Hadoop首选串行化系统——Avro简介及详细使用
本篇博客,Alice为大家介绍的是Hadoop中作为首选串行化系统的Avro。

Avro是Hadoop中的一个子项目,也是Apache中一个独立的项目,由Hadoop的创始人Doug Cutting(也是Lucene,Nutch等项目的创始人)开发,设计用于支持大批量数据交换的应用。Avro是一个基于二进制数据传输高性能的中间件。在Hadoop的其他项目中例如HBase(Ref)和Hive(Ref)的Client端与服务端的数据传输也采用了这个工具。Avro是一个数据序列化的系统。Avro 可以将数据结构或对象转化成便于存储或传输的格式。Avro设计之初就用来支持数据密集型应用,适合于远程或本地大规模数据的存储和交换。
特点 丰富的数据结构类型; 快速可压缩的二进制数据形式,对数据二进制序列化后可以节约数据存储空间和网络传输带宽; 存储持久数据的文件容器 可以实现远程过程调用RPC 简单的动态语言结合功能另外,avro支持跨编程语言实现(C, C++, C#,Java, Python, Ruby, PHP),类似于Thrift,但是avro的显著特征是:avro依赖于模式,动态加载相关数据的模式,Avro数据的读写操作很频繁,而这些操作使用的都是模式,这样就减少写入每个数据文件的开销,使得序列化快速而又轻巧。这种数据及其模式的自我描述方便了动态脚本语言的使用。当Avro数据存储到文件中时,它的模式也随之存储,这样任何程序都可以对文件进行处理。如果读取数据时使用的模式与写入数据时使用的模式不同,也很容易解决,因为读取和写入的模式都是已知的。
Avro数据类型和模式Avro定义了少量的基本数据类型,通过编写模式的方式,它们可被用于构建应用特定的数据结构。考虑到互操作性,实现必须支持所有的Avro类型。
Avro基本类型| 类型 | 描述 | 模式示例 |
|---|---|---|
| null | 空值 | “null” |
| boolean | 二进制值 | “boolean” |
| int | 32位带符号整数 | “int” |
| long | 64位带符号整数 | “long” |
| float | 单精度(32位)IEEE754 浮点数 | “float” |
| double | 双精度(64位)IEEE754 浮点数 | “double” |
| bytes | 8位无符号字节序列 | “bytes” |
| string | Unicode字符序列 | “string” |


图中表示的是Avro本地序列化和反序列化的实例,它将用户定义的模式和具体的数据编码成二进制序列存储在对象容器文件中,例如用户定义了包含学号、姓名、院系和电话的学生模式,而Avro对其进行编码后存储在student.db文件中,其中存储数据的模式放在文件头的元数据中,这样读取的模式即使与写入的模式不同,也可以迅速地读出数据。假如另一个程序需要获取学生的姓名和电话,只需要定义包含姓名和电话的学生模式,然后用此模式去读取容器文件中的数据即可。
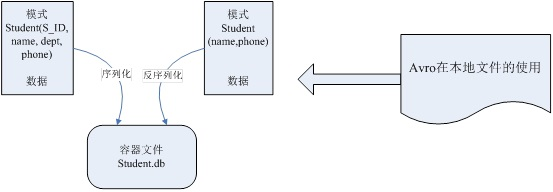
Avro数据序列化/反序列化一共有两种方式,分为使用编译和非编译两种情况。
方法1 使用编译的方式这种方式是比较常见的,即根据Avro模式生成JAVA代码,然后根据JAVA API来进行数据操作。
从Apache官网上下载Avro的jar包

2. 定义模式(Schema)
在avro中,它是用Json格式来定义模式的。模式可以由基础类型(null, boolean, int, long, float, double, bytes, and string)和复合类型(record, enum, array, map, union, and fixed)的数据组成。这里定义了一个简单的模式User.avsc:
{
"namespace": "com.czxy.hdfs.avro",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "id", "type": "int"},
{"name": "salary", "type": "int"},
{"name": "age", "type": "int"},
{"name": "address", "type": "string"}
]
}
3、打开cmd,进入到该目录,执行命令生成User类
命令格式:java -jar avro-toolsjar包的路径 compile schema 生成的文件名 输出路径

执行完之后,在你设置的输出路径下会产生一个新的目录com/czxy/avro/hdfs,在该目录最后一层,会产生一个User.java的文件。

4、打开IDEA,创建一个Maven项目,在pom.xml中加入avro的依赖。
org.apache.avro
avro
1.9.2
junit
junit
4.13
org.junit.jupiter
junit-jupiter-api
RELEASE
compile
把生成的目录拷贝至项目src下。其中User.java里面生成的User类及其内部类的包名默认是user.avsc文件中的namespace的值。
/**
* 使用编译的方式,实现序列化avro文件
* @throws Exception
*/
@Test
void test01() throws Exception {
// 声明并初始化User对象
// 方式1
User user1 = new User();
user1.setName("zhangsan");
user1.setId(1);
user1.setSalary(1000);
user1.setAge(20);
user1.setAddress("beijing");
// 方式2 使用构造函数
User user2 = new User("wangwu", 2, 1000, 19, "guangzhou");
// 方式3 使用Build方式
User user3 = User.newBuilder()
.setName("lisi")
.setId(3)
.setAge(21)
.setSalary(2000)
.setAddress("shenzhen")
.build();
// avro文件存放目录
String path = "G:\\2020干货\\avro\\user.avro";
// 创建write对象[创建一个写入器]
DatumWriter userDatumWriter = new SpecificDatumWriter(User.class);
// 写入文件[创建一个数据文件写入器,对写入器进行包装]
DataFileWriter dataFileWriter = new DataFileWriter(userDatumWriter);
// 串行化数据到磁盘[schema 就是我们写的模式文件经过转义后的内容]
dataFileWriter.create(user1.getSchema(), new File(path));
// 把生成的user对象写入到avro文件
dataFileWriter.append(user1);
dataFileWriter.append(user2);
dataFileWriter.append(user3);
// 关闭流
dataFileWriter.close();
}
查看产生的序列化存储文件user.avro
Objavro.schemaÈ{“type”:“record”,“name”:“User”,“namespace”:“com.czxy.hdfs.avro”,“fields”:[{“name”:“name”,“type”:“string”},{“name”:“id”,“type”:“int”},{“name”:“salary”,“type”:“int”},{“name”:“age”,“type”:“int”},{“name”:“address”,“type”:“string”}]} ûGú½1r ğj=C«òŠ6xzhangsanĞ(beijingwangwuĞ&guangzhoulisi *shenzhenûGú½1r ğj=C«òŠ6
反序列化/**
* 使用编译的方式,实现avro的反序列化
* @throws Exception
*/
@Test
void show02() throws Exception {
DatumReader reader = new SpecificDatumReader(User.class);
DataFileReader dataFileReader = new DataFileReader(new File("G:\\2020干货\\avro\\user.avro"),reader);
User user = null;
// 此处采用迭代器遍历
while (dataFileReader.hasNext()){
user= dataFileReader.next();
System.out.println(user);
}
// 关闭流
dataFileReader.close();
}
控制台打印结果:

无需通过Schema生成java代码,开发者需要在运行时指定Schema。
序列化 /**
* 直接使用schema文件进行写,不需要编译
*/
@Test
void show03() throws Exception {
// 指定定义的avsc文件[加载]
Schema schema = new Schema.Parser().parse(new File("G:\\2020干货\\avro\\User.avsc"));
// 创建GenericRecord,相当于 User1
GenericRecord user1 = new GenericData.Record(schema);
// 设置javabean的属性
user1.put("name","zhaoliu");
user1.put("id",1);
user1.put("salary",3000);
user1.put("age",18);
user1.put("address","shanghai");
GenericRecord user2 = new GenericData.Record(schema);
// 设置javabean的属性
user2.put("id",2);
user2.put("name","maqi");
user2.put("salary",3000);
user2.put("age",28);
user2.put("address","nanjing");
// 数据写入
DatumWriter datumWriter = new SpecificDatumWriter(schema);
DataFileWriter userfileWrite = new DataFileWriter(datumWriter);
userfileWrite.create(schema,new File("G:\\2020干货\\avro\\user2.avro"));
userfileWrite.append(user1);
userfileWrite.append(user2);
// 关闭流
userfileWrite.close();
}
生成的user2.avro文件
Objavro.schemaÈ{“type”:“record”,“name”:“User”,“namespace”:“com.czxy.hdfs.avro”,“fields”:[{“name”:“name”,“type”:“string”},{“name”:“id”,“type”:“int”},{“name”:“salary”,“type”:“int”},{“name”:“age”,“type”:“int”},{“name”:“address”,“type”:“string”}]} ySDz×iJhÍ sZåîLzhaoliuð.$shanghaimaqið.8nanjingySDz×iJhÍ sZåî
反序列化 /**
* 直接使用schema文件进行读,不需要编译
* 反串行化avro数据
* @throws Exception
*/
@Test
void show04() throws Exception{
// 指定定义的avsc文件
Schema schema = new Schema.Parser().parse(new File("G:\\2020干货\\avro\\User.avsc"));
DatumReader r1 = new SpecificDatumReader(schema);
DataFileReader r2 = new DataFileReader(new File("G:\\2020干货\\avro\\user2.avro"),r1);
// 创建GenericRecord,相当于 User1
GenericRecord user = null;
while (r2.hasNext()){
user = (GenericRecord) r2.next();
System.out.println(user);
}
}
控制台打印结果:
![]()
基于上述的内容,我们基本了解了avro的核心特性,以及如何使用avro实现简单的案例。本次的分享就到这里,受益的小伙伴或对大数据技术感兴趣的朋友不妨关注一下( • ̀ω•́ )✧

作者:Alice菌