产品经理算法篇——KNN
步骤 :
计算测试数据与各个训练数据之间的距离
按照距离递增排序
选取距离最小的k个点
确定前k个点所在类别的出现频率
返回前k个点出现频率最高的类别作为预测分类
试验:
0、数据引入
import numpy as np
import pandas as pd
#引入sklearn中的数据
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
#引入计算准确率公式
from sklearn.metrics import accuracy_score
iris = load_iris()
print(iris)
1、数据预处理
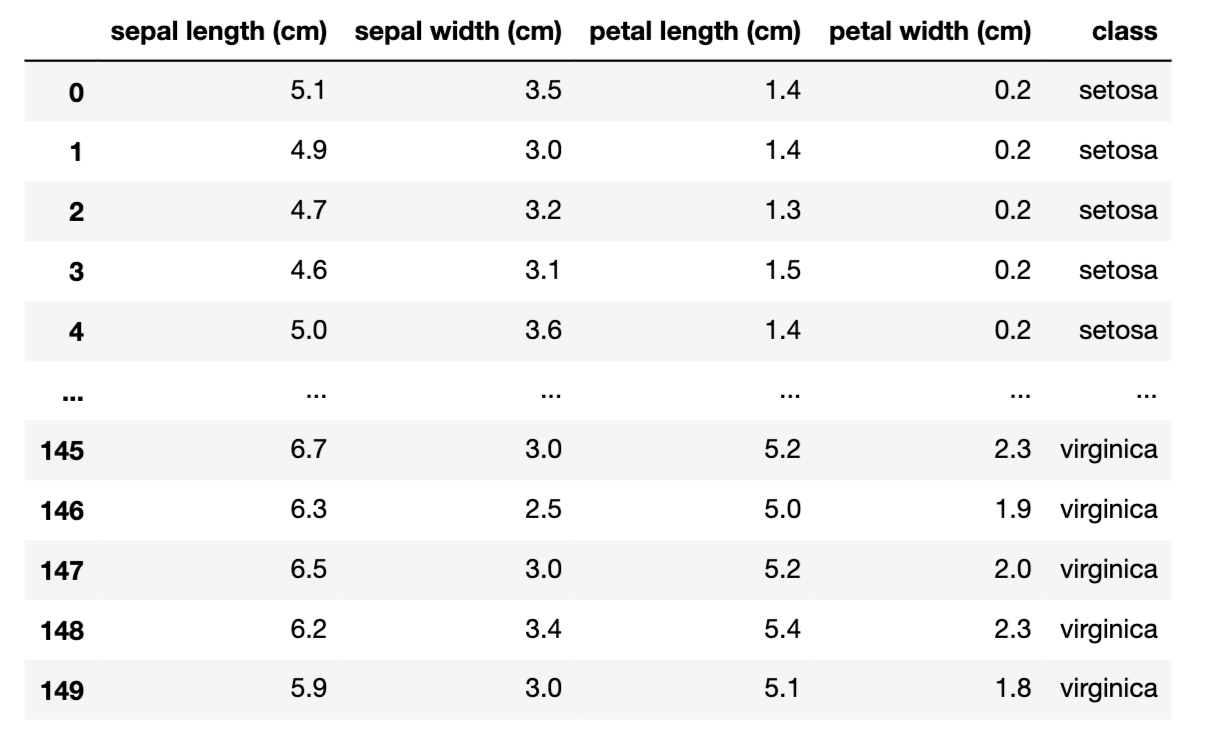
df = pd.DataFrame(data=iris.data,columns=iris.feature_names)
df['class'] = iris.target
#map映射为中文
df['class'] = df['class'].map({0:iris.target_names[0],1:iris.target_names[1],2:iris.target_names[2]})
x = iris.data
# 转变为列向量
y = iris.target.reshape(-1,1)
# 划分训练集、测试集,随机参数,stratify保证按照y的同等比例分布
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=35,stratify=y)
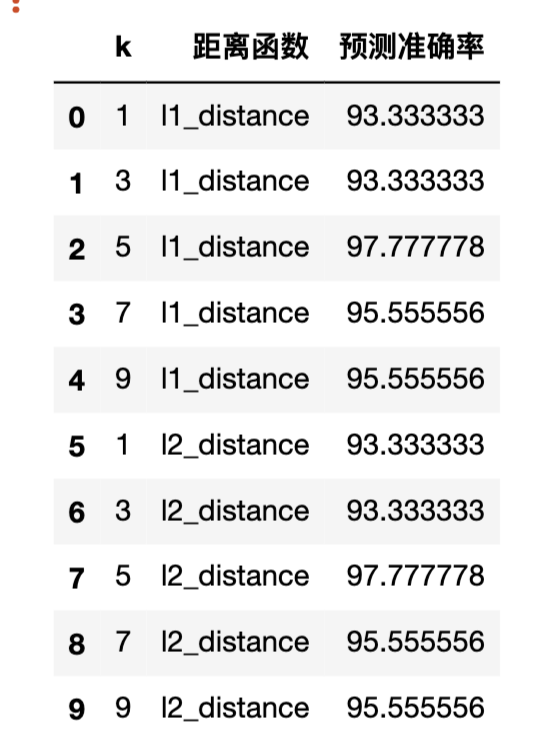
2、算法实现
曼哈顿距离:
查看专栏详情
立即解锁全部专栏
作者:卢梭~