Python3.8抓取百度图片高清原图『原来如此简单』『最新记录贴』
网上爬取百度图片的五花八门,要么有的过时的,有的则是爬取的是缩略图,不是原图等。
鉴于此在学习的过程中,记录此贴。在写本文的时候,代码是可用的。
1.首先要有第一个明白的地方是百度图片目前是动态页面,无法正常使用爬取元素标签的方式去抓取图片。
2.使用requests请求百度图片时,返回的响应体里原图的链接是加密的。(所以直接能取到或者看到的都是非原图)
3.我也只是个小白,学习的过程看到网上文章比较乱,所以特地记录此贴。有什么任何错误,欢迎指教,但别开喷,谢谢。
脚本使用的工具包有:
import json
import re
import time
from concurrent.futures.thread import ThreadPoolExecutor
import requests
其中requests 可以使用 pip install requests 安装,我使用的版本是 2.23.0。
代码本来是打算一步一步讲解,但是太浪费时间了。所以我选择注解代码的方式。希望大家能看得懂
# 储存所抓取到的原图链接
img_list = []
# 线程池,最大个数为150
pool = ThreadPoolExecutor(max_workers=int(150))
# 请求头
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36'}
# 百度图片请求链接
base_url = r"https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&" \
r"fp=result&queryWord={keyword}&cl=2&lm=-1&ie=utf-8&oe=utf-8&" \
r"adpicid=&st=&z=&ic=&hd=&latest=©right=&word={keyword}&s=&" \
r"se=&tab=&width=&height=&face=&istype=&qc=&nc=&fr=&expermode=&force=&pn={index}&rn=30&gsm=1e"
# 解密百度原图地址函数,来自网上,非常感谢。
def decode_url(url):
"""
对百度加密后的地址进行解码
:param url:百度加密的url
:return:解码后的url
"""
if not url:
return None
table = {'w': "a", 'k': "b", 'v': "c", '1': "d", 'j': "e", 'u': "f", '2': "g", 'i': "h",
't': "i", '3': "j", 'h': "k", 's': "l", '4': "m", 'g': "n", '5': "o", 'r': "p",
'q': "q", '6': "r", 'f': "s", 'p': "t", '7': "u", 'e': "v", 'o': "w", '8': "1",
'd': "2", 'n': "3", '9': "4", 'c': "5", 'm': "6", '0': "7",
'b': "8", 'l': "9", 'a': "0", '_z2C$q': ":", "_z&e3B": ".", 'AzdH3F': "/"}
url = re.sub(r'(?P_z2C\$q|_z\&e3B|AzdH3F+)', lambda matched: table.get(matched.group('value')), url)
return re.sub(r'(?P[0-9a-w])', lambda matched: table.get(matched.group('value')), url)
# 获取百度图片的函数
def get_img(get_index):
global img_list
# 构造一个完整的请求链接
get_url = base_url.format(keyword=search_key, index=get_index)
# 获得响应数据
get_response = requests.get(get_url, headers=headers).text
# 由于获得的响应数据是json类型,所以直接json格式化
json_data = json.loads(get_response, strict=False)
# 列表推导式,推导得到解密后的原图地址
url_list = [decode_url(data.get('objURL')) for data in json_data.get('data')]
# 这一步是删了列表里最后一个元素,原因是因为百度返回的每一条数据里永远会多一个空的数据,所以将他删除
if len(url_list) >= 1:
del url_list[len(url_list) - 1]
# 将这个原图网址的列表 放到img_list里
img_list += url_list
print("当前图片数量: %d" % len(img_list))
print("总用时:%s" % (time.time() - start))
search_key = input("请输入想搜索照片的关键词:")
# 构造一个完整的请求链接
full_url = base_url.format(keyword=search_key, index=0)
# 获得响应数据
response = requests.get(full_url, headers=headers).text
# 由于获得的响应数据是json类型,所以直接json格式化
json_list = json.loads(response, strict=False)
# list_num是百度返回数据里告诉我们搜索图片的总量
list_num = int(json_list.get('listNum'))
# 计时
start = time.time()
# 通过对list_num处理,来决定需要请求多少次,每次的图片数量是30.之所以是30是因为百度网页每次请求时默认是30条数据,所以我采用了默认值。
for index in range(0, list_num, 30):
# 开启一个线程处理请求和数据
t = pool.submit(get_img, index)
文章里我只输出了【图片总量】和【总用时】,所有原图链接储存在img_list里,如果需要看到连接,可以直接输出,或者写到文件里,这里我就不写了。
成果展示我自己输出的结果
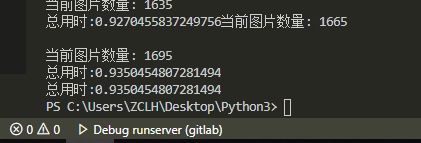
1695张图片,用时不到1秒,还可以了。
 十年后的八月见
十年后的八月见
 原创文章 3获赞 2访问量 3236
关注
私信
展开阅读全文
原创文章 3获赞 2访问量 3236
关注
私信
展开阅读全文
作者:十年后的八月见