Neural Machine Translation by Jointly Learning to Align and Translate阅读笔记
| 论文原文 | Neural Machine Translation by Jointly Learning to Align and Translate |
|---|---|
| 论文信息 | ICLR2015 |
| 个人解读 | Wang Anna & Hytn Chen |
| 更新时间 | 2020-02-13 |
1980,基于规则的翻译,大致流程就是输入,词性分析,词典查询,语序调整,输出。
1990,基于统计的翻译,为翻译过程建立概率模型,引入隐变量,构造隐变量对数线性模型,设计特征函数,例如2002年学者Och和Ney所提出的模型
P(y∣x;θ)=∑zexp(θ⋅ϕ(x,y,z))∑y′∑z′exp(θ⋅ϕ(x,y′,z′))
P(\mathbf{y} | \mathbf{x} ; \boldsymbol{\theta})=\sum_{\mathbf{z}} \frac{\exp (\boldsymbol{\theta} \cdot \boldsymbol{\phi}(\mathbf{x}, \mathbf{y}, \mathbf{z}))}{\sum_{\mathbf{y}^{\prime}} \sum_{\mathbf{z}^{\prime}} \exp \left(\boldsymbol{\theta} \cdot \phi\left(\mathbf{x}, \mathbf{y}^{\prime}, \mathbf{z}^{\prime}\right)\right)}
P(y∣x;θ)=z∑∑y′∑z′exp(θ⋅ϕ(x,y′,z′))exp(θ⋅ϕ(x,y,z))
其中x是已知的源语言,y是目标语言,z就是隐变量。
2013,基于神经网络的翻译,这就是现今主流使用的方法,2014年由Kyunghyun Cho和Sutskever先后提出了一种端到端的模型,直接对源语句和目标语句建立联系,前者将其模型命名为Encoder-Decoder模型,后者将其模型命名为Sequence-to-Sequence模型
P(y∣x;θ)=∏n=1NP(yn∣x,y<n;θ)
P(\mathbf{y} | \mathbf{x} ; \boldsymbol{\theta})=\prod_{n=1}^{N} P\left(\mathbf{y}_{n} | \mathbf{x}, \mathbf{y}<n ; \boldsymbol{\theta}\right)
P(y∣x;θ)=n=1∏NP(yn∣x,y<n;θ)
这里n代表目标语言中待预测的第n个词,在此之前的n-1个词都已经预测完毕。模型的目标就是对这样的条件概率概率建模,找到一组合适的参数θ\thetaθ,使得模型逼近真实语境。
相对经典的做法就是采用RNN系列结构,对源语言进行编码,然后再将编码过后的信息进行解码得到目标语言,编码器和解码器都是需要训练的。这个方法的缺点就是,对于任意长度的句子都需要编码为固定维度的向量,不仅造成了信息的丢失,在解码的时候越到后面其依据信息就可能越弱。
针对这个问题,就引入了注意力机制,该篇论文是最早将注意力机制引入机器翻译的论文。
论文整体框架 摘要论文摘要可分为如下四个部分:
神经机器翻译的任务定义;
概括现阶段神经机器翻译方法,指出Encoder-Decoder模型的缺陷,造成信息丢失;
引入本文提出的自动搜索原句中与预测目标词相关的神经机器翻译模型;
讲述所提出模型的效果。
传统模型怎么做神经网络的作用就是直接学习前文公式中的条件概率分布,通过学习大量的成对语料,找到输入和输出之间的关系,这就是端到端模型的基本思想,本文所采用的baseline就是Encoder-Decoder模型,模型名称RNNenc,出自文章Learning phrase representations using RNN encoder-decoder for statistical machine translation。
RNNenc的工程流程是这样的,首先源语言一句话,每个词都用词向量表示,之后使用RNN循环地将输入的序列压缩成一个固定维度的向量,直到所有词输入完毕,生成源语言下一句话的向量表示c。
c作为输入,输入到解码器中,再用RNN循环地将目标语言下的单词序列压缩成一个固定维度的向量,和目标语言单词一起压缩的还有前一时刻的隐层状态,前一时刻的预测单词,用公式表示为:
st=f(c,yt−1,st−1)
s_{t}=f\left(c, y_{t-1}, s_{t-1}\right)
st=f(c,yt−1,st−1)
模型直观结构图为:
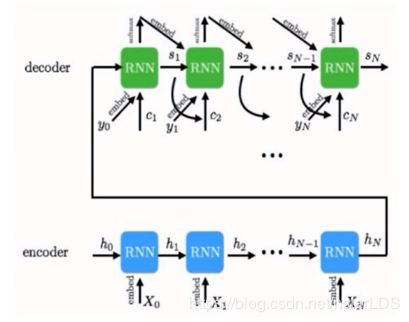
模型提出后有学者对其效果进行了可视化验证,证实模型确实将语义相近的句子嵌入进了语义空间中相近的地方,而在机器翻译领域Seq2Seq模型在英法翻译任务中达到了当时的SOTA。
传统模型缺点限制了翻译过程中长句子的表示;离得越近的词对当前神经网络隐层状态的影响越大;不能有针对性侧重性地抓取句中词的信息。
论文主要贡献提出一种新的神经机器翻译模型RNNsearch模型
编码器:采用双向LSTM,隐层状态同时对当前单词前面和后面的信息进行编码
解码器:提出一种注意力模型,对输入的隐层状态求权重
RNNsearch模型传统模型RNNenc的做法是将整个输入语句编码成一个固定长度的向量,使用的是单向循环神经网络RNN。而RNNsearch模型将输入的句子编码为一个变长的向量序列,在解码翻译时,自适应的选择这些向量的子集,使用的是双向LSTM。
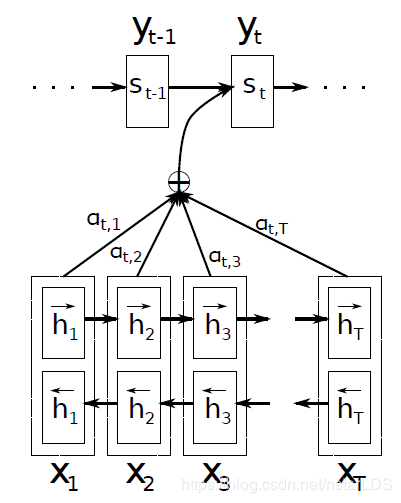
公式概括如下:
st=f(ct,yt−1,st−1)
s_{t}=f\left(c_t, y_{t-1}, s_{t-1}\right)
st=f(ct,yt−1,st−1)
也就是说对于目标语言的每个单词的隐层状态,都由前一单词隐层状态,前一预测得出的单词,以及经过注意力提取后的源语言语义信息共同决定。其中注意力层的权重由softmax得到。
数据集是WMT14数据集(从英语翻译成法语),词表大小是3000,分别取最大长度为30和最大长度为50的句子长度进行实验。
评测标准Bleu:其具体公式如下

而RNNsearch的模型效果如下:
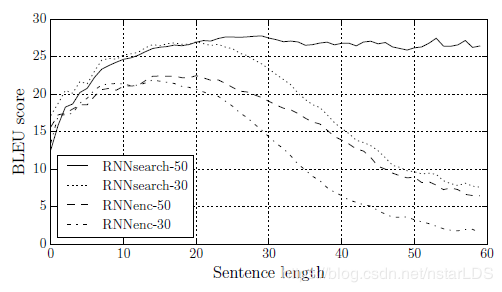
可见,在长度50的句子上模型效果很平稳,BeLU score比之前的模型效果都有提升。
与该篇工作密切相关的论文有Luong在2015年发表的Effective approached to attention-based neural machine translation,论文回答了三个问题:
注意力机制能提升多少性能?(使用不同的注意力机制计算会得到不同的结果)
双向LSTM能提升多少性能?(使用单向LSTM和使用注意力分数效果对比)
注意力分数的其他计算方法?(论文提出其他的注意力分数的计算方法)
作者:Nstar-LDS