02/17/2020 Stanford- CS231-note Loss functions and optimization
a loss function tells how good our current classifier is
You tell your algorithm what kind of errors you care about and what kind of errors you trade off against
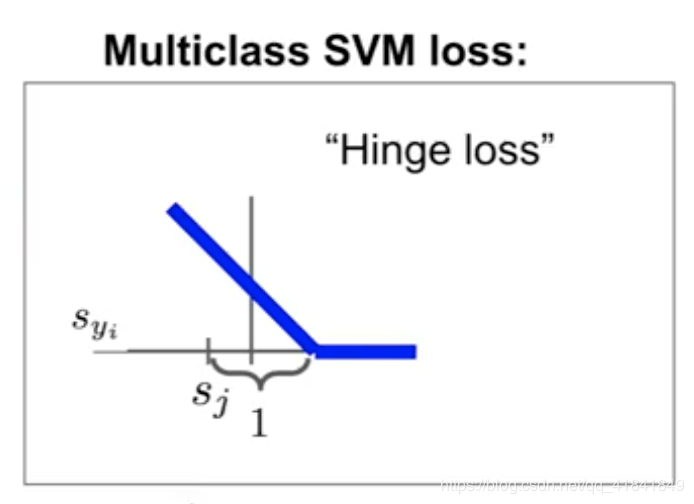
Multi-class SVM loss
- - j could be the number of classes our dataset have
- j could be the number of classes our dataset have
-syi - the score of the true class/ s- predicted scores come out from prediction
-if true score is not high enough to be greater than any of the other scores, incur some loss
-why 1 here? we only care about the relative differences between the scores,you will find 1 doesn’t matter if you rescale w, the free parameter of 1 washes out and is canceled with this overall scale in w
-hinge loss (according to shape)
ex (include all bad predictions)


Q: at initialization W is small so all s=.0, what is the loss?
A: number of classes minus one (useful for debug)
what if the sum was over all classes?