编码处理问题总结:UnicodeDecodeError:'gbk' codec can't decode byte 0xe3: illegal multibyte sequence与读取docx
在试图打开docx文档内容时,以为可以向读取txt文档一样,于是写下了下面的代码
with open('C:\\Users\\Administrator\\Desktop\\案例二.docx','r')as f:
contents = f.read()
print(contents)
结果遇上报错:UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xe3 in position 55: illegal multibyte sequence

解决方法一:
一看,编码错误,祖传方法encoding='utf-8‘’百试百灵的修改
with open('C:\\Users\\Administrator\\Desktop\\案例二.docx','r',encoding='utf-8‘’)as f:
contents = f.read()
print(contents)
结果一样报错UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x87 in position 10: invalid start byte
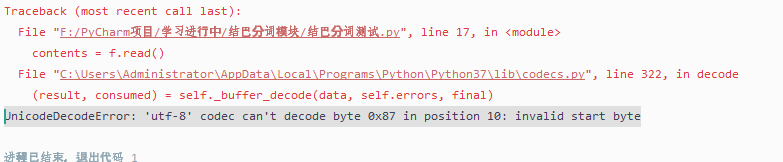
我就纳闷了,怎么还有 utf-8都解码不了,utf-8号称‘万国码’’(UTF-8编码:它是一种全国家通过的一种编码,如果网站涉及到多个国家的语言,那么建议选择UTF-8编码。),基本上用上它一切就ok了,怎么还报错。我就打了一个“你好”在里面啊!
但既然是编码错误,就继续。
之后按照这篇文章《UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xe9 in position 7581: illegal multibyte sequence》
一个一个换编码
gbk
gb2312
gb18030
utf-8
utf-16
utf-32
ISO-8859-1
都没有效果,
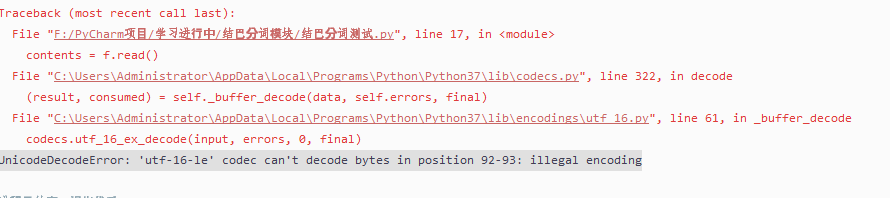
utf-16:UnicodeDecodeError: ‘utf-16-le’ codec can’t decode bytes in position 92-93: illegal encoding
ISO-8859-1:UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\x87’ in position 11: illegal multibyte sequence

都没有效果
解决方法二:
可能是不认识的编码。于是按照《使用chardet判断编码方式》使用chardet进行编码自动判断并调用
import chardet
def chardets():
path = 'C:\\Users\\Administrator\\Desktop\\案例二.docx'
with open(path, 'rb') as f:
#print(chardet.detect(f.read())['encoding'])
return chardet.detect(f.read())['encoding']
#chardets()
with open('C:\\Users\\Administrator\\Desktop\\案例二.docx','r', encoding=chardets())as f:
contents = f.read()
print(contents)
然而依然保错:UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xe3 in position 55: illegal multibyte sequence

看看是什么样的编码这样难以解决
print(chardet.detect(f.read())['encoding'])

怎么是None呢?
def chardets():
path = 'C:\\Users\\Administrator\\Desktop\\案例二.docx'
with open(path, 'rb') as f:
print(chardet.detect(f.read()))#chardet.detect()返回的是一个字典,所以之前需要[‘encoding’]获取编码方式
#return chardet.detect(f.read())['encoding']
chardets()
结果一样是None

于是我再次尝试了txt文件的读取,结果正常读取

但是有意思的是,其编码竟然是
{'encoding': 'TIS-620', 'confidence': 0.3598212120361634, 'language': 'Thai'}
这个编码从未见过,于是我想可能是文件中存在异常的编码(之前写入的不是“你好”这两个字符,而是一篇文章)
解决方法三:
编码解决不了,那就解决出现问题的编码,对之进行跳过。
增加errors=‘ignore’
import chardet
def chardets():
path = 'C:\\Users\\Administrator\\Desktop\\案例二.docx'
with open(path, 'rb') as f:
print(chardet.detect(f.read()))
return chardet.detect(f.read())['encoding']
#chardets()
with open('C:\\Users\\Administrator\\Desktop\\案例二.docx','r', encoding=chardets(), errors='ignore')as f:
contents = f.read()
print(contents)
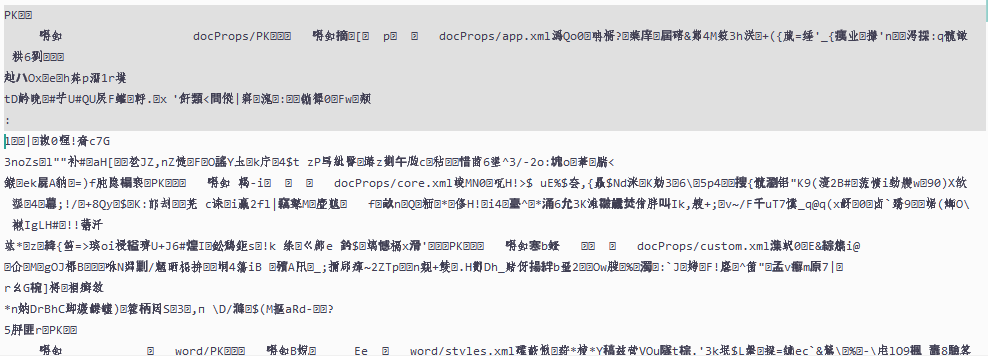
结果乱码
 原创文章 44获赞 28访问量 5万+
关注
私信
展开阅读全文
原创文章 44获赞 28访问量 5万+
关注
私信
展开阅读全文
作者:python__reported