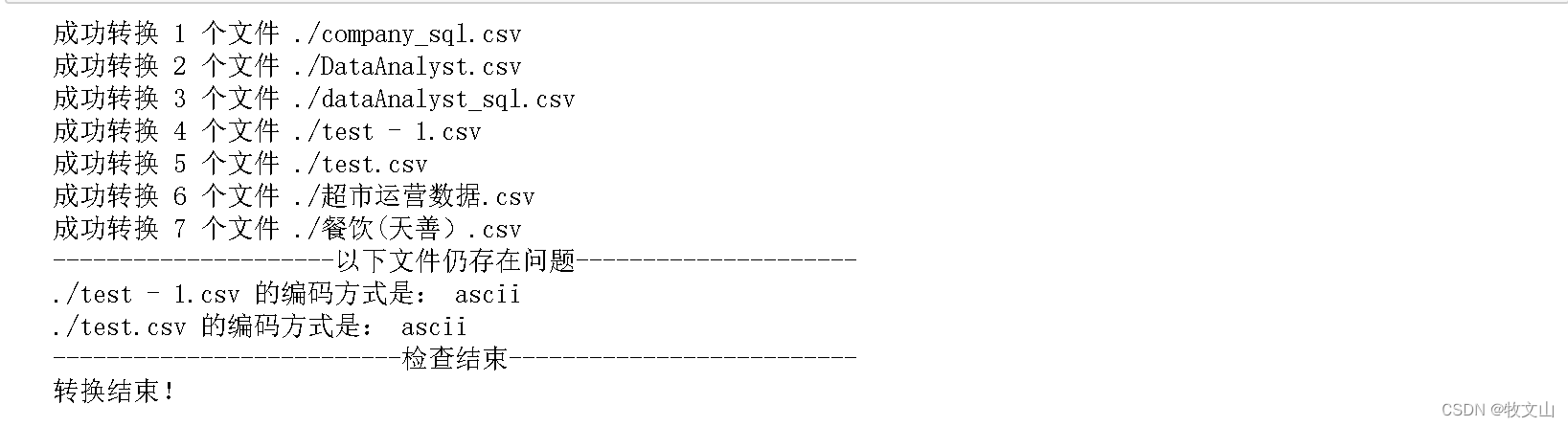
代码:
import os
from chardet.universaldetector import UniversalDetector
def get_filelist(path):
"""
获取路径下所有csv文件的路径列表
"""
Filelist = []
for home, dirs, files in os.walk(path):
for filename in files:
if ".csv" in filename:
Filelist.append(os.path.join(home, filename))
return Filelist
def read_file(file):
"""
逐个读取文件的内容
"""
with open(file, 'rb') as f:
return f.read()
def get_encode_info(file):
"""
逐个读取文件的编码方式
"""
with open(file, 'rb') as f:
detector = UniversalDetector()
for line in f.readlines():
detector.feed(line)
if detector.done:
break
detector.close()
return detector.result['encoding']
def convert_encode2utf8(file, original_encode, des_encode):
"""
将文件的编码方式转换为utf-8,并写入原先的文件中。
"""
file_content = read_file(file)
file_decode = file_content.decode(original_encode, 'ignore')
file_encode = file_decode.encode(des_encode)
with open(file, 'wb') as f:
f.write(file_encode)
def read_and_convert(path):
"""
读取文件并转换
"""
Filelist = get_filelist(path=path)
fileNum= 0
for filename in Filelist:
try:
file_content = read_file(filename)
encode_info = get_encode_info(filename)
if encode_info != 'utf-8':
fileNum +=1
convert_encode2utf8(filename, encode_info, 'utf-8')
print('成功转换 %s 个文件 %s '%(fileNum,filename))
except BaseException:
print(filename,'存在问题,请检查!')
def recheck_again(path):
"""
再次判断文件是否为utf-8
"""
print('---------------------以下文件仍存在问题---------------------')
Filelist = get_filelist(path)
for filename in Filelist:
encode_info_ch = get_encode_info(filename)
if encode_info_ch != 'utf-8':
print(filename,'的编码方式是:',encode_info_ch)
print('--------------------------检查结束--------------------------')
if __name__ == "__main__":
"""
输入文件路径
"""
path = './'
read_and_convert(path)
recheck_again(path)
print('转换结束!')
核心代码是:
def get_encode_info(file):
"""
逐个读取文件的编码方式
"""
with open(file, 'rb') as f:
detector = UniversalDetector()
for line in f.readlines():
detector.feed(line)
if detector.done:
break
detector.close()
return detector.result['encoding']
Filelist = get_filelist(path=path)
fileNum= 0
for filename in Filelist:
try:
file_content = read_file(filename)
encode_info = get_encode_info(filename)
if encode_info != 'utf-8':
fileNum +=1
convert_encode2utf8(filename, encode_info, 'utf-8')
print('成功转换 %s 个文件 %s '%(fileNum,filename))
except BaseException:
print(filename,'存在问题,请检查!')
总结
到此这篇关于Python批量将csv文件编码方式转换为UTF-8的文章就介绍到这了,更多相关Python批量转换csv文件编码内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!