python抓取页面文本及图片超链接
自定义标题目标网页[baidu]:一、爬取网页全部标签网址:1、按F12进入开发者模式查看HTML:2、分析HTML结构:3、代码如下:4、运行结果:二、爬取超链接文字及对应网址:优化代码如下:进一步优化方案:三、页面图片超链接:代码如下:
作者:yeyuanxiaoxin
这里用到第三方库:Beautiful Soup(一个可以从HTML或XML文件中提取数据的Python库)
目标网页[baidu]:
找到目标超链接标签位置,方法如下GIF
 我们找到的超链接信息如下:
我们找到的超链接信息如下:
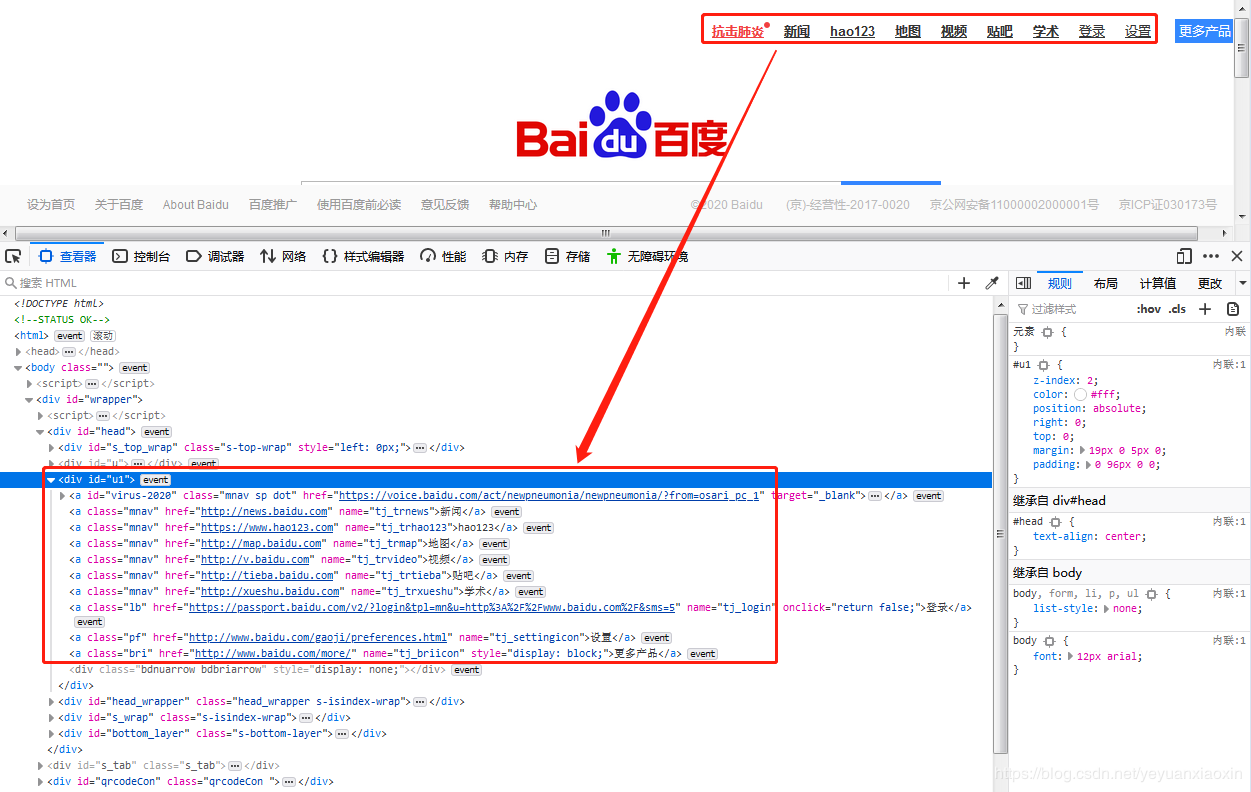
在HTML中,超链接用a表示,链接地址写作 href=“…”,格式如下:
新闻
import requests #获取网页
from bs4 import BeautifulSoup #解析网页
url = "https://www.baidu.com/"
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}
res= requests.get(url, headers=headers) #获取网页信息
soup = BeautifulSoup(res.text,'lxml') #将网页信息转换为文本并用bs库分析
soup_herf=soup.find_all("a") #查找全部超链接a的部分
for herf in soup_herf:
htlm = herf.get('href') #逐条提取soup_herf中超链接href的部分
print(htlm)
4、运行结果:
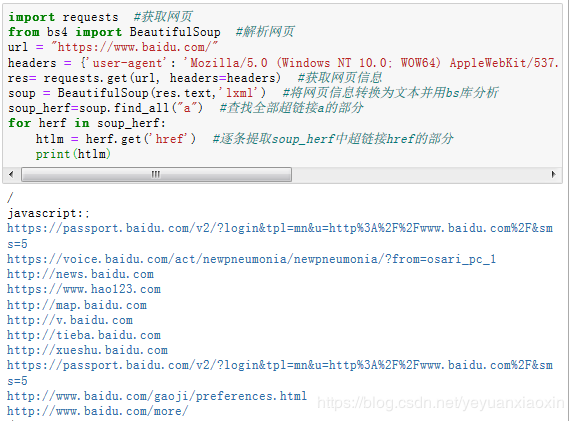
注意:这里我们只是将超链接地址提取了,但是对应标签并未提取,有时候可能会影响后续操作。这里我们继续优化!!!方法如下:
二、爬取超链接文字及对应网址:这里我们需要用到正则表达式对HTML文本中超链接标签内容进行处理
URL及其文本匹配(.*?)
import requests #获取网页
from bs4 import BeautifulSoup #解析网页
import re #正则表达式
url = "https://www.baidu.com/"
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}
res= requests.get(url, headers=headers)
#以下这两行以便python正确识别网页编码,以防乱码
encoding = chardet.detect(res.content)["encoding"]
res.encoding = encoding
link_list = re.findall(r'(.*?)', res.text, re.S|re.I)
for link in link_list:
http = link[1]+":"+urljoin(url, link[0]) #urljoin(url, link[0]) Url相对路径,改为绝对路径。
print(http)
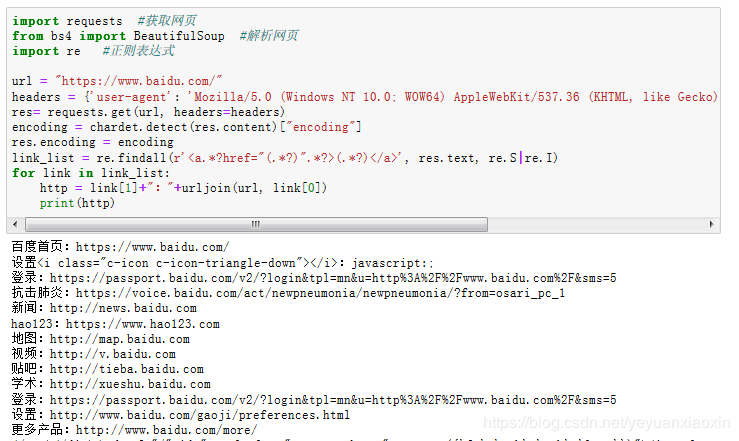
可直接点击进入结果中的超链接网址,参考博客Python基础代码爬取超链接文字及链接

html中图片的超链接设置与标签不同,src的值为网址链接,其结构为:
![]()
查找方法如下:
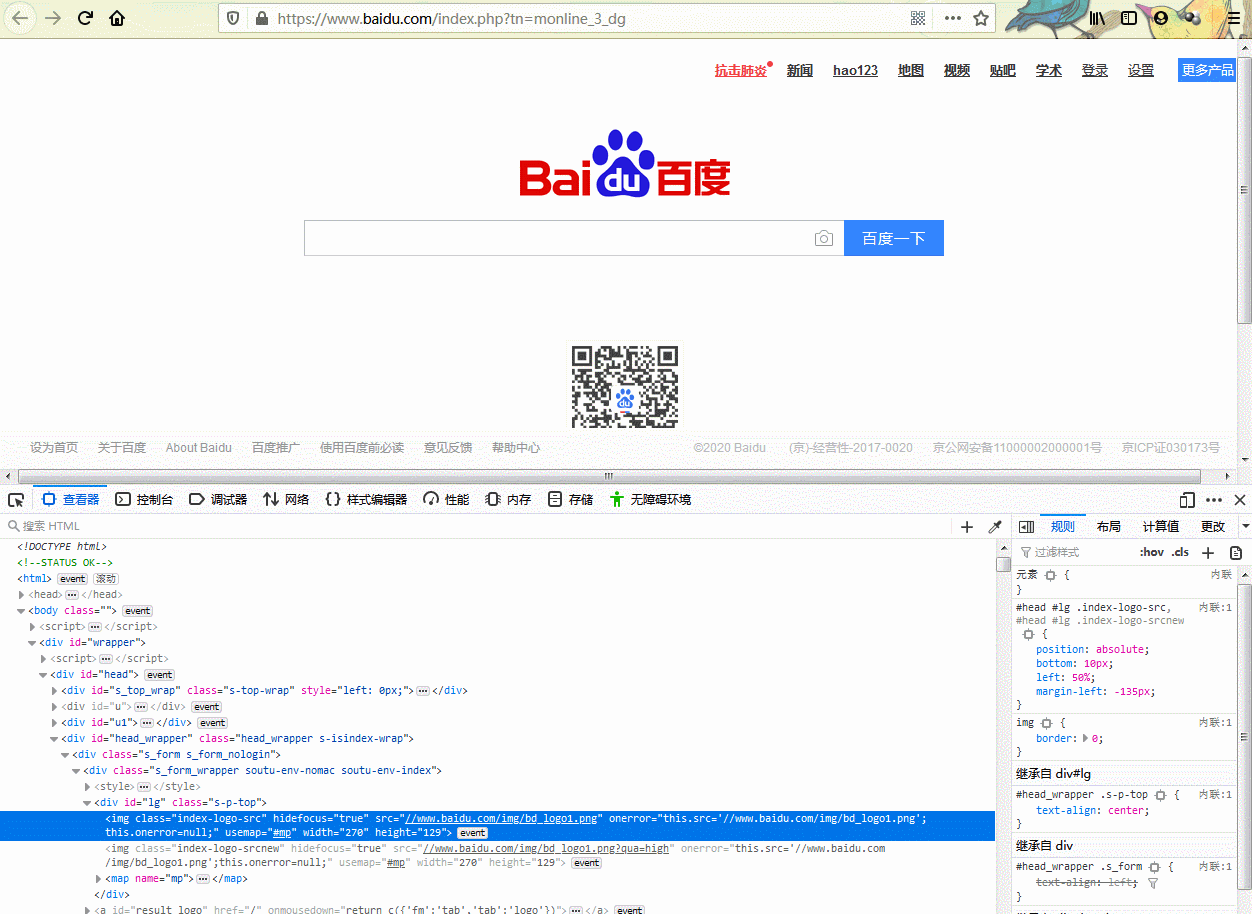
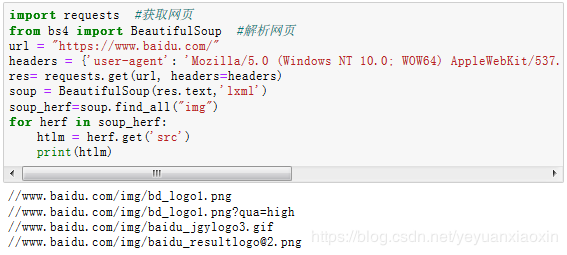
import requests #获取网页
from bs4 import BeautifulSoup #解析网页
url = "https://www.douban.com/"
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}
res= requests.get(url, headers=headers)
soup = BeautifulSoup(res.text,'lxml')
soup_herf=soup.find_all("img") #查找img图片标签
for herf in soup_herf:
htlm = herf.get('src') #逐个提取img标签中的src部分
print(htlm)
运行结果如下:
参考博客资料:
python3采集网页上所有的超链接URL及文本
Python 3 如何用BeautifulSoup抓取配套的超链接?
Python基础代码爬取超链接文字及链接
Python爬虫之解析网页
作者:yeyuanxiaoxin