Redis处理高并发之布隆过滤器详解
前言
缓存穿透、击穿、雪崩
缓存穿透
出现情况
常见的解决方案
缓存击穿
出现情况
解决方案
缓存雪崩
解决方案
布隆过滤器 Bloom filter
总结
前言随着我们业务开发越来越来大,并染请求就会越来越多,那么我们的项目的压力就会越来越大,基本都会使用缓存,除本地缓存,还会用到redis缓存,但是你以为使用缓存就没啥问题了么,那肯定不是的,使用了缓存又会出现新的问题,比如,缓存的key失效导致大量的请求到数据库,大量的读请求瞬间到达了数据库,cpu的使用率爆增,导致数据库都可能挂掉,这种情况下我们就要考虑使用redis的布隆过滤器了。
缓存穿透、击穿、雪崩首先我们从缓存会出现的几种问题,来进行分析,在高并发的场景下如果出现这种情况,我们应该如何解决。
正常情况下,我们的web应用会先去请求缓存服务,如果缓存命中,那么就去拿缓存里面的数据,返回结果给应用,

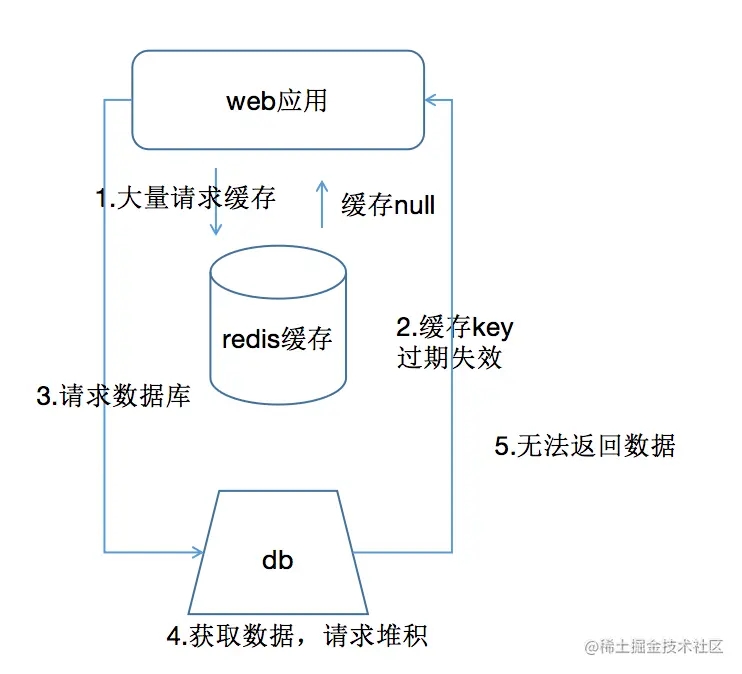
缓存穿透与缓存雪崩和缓存击穿还是不一样的,雪崩和击穿的情况下,数据库的数据都是真正常的,可以去请求数据库获取数据,只是缓存层出现问题,等待缓存恢复了,就会减轻数据库的压力。 而缓存透不一样的就是,缓存和数据库都没有要请求的数据,大量的请求来了,数据库的压力很大。

数据库数据被大量清除,导致访问不到
黑客恶意攻击
常见的解决方案redis缓存空值,请求不到的时候返回给应用空值。
使用布隆过滤器,把数据库的一部分数据hash到布隆过滤器里,在请求数据库之前先去布隆过滤器里筛选到一部分请求,判断数据是否存在,避免直接去访问数据库。
缓存击穿 出现情况大量热点数据库过期,导致无法从缓存获取到数据,大量请求数据库也无法返回书就
加锁,保证同一时间内,只允许有一个线程去更新缓存,等锁释放后在重新去请求缓存。
热点数据不去设置过期时间,如果要设置过期时间,在过期的时候通知后台去更新缓存的过期时间。
缓存雪崩大量缓存在同一时间失效,导致大量请求进入数据库
redis故障宕机,导致缓存不能使用。
解决方案同上加锁
给缓存的过期时间加入随机数,保证缓存不会在同一时间同时失效。
副本key策略,就是对于一个key,在它的基础上在设置一个key,它们的value都是一样的,只不过一个设置过期时间、一个不设置过期时间,相当于给key做了个副本,只不过在更新缓存的时候,副本key也是要更新的,避免出现数据不一致的现象。
布隆过滤器 Bloom filter前面提到过布隆过滤器在请求比较高的时候,可以帮助我们抵挡一部分请求,从而减轻数据库的压力,布隆过滤器的数据结构是一个二进制的bit向量,或者说是一个bit数组,它相对于list、set、map这些集合,它占用的空间更少,不足之处处就是返回的结果会有一定概率的误差。
public static void main(String[] args) {
int size = 1_000_000;
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
for (int i = 0; i < size; i++) {
if (!bloomFilter.mightContain(i)) {
System.out.println("有漏网之鱼");
}
}
List<Integer> list = new ArrayList<>(1000);
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("有误差的数量:" + list.size());
}
确实有误差的数量,但是误差量不大,追求效率的同时只是牺牲一点误差了。

加锁的排队的场景确实能帮助我们很好的解决缓存穿透、击穿的一些问题,但是效率也是非常低了,因为每个请求都是排队等待,如果可以接受轻微误差的话,布隆过滤器的确是个很不错的选择,Bloom filter的bitmap的存储效率确实很高。
以上就是Redis处理高并发之布隆过滤器详解的详细内容,更多关于Redis布隆过滤器处理高并发的资料请关注软件开发网其它相关文章!