深入解读Android的Volley库的功能结构
Volley 是一个 HTTP 库,它能够帮助 Android app 更方便地执行网络操作,最重要的是,它更快速高效。我们可以通过开源的 AOSP 仓库获取到 Volley 。
Volley 有如下的优点:
Volley 擅长执行用来显示 UI 的 RPC 类型操作,例如获取搜索结果的数据。它轻松的整合了任何协议,并输出操作结果的数据,可以是原始的字符串,也可以是图片,或者是 JSON。通过提供内置的我们可能使用到的功能,Volley 可以使得我们免去重复编写样板代码,使我们可以把关注点放在 app 的功能逻辑上。
Volley 不适合用来下载大的数据文件。因为 Volley 会保持在解析的过程中所有的响应。对于下载大量的数据操作,请考虑使用 DownloadManager。
Volley 框架的核心代码是托管在 AOSP 仓库的 frameworks/volley 中,相关的工具放在 toolbox 下。把 Volley 添加到项目中最简便的方法是 Clone 仓库,然后把它设置为一个 library project:
通过下面的命令来Clone仓库:
git clone https://android.googlesource.com/platform/frameworks/volley
以一个 Android library project 的方式导入下载的源代码到你的项目中。
下面我们就来剖析一下Volley的Java源码:
RequestQueue
使用 Volley 的时候,需要先获得一个 RequestQueue 对象。它用于添加各种请求任务,通常是调用 Volly.newRequestQueue() 方法获取一个默认的 RequestQueue。我们就从这个方法开始,下面是它的源码:
public static RequestQueue newRequestQueue(Context context) {
return newRequestQueue(context, null);
}
public static RequestQueue newRequestQueue(Context context, HttpStack stack) {
File cacheDir = new File(context.getCacheDir(), DEFAULT_CACHE_DIR);
String userAgent = "volley/0";
try {
String packageName = context.getPackageName();
PackageInfo info = context.getPackageManager().getPackageInfo(packageName, 0);
userAgent = packageName + "/" + info.versionCode;
} catch (NameNotFoundException e) {
}
if (stack == null) {
if (Build.VERSION.SDK_INT >= 9) {
stack = new HurlStack();
} else {
// Prior to Gingerbread, HttpUrlConnection was unreliable.
// See: http://android-developers.blogspot.com/2011/09/androids-http-clients.html
stack = new HttpClientStack(AndroidHttpClient.newInstance(userAgent));
}
}
Network network = new BasicNetwork(stack);
RequestQueue queue = new RequestQueue(new DiskBasedCache(cacheDir), network);
queue.start();
return queue;
}
newRequestQueue(context) 调用了它的重载方法 newRequestQueue(context,null)。在这个方法中,先是通过 context 获得了缓存目录并且构建了 userAgent 信息。接着判断 stack 是否为空,从上面的调用可以知道,默认情况下 stack==null, 所以新建一个 stack 对象。根据系统版本不同,在版本号大于 9 时,stack 为 HurlStack,否则为 HttpClientStack。它们的区别是,HurlStack 使用 HttpUrlConnection 进行网络通信,而 HttpClientStack 使用 HttpClient。有了 stack 后,用它创建了一个 BasicNetWork 对象,可以猜到它是用来处理网络请求任务的。紧接着,新建了一个 RequestQueue,这也是最终返回给我们的请求队列。这个 RequestQueue 接受两个参数,第一个是 DiskBasedCache 对象,从名字就可以看出这是用于硬盘缓存的,并且缓存目录就是方法一开始取得的 cacheDir;第二个参数是刚刚创建的 network 对象。最后调用 queue.start() 启动请求队列。
在分析 start() 之前,先来了解一下 RequestQueue 一些关键的内部变量以及构造方法:
//重复的请求将加入这个集合
private final Map<String, Queue<Request>> mWaitingRequests =
new HashMap<String, Queue<Request>>();
//所有正在处理的请求任务的集合
private final Set<Request> mCurrentRequests = new HashSet<Request>();
//缓存任务的队列
private final PriorityBlockingQueue<Request> mCacheQueue =
new PriorityBlockingQueue<Request>();
//网络请求队列
private final PriorityBlockingQueue<Request> mNetworkQueue =
new PriorityBlockingQueue<Request>();
//默认线程池大小
private static final int DEFAULT_NETWORK_THREAD_POOL_SIZE = 4;
//用于响应数据的存储与获取
private final Cache mCache;
//用于网络请求
private final Network mNetwork;
//用于分发响应数据
private final ResponseDelivery mDelivery;
//网络请求调度
private NetworkDispatcher[] mDispatchers;
//缓存调度
private CacheDispatcher mCacheDispatcher;
public RequestQueue(Cache cache, Network network) {
this(cache, network, DEFAULT_NETWORK_THREAD_POOL_SIZE);
}
public RequestQueue(Cache cache, Network network, int threadPoolSize) {
this(cache, network, threadPoolSize,
new ExecutorDelivery(new Handler(Looper.getMainLooper())));
}
public RequestQueue(Cache cache, Network network, int threadPoolSize,
ResponseDelivery delivery) {
mCache = cache;
mNetwork = network;
mDispatchers = new NetworkDispatcher[threadPoolSize];
mDelivery = delivery;
}
RequestQueue 有多个构造方法,最终都会调用最后一个。在这个方法中,mCache 和 mNetWork 分别设置为 newRequestQueue 中传来的 DiskBasedCache 和 BasicNetWork。mDispatchers 为网络请求调度器的数组,默认大小 4 (DEFAULT_NETWORK_THREAD_POOL_SIZE)。mDelivery 设置为 new ExecutorDelivery(new Handler(Looper.getMainLooper())),它用于响应数据的传递,后面会具体介绍。可以看出,其实我们可以自己定制一个 RequestQueue 而不一定要用默认的 newRequestQueue。
下面就来看看 start() 方法是如何启动请求队列的:
public void start() {
stop(); // Make sure any currently running dispatchers are stopped.
// Create the cache dispatcher and start it.
mCacheDispatcher = new CacheDispatcher(mCacheQueue, mNetworkQueue, mCache, mDelivery);
mCacheDispatcher.start();
// Create network dispatchers (and corresponding threads) up to the pool size.
for (int i = 0; i < mDispatchers.length; i++) {
NetworkDispatcher networkDispatcher = new NetworkDispatcher(mNetworkQueue, mNetwork,
mCache, mDelivery);
mDispatchers[i] = networkDispatcher;
networkDispatcher.start();
}
}
代码比较简单,就做了两件事。第一,创建并且启动一个 CacheDispatcher。第二,创建并启动四个 NetworkDispatcher。所谓的启动请求队列就是把任务交给缓存调度器和网络请求调度器处理。
这里还有个问题,请求任务是怎么加入请求队列的?其实就是调用了 add() 方法。现在看看它内部怎么处理的:
public Request add(Request request) {
// Tag the request as belonging to this queue and add it to the set of current requests.
request.setRequestQueue(this);
synchronized (mCurrentRequests) {
mCurrentRequests.add(request);
}
// Process requests in the order they are added.
request.setSequence(getSequenceNumber());
request.addMarker("add-to-queue");
// If the request is uncacheable, skip the cache queue and go straight to the network.
if (!request.shouldCache()) {
mNetworkQueue.add(request);
return request;
}
// Insert request into stage if there's already a request with the same cache key in flight.
synchronized (mWaitingRequests) {
String cacheKey = request.getCacheKey();
if (mWaitingRequests.containsKey(cacheKey)) {
// There is already a request in flight. Queue up.
Queue<Request> stagedRequests = mWaitingRequests.get(cacheKey);
if (stagedRequests == null) {
stagedRequests = new LinkedList<Request>();
}
stagedRequests.add(request);
mWaitingRequests.put(cacheKey, stagedRequests);
if (VolleyLog.DEBUG) {
VolleyLog.v("Request for cacheKey=%s is in flight, putting on hold.", cacheKey);
}
} else {
// Insert 'null' queue for this cacheKey, indicating there is now a request in
// flight.
mWaitingRequests.put(cacheKey, null);
mCacheQueue.add(request);
}
return request;
}
}
这个方法的代码稍微有点长,但逻辑并不复杂。首先把这个任务加入 mCurrentRequests,然后判断是否需要缓存,不需要的话就直接加入网络请求任务队列 mNetworkQueue 然后返回。默认所有任务都需要缓存,可以调用 setShouldCache(boolean shouldCache) 来更改设置。所有需要缓存的都会加入缓存任务队列 mCacheQueue。不过先要判断 mWaitingRequests 是不是已经有了,避免重复的请求。
Dispatcher
RequestQueue 调用 start() 之后,请求任务就被交给 CacheDispatcher 和 NetworkDispatcher 处理了。它们都继承自 Thread,其实就是后台工作线程,分别负责从缓存和网络获取数据。
CacheDispatcher
CacheDispatcher 不断从 mCacheQueue 取出任务处理,下面是它的 run() 方法:
public void run() {
if (DEBUG) VolleyLog.v("start new dispatcher");
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
// Make a blocking call to initialize the cache.
mCache.initialize();
while (true) {
try {
// Get a request from the cache triage queue, blocking until
// at least one is available. 取出缓存队列的任务
final Request request = mCacheQueue.take();
request.addMarker("cache-queue-take");
// If the request has been canceled, don't bother dispatching it.
if (request.isCanceled()) {
request.finish("cache-discard-canceled");
continue;
}
// Attempt to retrieve this item from cache.
Cache.Entry entry = mCache.get(request.getCacheKey());
if (entry == null) {
request.addMarker("cache-miss");
// Cache miss; send off to the network dispatcher.
mNetworkQueue.put(request);
continue;
}
// If it is completely expired, just send it to the network.
if (entry.isExpired()) {
request.addMarker("cache-hit-expired");
request.setCacheEntry(entry);
mNetworkQueue.put(request);
continue;
}
// We have a cache hit; parse its data for delivery back to the request.
request.addMarker("cache-hit");
Response<?> response = request.parseNetworkResponse(
new NetworkResponse(entry.data, entry.responseHeaders));
request.addMarker("cache-hit-parsed");
if (!entry.refreshNeeded()) {
// Completely unexpired cache hit. Just deliver the response.
mDelivery.postResponse(request, response);
} else {
// Soft-expired cache hit. We can deliver the cached response,
// but we need to also send the request to the network for
// refreshing.
request.addMarker("cache-hit-refresh-needed");
request.setCacheEntry(entry);
// Mark the response as intermediate.
response.intermediate = true;
// Post the intermediate response back to the user and have
// the delivery then forward the request along to the network.
mDelivery.postResponse(request, response, new Runnable() {
@Override
public void run() {
try {
mNetworkQueue.put(request);
} catch (InterruptedException e) {
// Not much we can do about this.
}
}
});
}
} catch (InterruptedException e) {
// We may have been interrupted because it was time to quit.
if (mQuit) {
return;
}
continue;
}
}
}
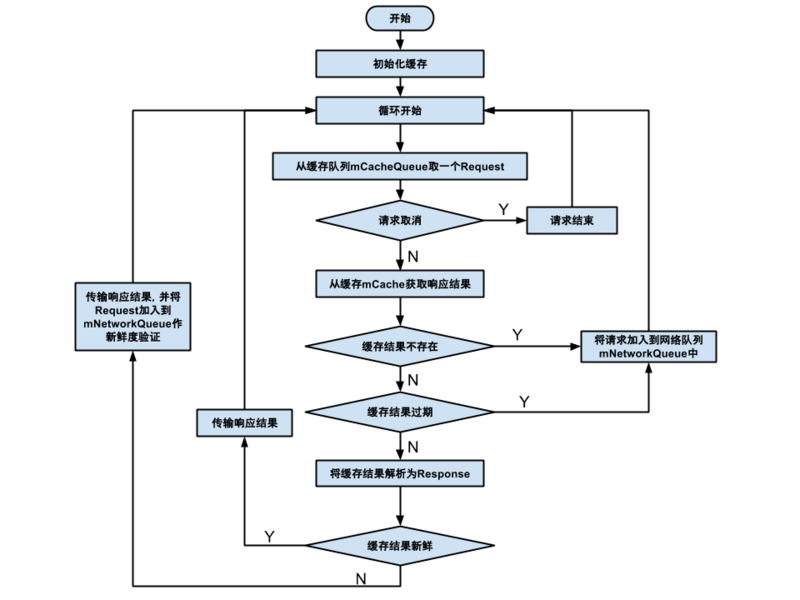
首先是调用 mCache.initialize() 初始化缓存,然后是一个 while(true) 死循环。在循环中,取出缓存队列的任务。先判断任务是否取消,如果是就执行 request.finish("cache-discard-canceled") 然后跳过下面的代码重新开始循环,否则从缓存中找这个任务是否有缓存数据。如果缓存数据不存在,把任务加入网络请求队列,并且跳过下面的代码重新开始循环。如果找到了缓存,就判断是否过期,过期的还是要加入网络请求队列,否则调用 request 的parseNetworkResponse 解析响应数据。最后一步是判断缓存数据的新鲜度,不需要刷新新鲜度的直接调用 mDelivery.postResponse(request, response) 传递响应数据,否则依然要加入 mNetworkQueue 进行新鲜度验证。
上面的代码逻辑其实不是很复杂,但描述起来比较绕,下面这张图可以帮助理解:
NetworkDispatcher
CacheDispatcher 从缓存中寻找任务的响应数据,如果任务没有缓存或者缓存失效就要交给 NetworkDispatcher 处理了。它不断从网络请求任务队列中取出任务执行。下面是它的 run() 方法:
public void run() {
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
Request request;
while (true) {
try {
// Take a request from the queue.
request = mQueue.take();
} catch (InterruptedException e) {
// We may have been interrupted because it was time to quit.
if (mQuit) {
return;
}
continue;
}
try {
request.addMarker("network-queue-take");
// If the request was cancelled already, do not perform the
// network request.
if (request.isCanceled()) {
request.finish("network-discard-cancelled");
continue;
}
// Tag the request (if API >= 14)
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.ICE_CREAM_SANDWICH) {
TrafficStats.setThreadStatsTag(request.getTrafficStatsTag());
}
// Perform the network request. 发送网络请求
NetworkResponse networkResponse = mNetwork.performRequest(request);
request.addMarker("network-http-complete");
// If the server returned 304 AND we delivered a response already,
// we're done -- don't deliver a second identical response.
if (networkResponse.notModified && request.hasHadResponseDelivered()) {
request.finish("not-modified");
continue;
}
// Parse the response here on the worker thread.
Response<?> response = request.parseNetworkResponse(networkResponse);
request.addMarker("network-parse-complete");
// Write to cache if applicable.
// TODO: Only update cache metadata instead of entire record for 304s.
if (request.shouldCache() && response.cacheEntry != null) {
mCache.put(request.getCacheKey(), response.cacheEntry);
request.addMarker("network-cache-written");
}
// Post the response back.
request.markDelivered();
mDelivery.postResponse(request, response);
} catch (VolleyError volleyError) {
parseAndDeliverNetworkError(request, volleyError);
} catch (Exception e) {
VolleyLog.e(e, "Unhandled exception %s", e.toString());
mDelivery.postError(request, new VolleyError(e));
}
}
}
可以看出,run() 方法里面依然是个无限循环。从队列中取出一个任务,然后判断任务是否取消。如果没有取消就调用 mNetwork.performRequest(request) 获取响应数据。如果数据是 304 响应并且已经有这个任务的数据传递,说明这是 CacheDispatcher 中验证新鲜度的请求并且不需要刷新新鲜度,所以跳过下面的代码重新开始循环。否则继续下一步,解析响应数据,看看数据是不是要缓存。最后调用 mDelivery.postResponse(request, response) 传递响应数据。下面这张图展示了这个方法的流程:
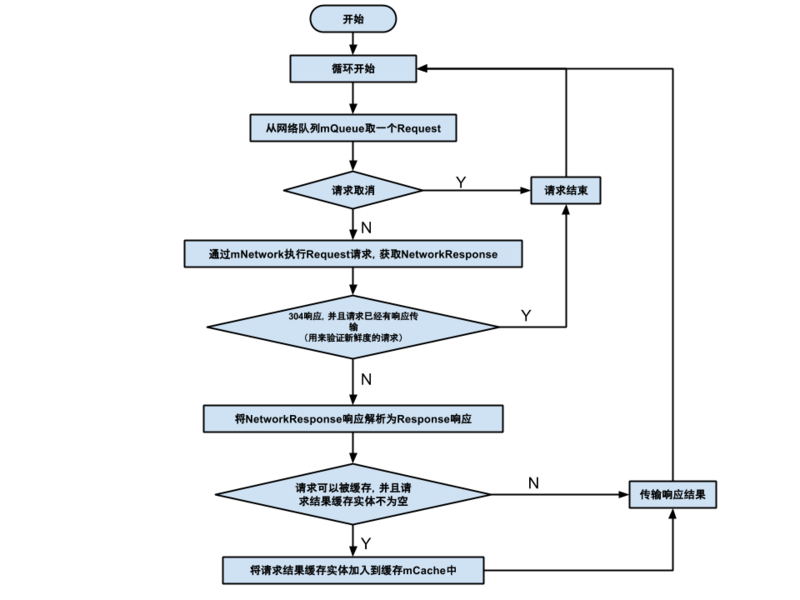
Delivery
在 CacheDispatcher 和 NetworkDispatcher 中,获得任务的数据之后都是通过 mDelivery.postResponse(request, response) 传递数据。我们知道 Dispatcher 是另开的线程,所以必须把它们获取的数据通过某种方法传递到主线程,来看看 Deliver 是怎么做的。
mDelivery 的类型为 ExecutorDelivery,下面是它的 postResponse 方法源码:
public void postResponse(Request<?> request, Response<?> response) {
postResponse(request, response, null);
}
public void postResponse(Request<?> request, Response<?> response, Runnable runnable) {
request.markDelivered();
request.addMarker("post-response");
mResponsePoster.execute(new ResponseDeliveryRunnable(request, response, runnable));
}
从上面的代码可以看出,最终是通过调用 mResponsePoster.execute(new ResponseDeliveryRunnable(request, response, runnable)) 进行数据传递。这里的 mResponsePoster 是一个 Executor 对象。
private final Executor mResponsePoster;
public ExecutorDelivery(final Handler handler) {
// Make an Executor that just wraps the handler.
mResponsePoster = new Executor() {
@Override
public void execute(Runnable command) {
handler.post(command);
}
};
Executor 是线程池框架接口,里面只有一个 execute() 方法,mResponsePoster 的这个方法实现为用 handler 传递 Runnable 对象。而在 postResponse 方法中,request 和 response 被封装为 ResponseDeliveryRunnable, 它正是一个 Runnable 对象。所以响应数据就是通过 handler 传递的,那么这个 handler 是哪里来的?其实在介绍 RequestQueue 的时候已经提到了:mDelivery 设置为 new ExecutorDelivery(new Handler(Looper.getMainLooper())),这个 handler 便是 new Handler(Looper.getMainLooper()),是与主线程的消息循环连接在一起的,这样数据便成功传递到主线程了。
总结
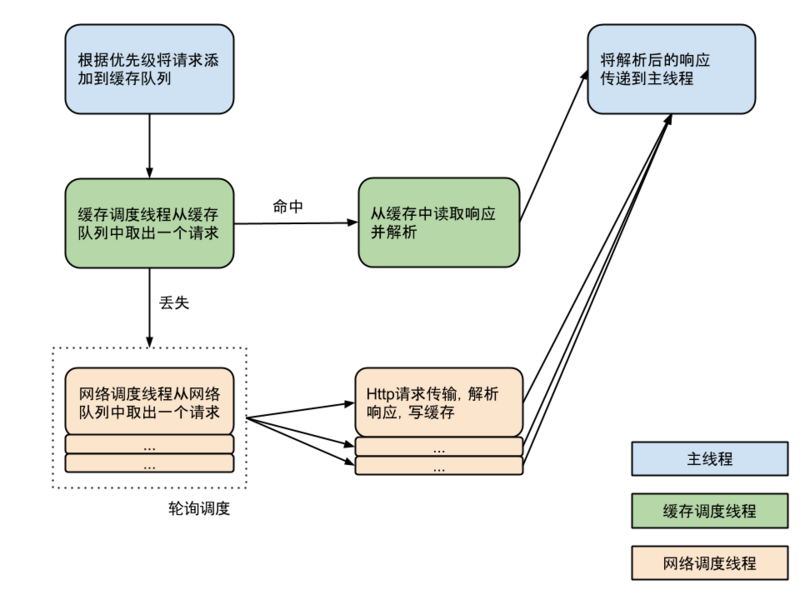
Volley 的基本工作原理就是这样,用一张图总结一下它的运行流程: