Python爬取百度搜索结果(标题,摘要,链接)
近期想要爬取百度搜索的结果,网上的教程一直没有找到可以直接用的,尝试了几个小时终于摸索出了可以用的代码。
主要的问题在于 url 的形式,之前的教程一般是这种形式:
url = 'https://www.baidu.com/s?' + word + '&pn=0' # word为搜索关键词,pn用来分页
由于百度每个页面显示10条结果,'&pn=n' 表示第 n 条结果,n = 0~9 表示第一页,n = 10~19 表示第二页,以此类推。然而在运行代码时发现这种形式的 url 从第二页开始就无法正常爬取了。关于 url 格式我一直没有搞清楚,但是我摸索出了一种方法能得到可用的 url;
首先按照上面那个 url 形式,比如要搜索“咖啡”,则将 'word' 改为 "咖啡": https://www.baidu.com/s?咖啡&pn=0 并复制到浏览器, 如下图,这是搜索“咖啡”以后的第一页: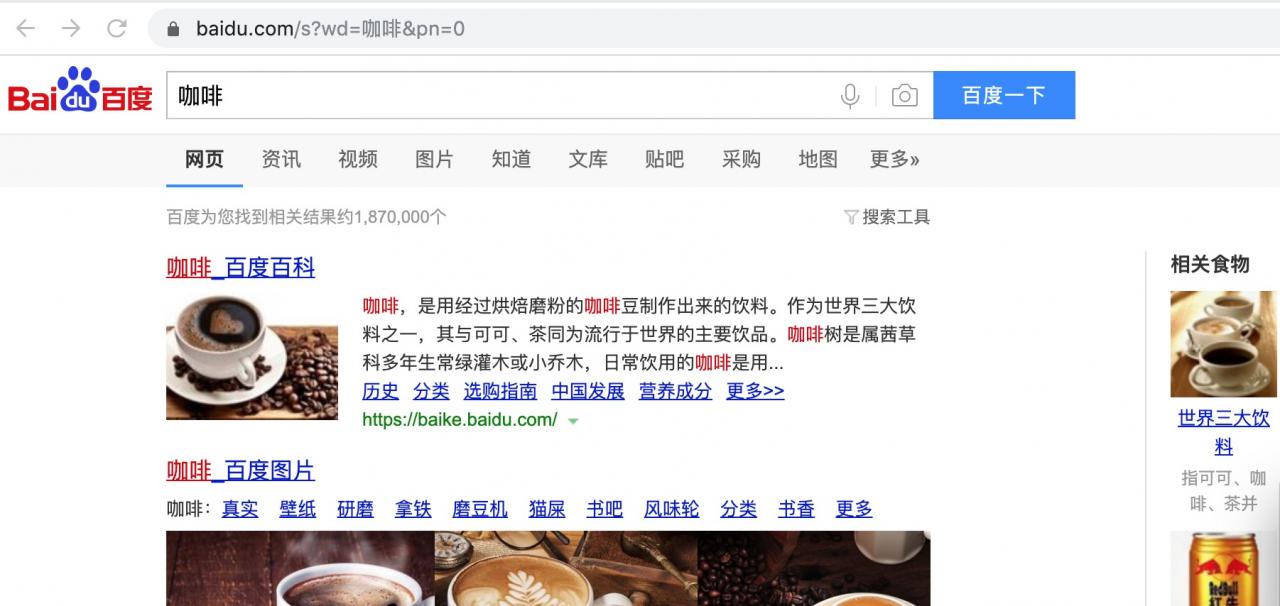
然后点击下方页码,打开第二页:

下图为搜索“咖啡”结果的第二页,可以看到上方 url 地址出现 '&pn=10';
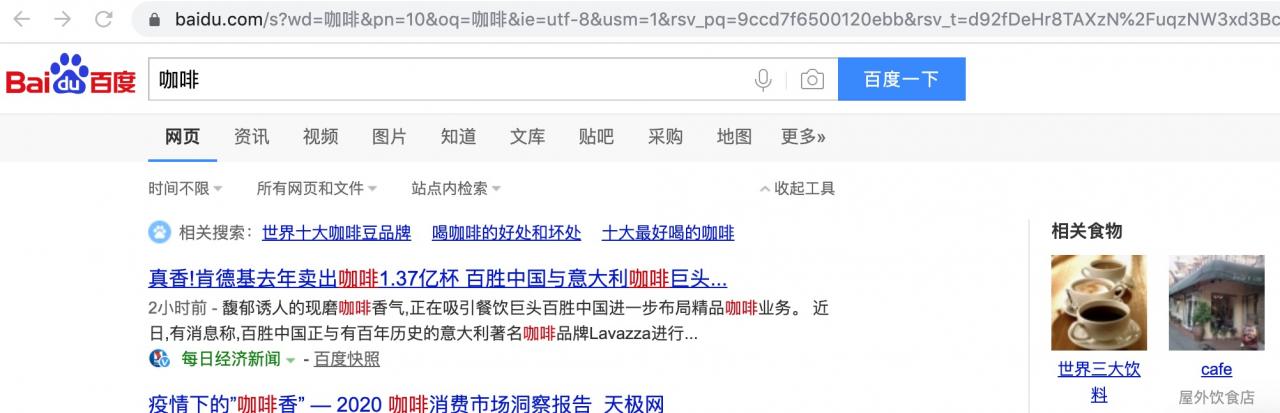
复制此地址作为我们的搜索 url,形式如下(复制以后中文“咖啡”两字被自动编码了):
url = 'https://www.baidu.com/s?wd=%E5%92%96%E5%95%A1&pn='+ number +'&oq=%E5%92%96%E5%95%A1&ie=utf-8&usm=1&rsv_pq=9ccd7f6500120ebb&rsv_t=d92fDeHr8TAXzN%2FuqzNW3xd3BcU3lunThKY2lkUUobFc3Ihjx46MPW4iNbc'
以下是全部代码:
import time
from bs4 import BeautifulSoup #处理抓到的页面
import sys
import requests
import re
import importlib
importlib.reload(sys)#编码转换,python3默认utf-8,一般不用加
#ff = open('test.txt', 'w')
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件
def getfromBaidu():
start = time.clock()
for k in range(1, 3):
geturl(k)
end = time.clock()
print(end-start)
def geturl(k):
number = str((k - 1) * 10)
path = 'https://www.baidu.com/s?wd=%E5%92%96%E5%95%A1&pn=' + number + '&oq=%E5%92%96%E5%95%A1&ie=utf-8&usm=1&rsv_pq=9ccd7f6500120ebb&rsv_t=d92fDeHr8TAXzN%2FuqzNW3xd3BcU3lunThKY2lkUUobFc3Ihjx46MPW4iNbc'
#print(path)
content = requests.get(path,headers=headers)
#使用BeautifulSoup解析html
soup = BeautifulSoup(content.text,'html.parser')
tagh3 = soup.find_all('div', { 'class', 'result c-container '})
#print(tagh3)
for h3 in tagh3:
try:
title = h3.find(name = "h3", attrs = { "class": re.compile( "t")}).find('a').text.replace("\"","")
print(title)
#ff.write(title+'\n')
except:
title = ''
try:
abstract = h3.find(name = "div", attrs = { "class": re.compile( "c-abstract")}).text.replace("\"","")
print(abstract)
#ff.write(abstract+'\n')
except:
abstract = ''
try:
url = h3.find(name = "a", attrs = { "class": re.compile( "c-showurl")}).get('href')
print(url+'\n')
#ff.write(url+'\n')
except:
url = ''
#ff.write('\n')
if __name__ == '__main__':
getfromBaidu()
爬取结果如下:

作者:CCchaha