Java实习生面试复习(三):ArrayList
我是一名很普通的双非大三学生,跟很多同学一样,有着一颗想进大厂的梦。接下来的几个月内,我将坚持写博客,输出知识的同时巩固自己的基础,记录自己的成长和锻炼自己,备战2021暑期实习面试!奥利给!!
ArrayList 我们几乎每天都会使用到,本文就一起来看看同样是面试高频问到的ArrayList的相关知识吧。
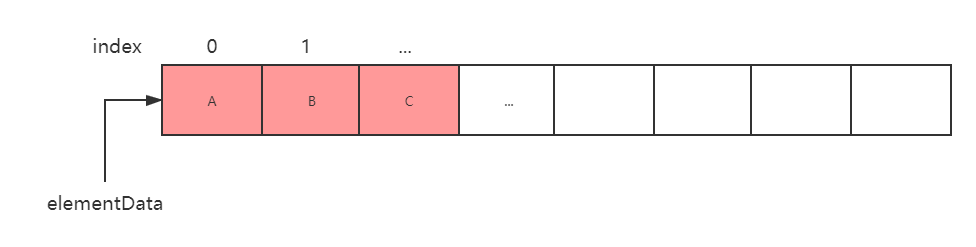
ArrayList分析 底层结构分析其实ArrayList是很简单的, ArrayList 其实就是围绕底层数组结构,各个 API 都是对数组的操作进行封装,看下图:
//默认数组大小10
private static final int DEFAULT_CAPACITY = 10;
//数组使用的大小
private int size;
//数组存放的容器
transient Object[] elementData; // non-private to simplify nested class access
图中展示是长度为 8 的数组(为了画图方便,其实默认是10),长度从 1 开始计数,index 表示数组的下标,从 0 开始计数,elementData 表示数组本身。
源码中除了这两个概念,还有以下三个基本概念:
DEFAULT_CAPACITY 表示数组的初始大小,默认是 10,这个数字要记住; size 表示当前数组的大小,类型 int,没有使用 volatile 修饰,非线程安全的; modCount 统计当前数组被修改的版本次数,数组结构有变动,就会 +1。modCount继承自AbstractList,主要应用快速失败机制,在上一篇HashMap中有提到这个机制,这里就不在赘述了
三种初始化办法:无参数直接初始化、指定大小初始化、指定初始数据初始化
// 无参数构造器,默认是空数组
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
// 指定大小初始化
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
// 指定初始数据初始化
public ArrayList(Collection c) {
//elementData 是保存数组的容器,默认为 null
elementData = c.toArray();
//如果给定的集合(c)数据有值,则进行拷贝赋值操作
if ((size = elementData.length) != 0) {
//如果集合元素类型不是 Object 类型,才开始拷贝,否则不执行
if (elementData.getClass() != Object[].class) {
elementData = Arrays.copyOf(elementData, size, Object[].class);
}
} else {
// 给定集合(c)无值,则默认空数组
this.elementData = EMPTY_ELEMENTDATA;
}
}
注意:ArrayList 无参构造器初始化时,默认大小是空数组,跟HashMap一样,都是在第一次 add 的时候扩容的数组值。
新增和扩容实现新增的代码其实很简短
// 添加到数组尾部
public boolean add(E e) {
//确保数组大小足够,不够需要扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
//直接赋值,线程不安全的
elementData[size++] = e;
return true;
}
// 添加到指定位置
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
/**
* @param src the source array. 源数组
* @param srcPos starting position in the source array. 源数组的起始位置
* @param dest the destination array. 目标数组
* @param destPos starting position in the destination data. 目标数组的起始位置
* @param length the number of array elements to be copied. 复制的长度
*/
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
我们可以看到两个add方法,我们来分析一下这两个方法:
添加到数组尾部 时间复杂度O(1):
添加到指定位置 时间复杂度O(n):
rangeCheckForAdd 先判断下标是否正确 ensureCapacityInternal 判断是否需要扩容 arraycopy 将原数组从下标开始的数据全部往后移一位 给指定下标的位置赋值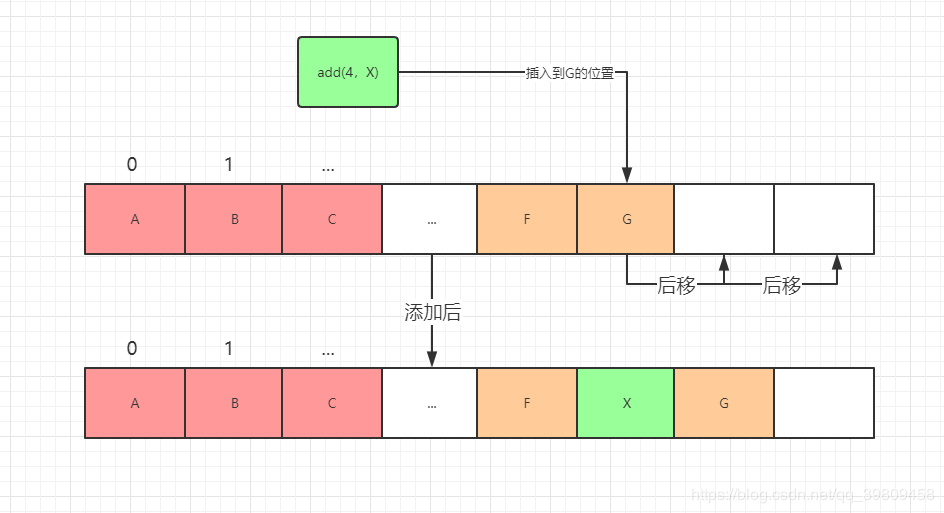
// 扩容
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
// oldCapacity >> 1 是把 oldCapacity / (2 ^ 1) 的意思
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 如果扩容后的值 < 我们的期望值,扩容后的值就等于我们的期望值
if (newCapacity - minCapacity jvm 所能分配的数组的最大值,那么就去 Integer 的最大值
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 通过复制进行扩容 底层实际上还是System.arraycopy方法
elementData = Arrays.copyOf(elementData, newCapacity);
}
我们可以看到扩容是通过这行代码来实现的:Arrays.copyOf(elementData, newCapacity);,这行代码指的就是数组之间的拷贝,扩容是会先新建一个预期容量的新数组,然后把老数组的数据拷贝过去,底层还是System.arraycopy 方法进行拷贝,此方法是 native 的方法
这里需要注意:扩容的规则是原来容量大小 + 容量大小的一半,也就是原来容量的 1.5 倍;ArrayList 中的数组的最大值是 Integer.MAX_VALUE。且 ArrayList 是允许 null 值的。
ArrayList 删除元素有很多种方式,比如根据数组索引删除、根据值删除或批量删除等等,原理和思路都差不多,我们选取根据值和下标删除方式来进行说明:
//根据数组下标去删除
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // 方便GC,防止造成内存溢出
return oldValue;
}
// 按值删除
public boolean remove(Object o) {
// 如果要删除的值是 null,找到第一个值是 null 的删除
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
// 如果要删除的值不为 null,找到第一个和要删除的值相等的删除
for (int index = 0; index < size; index++)
// 这里是根据 equals 来判断值相等的,相等后再根据索引位置进行删除
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
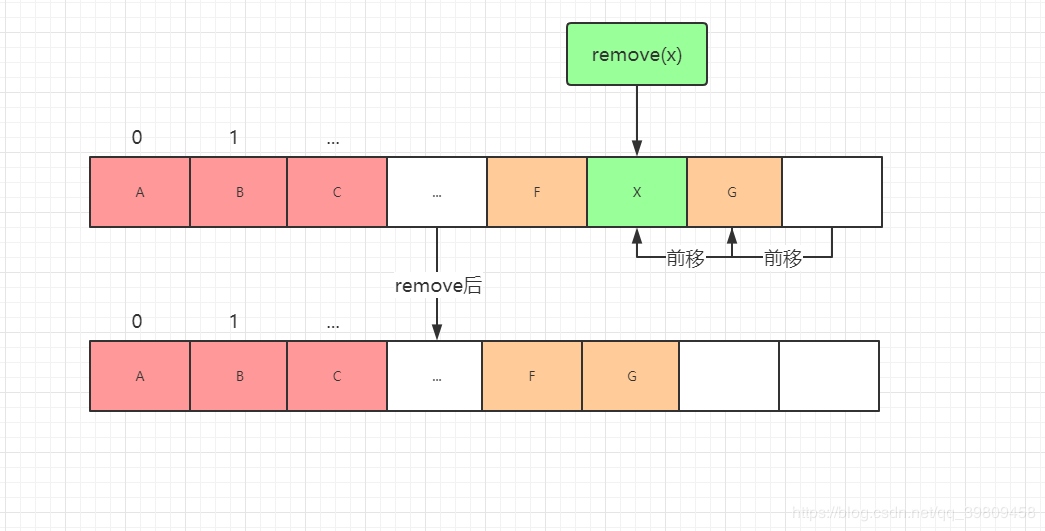
我们需要注意的是:
总结:
我们可以看出其实新增和删除都涉及到了数组的复制,这也是为什么ArrayList适合查找,LinkedList适合新增删改,但是如果是直接添加到数组尾部的话,还是很快的。但是这是有条件的,也就是我们不指定位置直接添加元素时(add(E element)),元素会默认会添加在最后,不会触发底层数组的复制,不考虑底层数组自动扩容的话,时间复杂度为O(1) ,在指定位置添加元素(add(int index, E element)),需要复制底层数组,根据最坏打算,时间复杂度是O(n)。
我们都知道所有集合都是Collection接口的实现类,又因为Collection继承了Iterable接口,因此所有集合都是可迭代的。我们常常会采用集合的迭代器来遍历集合元素,我们来看看ArrayList对迭代器的实现,从而深入分析为什么对集合执行相关修改操作时为什么会抛出ConcurrentModificationException。
// 实现 Iterator 接口
private class Itr implements Iterator {
// 迭代过程中,下一个元素的位置,从 0 开始,用来控制拿下一个元素
int cursor;
// 新增时表示上一次迭代过程中,索引的位置,删除成功时为 -1
int lastRet = -1;
// 迭代过程中期望数组修改版本号
int expectedModCount = modCount;
public boolean hasNext() {...}
public E next() {
//迭代过程中,判断版本号有无被修改,有被修改,抛 ConcurrentModificationException 异常
checkForComodification();
... 省略代码
// 返回元素值
return (E) elementData[lastRet = i];
}
public void remove() {
//迭代过程中,判断版本号有无被修改,有被修改,抛 ConcurrentModificationException 异常
checkForComodification();
try {
// 调用自身的remove
ArrayList.this.remove(lastRet);
... 省略代码
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
// 对比迭代器的删除,你发现了什么?
public E remove(int index) {
... 省略代码
modCount++;
... 省略代码
return oldValue;
}
该迭代器实现了Iterator接口并实现了相关方法,提供我们对集合的遍历能力。
总结:ArrayList的迭代器默认是其内部类实现,实现一个自定义迭代器只需要实现Iterator接口并实现相关方法即可。而实现Iterable接口表示该实现类具有像for-each loop迭代遍历的能力。
我们都知道,如果在迭代的过程中调用非迭代器内部的remove或者clear方法将会抛出ConcurrentModificationException异常,那到底是为什么呢?
首先这里涉及到两个很重要的变量,一个是expectedModCount,另一个是modCount,expectedModCount在集合内部迭代器中定义,就像上面源码所示,modCount在AbstractList中定义。,默认迭代器初始化的时候expectedModCount = modCount说明两者是相等的,我们可以看到next方法和remove方法都会去判断,只有当不相等的情况下才会抛出异常。我们可以看到ArrayList自身的remove方法在删除元素的时候会将modCount++,虽然迭代器本质上也是this.remove,但它在删除之后执行了一行expectedModCount = modCount,以此保证了两个值的相等,这也是java.util下的集合类的快速失败机制的实现。
总结:
迭代器迭代集合时不能对被迭代集合进行修改,原因是modCount和expectedModCount两个变量值不想等导致的!如果想删除需要调用Iterator.remove (),另外快速失败机制并不能保证ArrayList是线程安全的。
作者:南街nanjie